

Data movement remains a perennial obstacle in systems design. Many talented architects and engineers spend significant amounts of time working on data movement, often in the form of batch Extract, Transform, and Load (ETL). In general, batch ETL is the process everyone loves to hate, or put another way, I’ve never met an engineer happy with their batch ETL setup.
In this post, we’ll look at the shift from batch to real time, the new topologies required to keep up with data flows, and the messaging semantics required to be successful in the enterprise.
The Trouble with Data Movement
There is an adage in computing that the best operations are the ones you do not have to do. Such is the thinking with data movement. Less is more.
Today a large portion of time spent on data movement still revolves around batch processes, with data transferred at a periodic basis between one system and the next. However, Gartner states,
Familiar data integration patterns centered on physical data movement (bulk/batch data movement, for example) are no longer a sufficient solution for enabling a digital business.
And this comical Twitter message reflects the growing disdain for a batch oriented approach…
I hate batch processing so much that I won’t even use the dishwasher.
I just wash, dry, and put away real time.— Ed Weissman (@edw519) November 6, 2015
There are a couple of ways to make batch processing go away. One involves moving to robust database systems that can process both transactions and analytics simultaneously, essentially eliminating the ETL process for applications.
Another way to reduce the time spent on batch processing is to shift to real-time workflows. While this does not change the amount of data going through the system, moving from batch to real-time helps normalize compute cycles, mitigate traffic surges, and provides timely, fresh data to drive business value. If executed well this initiative can also reduce the time data engineers spend moving data.
The Enterprise Streaming Opportunity
Most of the discussion regarding streaming today is happening in areas like the Internet of Things, sensors, web logs and mobile applications. But that is really just the tip of the iceberg.
A much larger enterprise opportunity involves taking so much of the batch processing that is embedded into business processes and turning that into real-time workflows.
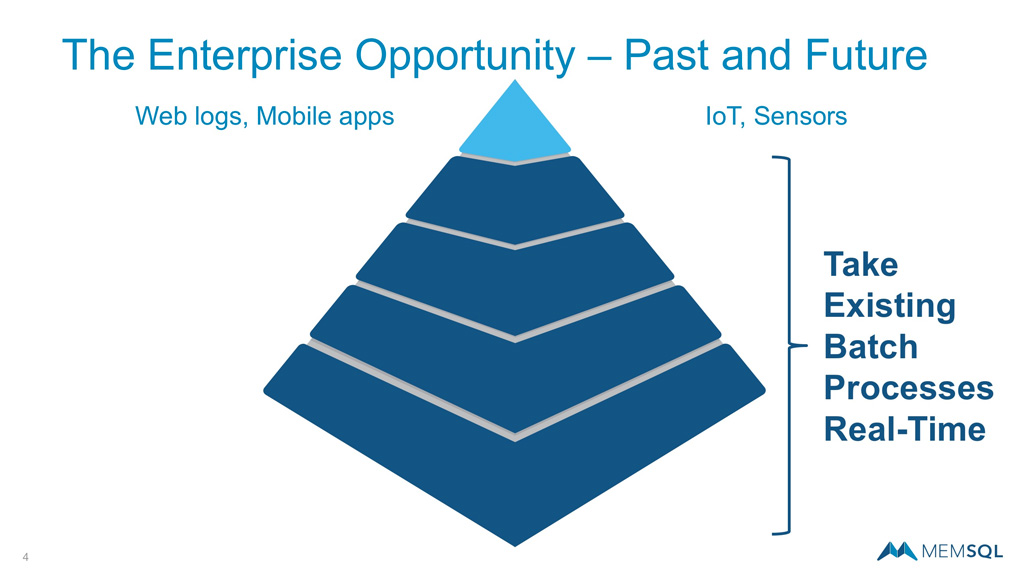
Of course, streaming does not need to mean everything is happening instantly down to the microsecond. In the context of the enterprise, it might just mean moving to continuous data motion, where batch processes are converted into real-time streams to drive insights for critical applications, such as improving customer experiences. Compared to some of the new application development underway, there are still large untapped opportunities of taking existing batch processes real time.
Overall, the holy grail for data movement architects is linear scalability. More specifically if you double your hardware and have double the data load, you will double your throughput while maintaining low latency.
Charting New Ground With Distributed Data Movement
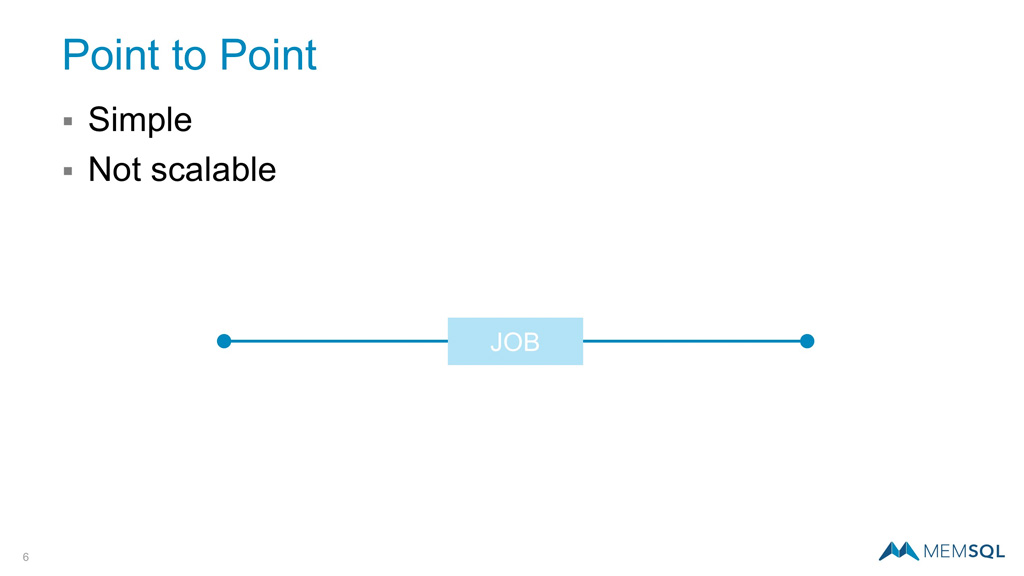
It helps to take a look at where we have been, and where we are heading with topologies for data movement. Starting from the early days of single server systems, and unfortunately still frequently in use, is the original point-to-point topology. While this approach is beneficial in simplicity, it’s single threaded nature makes it slow and difficult to scale.
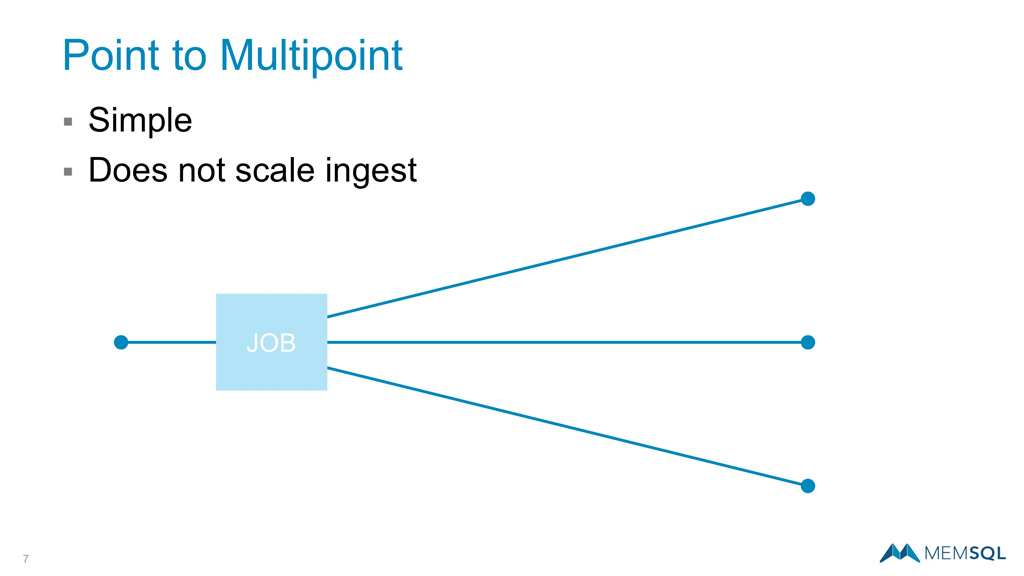
With the emergence of distributed systems, we’ve seen an expansion of data movement topologies. Point to multipoint is a next step in allowing for more performance. However, since one side of the equation is based on a single node, the performance is capped by the performance of that node.
The source can be distributed too, allowing us to achieve even more with multipoint to multipoint communication. However, not every implementation of this topology is ideal. For example, in the following diagram, each individual node in the origin system on the left is communicating an independent point-to-multipoint job. Since there is no coordination, the jobs compete for resources and scaling in limited.
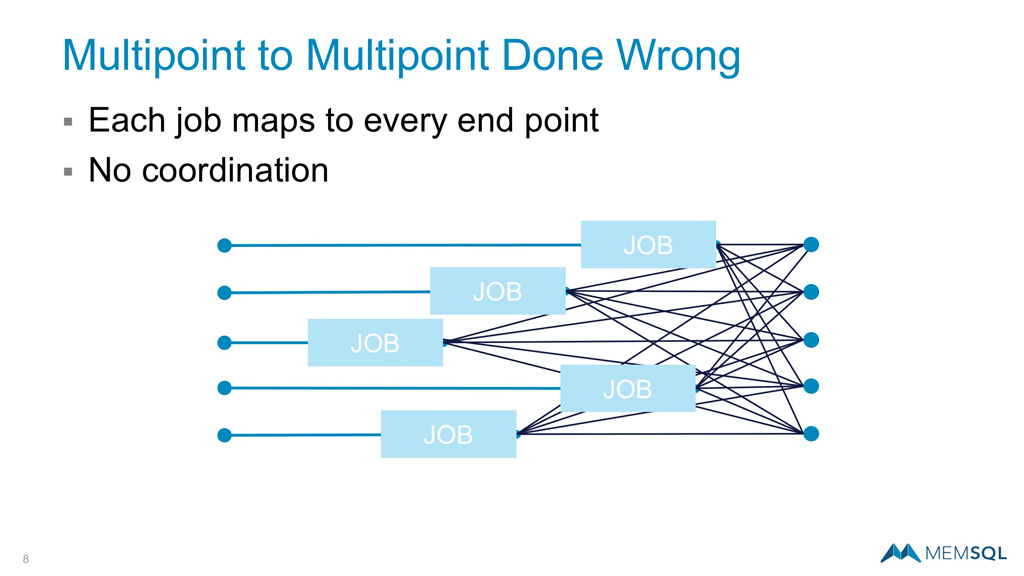
A far more elegant solution is to retain multipoint to multipoint communication but managed as a single job. This is the architecture behind SingleStore Pipelines, where multiple paths are managed as one. This does require the exact same amount of data reshuffling on the receiving nodes, but this happens once all of the data has been staged in the receiving system and can therefore be handled easily. With this architecture if you double your hardware and double your data, you will double your throughput.
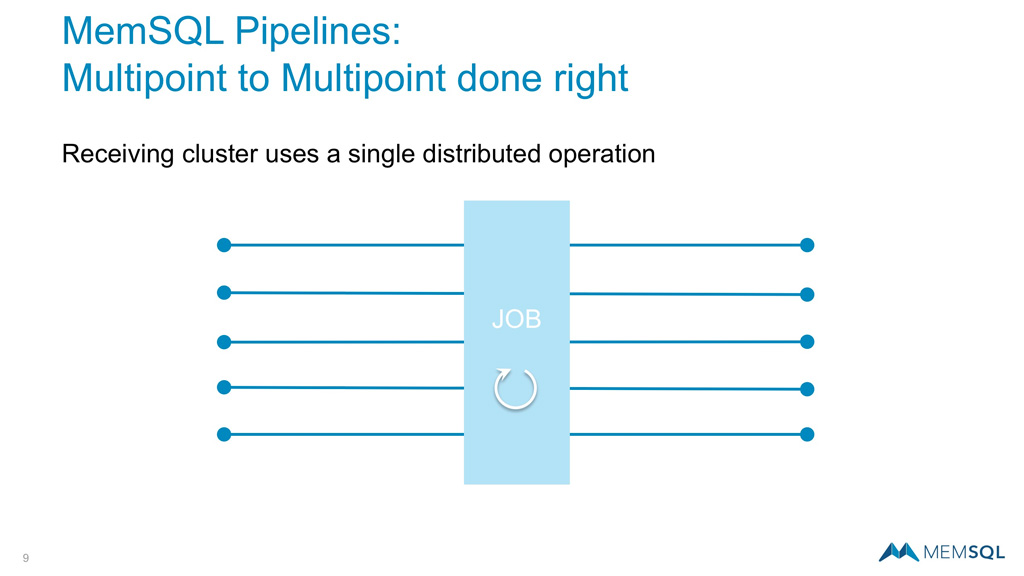
Building A Robust Streaming Foundation
Distributed systems and multipoint to multipoint data movement represent a step change in scalability of performance. However, this alone will not solve all the needs for enterprise workloads. Unlike sensor data or web logs, enterprise information generally relies on more robust and resilient systems to guarantee data integrity and delivery.
One of the reasons batch processing has been prevalent is that it is easy to confirm the number of records in the batch and reconcile with records received. This has not been the case with real-time streaming data.
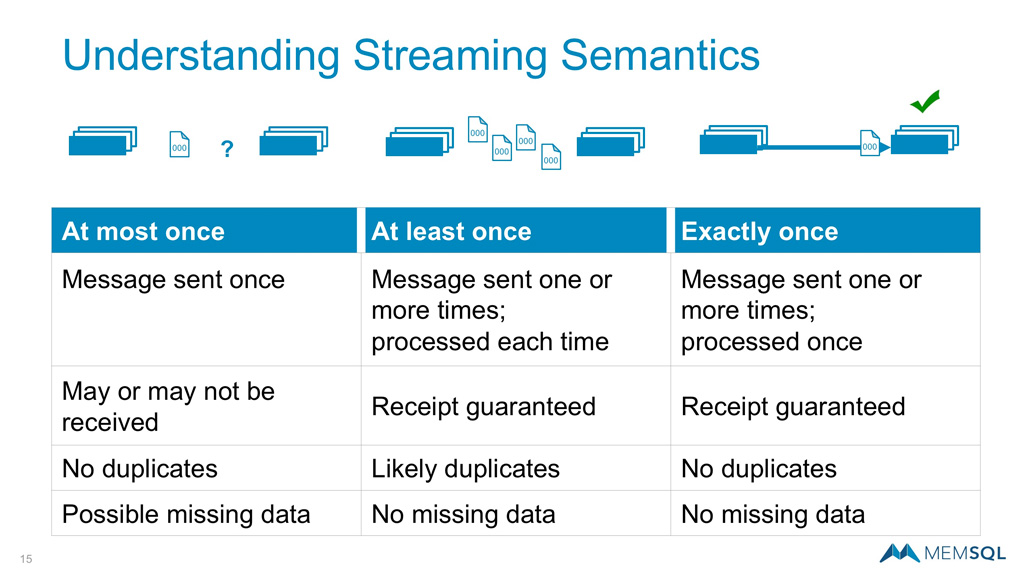
Messaging systems typically rely on a set of semantics that determine the integrity level of the exchange. These are often designated At Most One, At Least Once, and Exactly-Once. Let’s take a closer look.
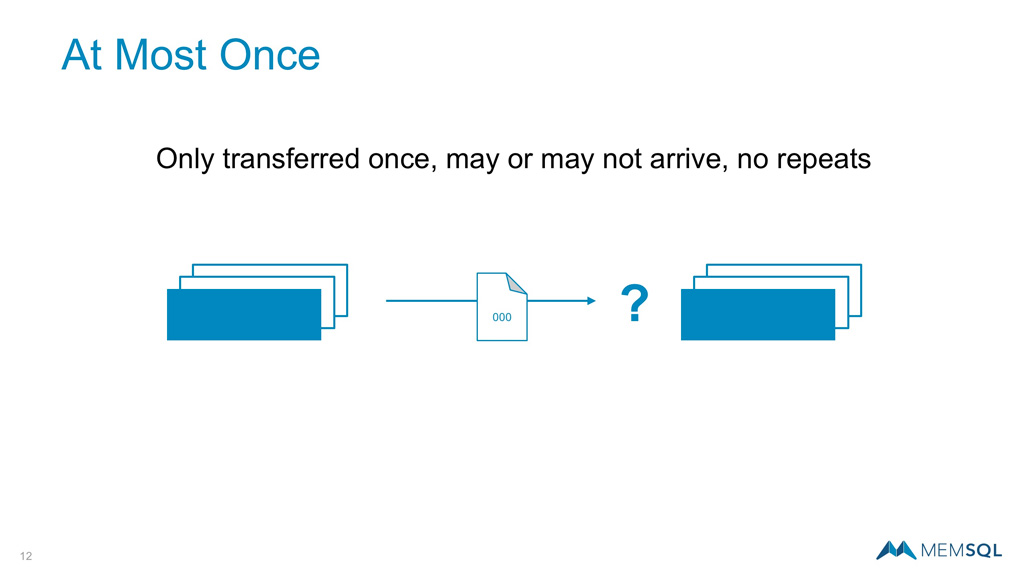
At Most Once
Using At Most Once semantics, a message will be passed from the initiating to the receiving cluster only once. Those messages may or may not arrive, but they will not be sent again. This approach limits bandwidth and retry exposure, but leaves room for missing data.
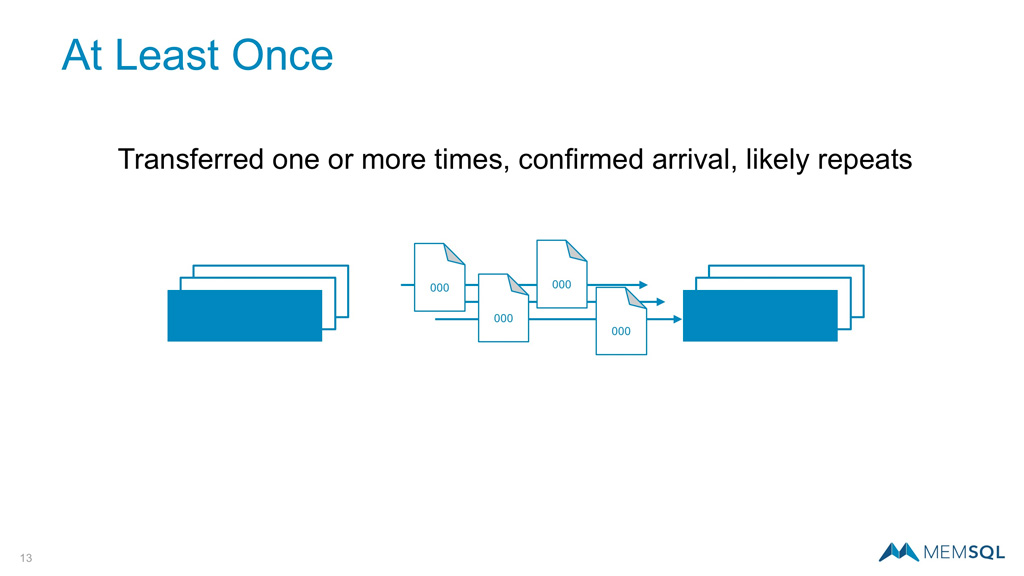
At Least Once
The next approach is At Least Once where messages will continue to be passed until receipt is confirmed. While these semantics ensure each record is received, the tradeoff is that there are likely to be duplicates requiring cleanup after the fact.
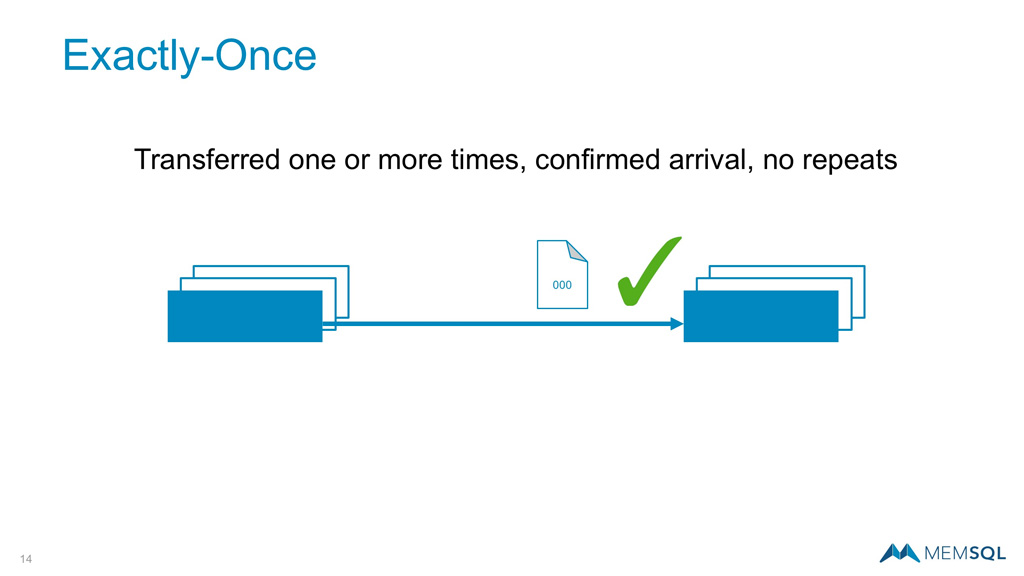
Exactly-Once
Another option is Exactly-Once which is more challenging to implement, but provides a richer, more robust mechanism to track streaming data and ensure records are received only once. This fits well with enterprise data flows that require this level of integrity and consistency like customer orders as one example.
The easiest way to implement Exactly-Once is to record the offsets in the same database transaction as you loaded the data which is trivial with the multipoint-to-multipoint “done right” architecture. In this fashion, SingleStore Pipelines delivers Exactly-Once semantics out of the box out of the box.
Comparing Streaming Semantics
All three types of semantics are detailed on the chart below. The Exactly-Once approach delivers guaranteed receipt, no duplicates, and no missing data.
The Future of Data Movement
Just a few years ago point-to-point data movement was the dominant topology and batch ETL was the bane of every database administrators existence.
With the adoption of distributed systems like Apache Kafka, Spark, the Hadoop Distributed File System (HDFS), and distributed databases like SingleStore, a new foundation for data movement is underway.
In addition, the popularity of real-time streaming has only scratched the surface of transforming enterprise batch processes. However, when coupled with more robust messaging semantics, like Exactly-Once, enterprise architects have a new playbook in their toolkit to tackle today’s data challenges.
Want to try it yourself? Take SingleStore for a spin at www.singlestore.com/cloud-trial/
Special thanks to Joseph Victor and Steven Camina for their contributions and review of this post.




.png?height=187&disable=upscale&auto=webp)





.jpg?width=24&disable=upscale&auto=webp)



