


Veteran SingleStoreDB users take our elasticity for granted. SingleStoreDB is a true distributed database. It's easy to scale up, so you can handle increasing demands to process queries concurrently — for both transactions and analytics.
Many application developers are still using single-box database systems and sharding data manually at the application level. That's not necessary with SingleStoreDB, which can save you many person-years of development time — letting you focus on the app, and not the data platform.
Although we can stretch and grow with your workload, we're pushing to make our elastic scale easier and more powerful. With the latest release of SingleStoreDB, we've taken a big step toward our ultimate goal of transparent elasticity with our flexible parallelism (FP) feature. FP is the premier feature in this release, and is part of our long-term strategy to make SingleStoreDB the ultimate elastic relational database for modern, data-intensive applications.
Flexible parallelism
SingleStoreDB uses a partitioned storage model. Every database has a fixed number of partitions, defined when you create the database. Historically, SingleStoreDB has done parallel query processing with one thread per partition. This works great when you have an appropriate partitioning level compared to the number of cores, such as one core for every one or two partitions.
With prior releases, when you scaled up, you couldn't use the extra cores to run one query faster. You could only benefit from them by running more queries concurrently. FP changes that.
Flexible parallelism works by internally adding a sub-partition id to each columnstore table row. Then, query execution decides a set of sub-partitions for each thread to scan on the fly. The use of sub-partitions allows shard key matching queries to work. To make this efficient, the sub-partition id is added internally to the beginning of the sort key.
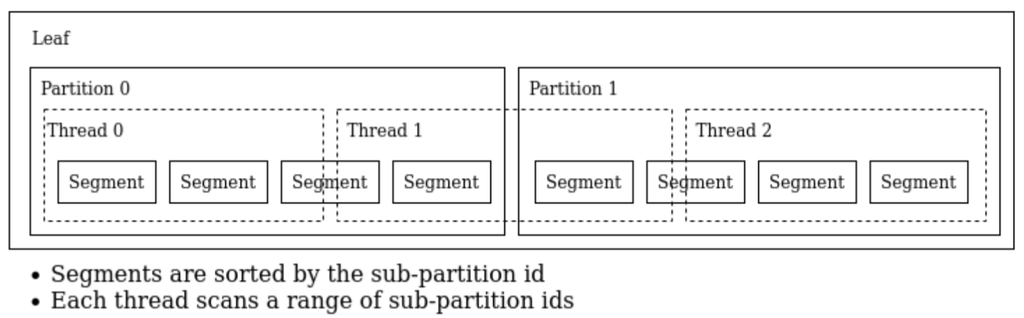
Figure 1 illustrates an example division of two partitions into three subsets of roughly equal size, to be scanned concurrently by three threads, so that all three threads finish about the same time and don't idle. This allows the fastest possible processing of all the data using three threads.
Performance example
Here's a simple example of FP in action. My hardware has eight cores, and I'm using one leaf node. Hyperthreading is enabled, so I have 16 logical cores (vcpus). I created a database db1 with eight partitions, and FP disabled. So queries will use eight threads. I created a table t(a int) with one million rows, loaded with serial numbers 1…50,000,000. Table t is sharded on column a so data is evenly distributed across partitions. I ran this simple query that does a cast (:>) and string LIKE operation 30 times in a loop, to burn a little CPU to make the measurement easier to see:
select a into x from t where a:>text like '1000000';
This loop takes 33.23 sec. Now, I copy the data to a database fp with two partitions that has FP enabled. The partitioning for db1 and fp is as follows:
select DATABASE_NAME, NUM_PARTITIONS, NUM_SUB_PARTITIONS
from information_schema.distributed_databases;
+---------------+----------------+--------------------+
| DATABASE_NAME | NUM_PARTITIONS | NUM_SUB_PARTITIONS |
+---------------+----------------+--------------------+
| db1 | 8 | 0 |
| fp | 2 | 128 |
+---------------+----------------+--------------------+
NUM_SUB_PARTITIONS is zero for db1, which indicates that it has FP is turned off for its tables. For database fp, it's non-zero, so FP is enabled.
Now if I use fp, copy table db1.t to fp.t, switch to use fp and run the same loop again, the result is returned in about the same amount of time, 34.20 sec.
This is a snapshot of the CPU meter during the above run on database fp:

It shows that all the cores are almost fully working on this query.
The loop executions run almost equally fast with all cores engaged, even though database fp has only two partitions. See Appendix 1 for a full script for loading the data and running the loops.
To show the contrast with the non-FP approach to query processing, I disable FP by running this:
set query_parallelism_per_leaf_core = 0;
(The next section will discuss FP configuration in more detail.)
Now, I run the loop again, and it takes 1 min, 31.59 sec. It's not exactly four times slower, but it's in that vicinity. Moreover, the CPU meter looks like this while it's running:

The key thing to observe is that only about a quarter of available CPU time is being used, since each query only uses two cores. The queries may be dispatched on different cores, one after the other, and the graph has some time-delay averaging. That's why it doesn't just drive two cores to 100% in the picture.
FP configuration
Flexible parallelism is on by default for customers using Singlestore Helios. It has sensible defaults, so most users won't have to configure it. For SingleStoreDB Self-Managed, it's off by default (but you can choose to turn it on). To use FP, you must enable it before you create the database you want to query.
These variables are available to configure flexible parallelism if the defaults aren't what you want:
- sub_to_physical_partition_ratio: This is a global variable. It causes creation of a specified number of sub partitions on newly created databases. For Singlestore Helios, this defaults to 16. That's often a good choice if you're self-hosting, too.
- query_parallelism_per_leaf_core: This is a session variable. It specifies the query parallelism to use in the session. It's a ratio between 0.0 and 1.0. A value of 0.0 means flexible parallelism is disabled. For Singlestore Helios, it defaults to 1.0. This means all the cores will normally be used by one query for a parallel operation.
- expected_leaf_core_count: This is a global variable. It should be set to the number of CPU cores on the leaves. It defaults to the number of leaf cores on Singlestore Helios.
If you want to use FP for SingleStoreDB Self-Managed, use the default values discussed. That'll normally be sufficient. Only consider changing these values if you want to achieve a specific goal, like reducing parallelism to allow more predictability under a heavy concurrent load.
You can check if flexible parallelism is enabled for a database by querying information_schema as follows:
select DATABASE_NAME, NUM_PARTITIONS, NUM_SUB_PARTITIONS
from information_schema.distributed_databases;
An example of this was given earlier. Again, a zero value for NUM_SUB_PARTITIONS means FP is disabled for tables from the corresponding database.
Understanding, troubleshooting and tuning FP
With the introduction of FP, when troubleshooting a query performance issue, you may now want to check if FP took effect for the query. You can do that by checking the parallelism_level used in the operators in the query plan. There are three possible levels:
- partition
- sub_partition
- segment
The partition level uses a thread per partition, sub_partition applies a thread per sub-partition and segment applies a thread per segment (typically a million-row chunk of a columnstore table). EXPLAIN and PROFILE plans now describe the parallelism level of relevant query plan operators; to see it, look for the parallelism_level symbol in the plans. If you see partition_level:sub_partition or partition_level:segment in the plan, then FP is being used for the query. Here's an example:
singlestore> explain select count(*) from t join t2 on t.a=t2.b;
Project [CAST(COALESCE($0,0) AS SIGNED) AS `count(*)`] est_rows:1
Aggregate [SUM(remote_0.`count(*)`) AS $0]
Gather partitions:all est_rows:1 alias:remote_0 parallelism_level:sub_partition
Project [`count(*)`] est_rows:1 est_select_cost:2
Aggregate [COUNT(*) AS `count(*)`]
HashJoin
|---HashTableProbe [t.a = r0.b]
| HashTableBuild alias:r0
| Repartition [t2.b] AS r0 shard_key:[b] parallelism_level:partition est_rows:1
| TableScan db.t2 table_type:sharded_rowstore est_table_rows:1 est_filtered:1
ColumnStoreFilter [<after per-thread scan begin> AND <before per-thread scan end>]
ColumnStoreScan db.t, KEY ... table_type:sharded_columnstore est_table_rows:1 est_filtered:1
This means that the Gather operation and everything following it uses sub_partition level parallelism, unless otherwise specified. The Repartition uses partition level parallelism because table t2 is a rowstore, and FP doesn't apply to rowstores. Rowstores are always processed using partition-level parallelism — however, after rowstore operations are processed, the resulting rows can be used by other operations that use FP.
The interesting expression "after per-thread scan begin” and “before per-thread scan end" (showing up as part of ColumnStoreFilter) represents the filters added internally by FP query execution. They filter the rows being processed by each thread, so that each thread only handles rows that belong to the set of sub-partitions assigned to it.
Another important aspect of troubleshooting and tuning FP is to check the settings of the three variables mentioned, and also to make sure you know whether FP is enabled for your database. This can be found by querying information_schema.distributed_databases. If NUM_SUB_PARTITIONS is 0, then FP is disabled for that database.
Cases that fall back to fixed parallelism
Some operations fall back to fixed parallelism, which is one thread per partition. These include:
- Reading from rowstore or temporary tables. Processing only falls back for parts of the query — the scans on those tables, and any shard key matching operations on top of them.
- Write queries. For INSERT .. SELECT, we only fall back for the INSERT part.
- Queries inside a multi-statement transaction
- Single-partition queries and queries with a shard-key-matching IN-list
- Queries that use the PARTITION_ID built-in function.
Optimizations disabled by flexible parallelism
Some optimizations related to ordering or sorting are disabled by FP. Some cases of ordered scans on the columnstore sort key are incompatible with the internal table schema change made for flexible parallelism, including:
- ORDER BY “sort key”
- Merge joins between sharded and reference columnstore tables
The aggregator GatherMerge operation is currently unsupported for queries using flexible parallelism. It falls back to Gather, followed by a sort on the aggregator.
Segment elimination — the skipping of whole segments based on applying filters to min/max column metadata for the segment — still works with sub-partitioning, but it may be less effective for some applications.
Other limitations and future work
A limitation of FP is that partition split (done with the SPLIT PARTITIONS option of the BACKUP command) is blocked if it causes the number of partitions to become larger than the number of sub-partitions. This is a rare occurrence — it's unlikely to affect many users since the default number of partitions is 16 on Singlestore Helios. You'd have to split more than four times to experience this.
You'll want to make sure that the number of sub-partitions is large enough that you can split one or more times, and still have plenty of sub-partitions in each partition. If you expect several splits, use more sub-partitions by setting sub_to_physical_partition_ratio to a larger value, like 64. In the future, we can overcome this limitation by increasing the sub-partition count during splits.
There is currently no command to enable or disable flexible parallelism on existing databases. Making a database capable of supporting FP can only be done at the time you create the database. If you want to make FP available for an existing database, you'd need to create a database with FP enabled and copy the tables from the original database to the new one. One way to do this is with CREATE TABLE LIKE and INSERT…SELECT.
Should I use FP?
If you are using Singlestore Helios, it's likely that you may want to quickly scale up, given the tendency of new cloud applications to start small and expand. Since flexible parallelism is automatically enabled for all new cloud deployments, you can take advantage of improved scalability without any changes to your application.
If you're using Self-Managed, are building a new application and you think you will expand your hardware by adding nodes or increasing node sizes over the next few years, you should use FP. If you're Self-Managed and have an existing application that is performing well, but you do think you will expand nodes and hardware, you may want to migrate to FP — but it’s important to note that requires reloading your database for now, since there’s currently no way to add sub-partitioning in place. And, you'll need to test your application to see if loss of some of the optimizations discussed earlier will impact it seriously if you use FP. The impact will likely be less than the benefit, but you'll need to verify that.
If you're certain you know the size of your workload and data for the next several years and don't think it will expand much, then you don't really need FP. Your up-front number of partitions will likely be the right number. And, you won't be subject to the limitations we’ve discussed.
The future of elasticity in SingleStoreDB
Flexible parallelism is a major step forward in elastic scalability for SingleStoreDB. You don't have to think so hard about how many partitions your database should have anymore, because even with few partitions per leaf, you'll still be able to take advantage of all your cores to run individual queries fast.
We see many areas where we can enhance elastic scalability even further, including:
- New ways to share a single database among multiple compute clusters
- Creating dynamic, online repartitioning
- Automatically scaling computing resources up and down in the cloud to provide a great experience during peak load and save money during slack time
- Removing the limitations of FP, and more
SingleStoreDB is an incredibly elastic RDBMS. And it's only getting more limber!
Try FP in 7.8. And stay tuned for more dynamic, flexible data power.
Appendix 1: Load Script For FP Demo
-- create a standard db without sub-partitioning
set global sub_to_physical_partition_ratio = 0;
create database db1;
use db1;
-- insert serial numbers 1..50,000,000 in a table
delimiter //
create or replace temporary procedure tp(SIZE int) as
declare
c int;
begin
drop table if exists t;
create table t(a int, shard(a));
insert t values (1);
select count(*) into c from t;
while (c < SIZE) loop
insert into t select a + (select max(a) from t) from t;
select count(*) into c from t;
end loop;
delete from t where a > SIZE;
echo select format(count(*),0) from t;
end
//
delimiter ;
call tp(50*1000*1000);
-- run this
delimiter //
do
declare x int;
begin
for i in 1..30 loop
select a into x from t where a:>text like '1000000';
end loop;
echo select 'done';
end
//
delimiter ;
-- the above loop completes in 33.23 sec
-- turn on FP for new DBs:
set global sub_to_physical_partition_ratio = 64;
set global query_parallelism_per_leaf_core = 1.0;
set global expected_leaf_core_count = 16;
-- leave session and start a new one
exit;
singlestore -p
-- show my FP variable settings
select @@query_parallelism_per_leaf_core, @@expected_leaf_core_count, @@sub_to_physical_partition_ratio \G
/*
@@query_parallelism_per_leaf_core: 1.000000
@@expected_leaf_core_count: 16
@@sub_to_physical_partition_ratio: 64
*/
create database fp partitions 2;
use fp;
create table t like db1.t;
insert t select a from db1.t;
-- run this again:
delimiter //
do
declare x int;
begin
for i in 1..30 loop
select a into x from t where a:>text like '1000000';
end loop;
echo select 'done';
end
//
delimiter ;
-- the result was returned in 34.20 sec
-- the time is about the same, indicating all the cores are
-- being used, even though there are only 2 partitions
-- now turn off FP:
set query_parallelism_per_leaf_core = 0;
-- run this again:
delimiter //
do
declare x int;
begin
for i in 1..30 loop
select a into x from t where a:>text like '1000000';
end loop;
echo select 'done';
end
//
delimiter ;
-- the result was returned in 1 min 31.59 sec






.png?width=24&disable=upscale&auto=webp)








