

Combining the data processing prowess of Spark with a real-time database for transactions and analytics, where both are memory-optimized and distributed, leads to powerful new business use cases. SingleStore Spark Connector links at end of this post.
Data Appetite and Evolution
Our generation of, and appetite for, data continues unabated. This drives a critical need for tools to quickly process and transform data. Apache Spark, the new memory-optimized data processing framework, fills this gap by combining performance, a concise programming interface, and easy Hadoop integration, all leading to its rapid popularity.
However, Spark itself does not store data outside of processing operations. That explains that while a recent survey of over 2000 developers chose Spark to replace MapReduce, 62% still load data to Spark with the Hadoop Distributed File System and there is a forthcoming Tachyon memory-centric distributed file system that can be used as storage for Spark.
But what if we could tie Spark’s intuitive, concise, expressive programming capabilities closer to the databases that power our businesses? That opportunity lies in operationalizing Spark deployments, combining the rich advanced analytics of Spark with transactional systems-of-record.
Introducing the SingleStore Spark Connector
Meeting enterprise needs to deploy and make use of Spark, SingleStore introduced the SingleStore Spark Connector for high-throughput, bi-directional data transfer between a Spark cluster and a SingleStore cluster. Since Spark and SingleStore are both memory-optimized, distributed systems, the SingleStore Spark Connector benefits from cluster-wide parallelization for maximum performance and minimal transfer time. The SingleStore Spark Connector is available as open source on Github.
SingleStore Spark Connector Architecture
There are two main components of the SingleStore Spark Connector that allow Spark to query from and write to SingleStore.
- A
SingleStoreRDDclass for loading data from a SingleStore query - A
saveToSingleStorefunction for persisting results to a SingleStore table
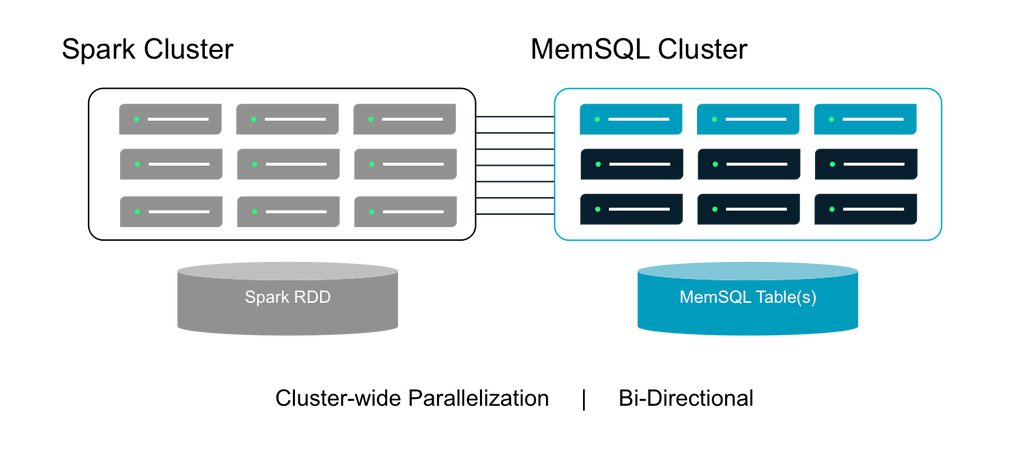
Figure 1: SingleStore Spark Connector Architecture
This high performance connection between SingleStore and Spark enables several relevant use cases for today’s Big Data, high-velocity environments.
Spark Use Cases:
- Operationalize models built in Spark
- Stream and event processing
- Extend SingleStore Analytics
- Live dashboards and automated reports
Understanding that operationalizing Spark often involves another system, SingleStore—with its performance, scale, and enterprise fit—provides significant consolidation, incorporating several types of Spark deployments.
Operationalize Models Built in Spark
In this use case, data flows into Spark from a specified source, such as Apache Kafka, and models are created in Spark. The results set of those models can be immediately persisted in SingleStore as one or multiple tables, whereby an entire ecosystem of SQL-based business intelligence tools can consume the results. This rapid process allows data teams to go to production and iterate faster.
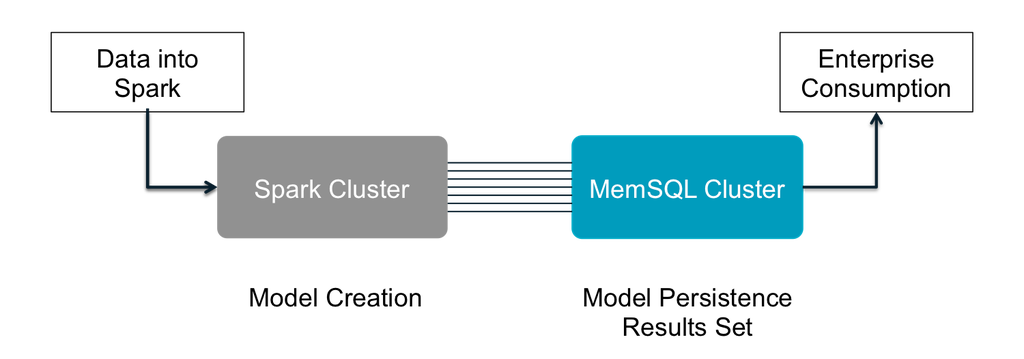
Figure 2: Operationalize models built in Spark
Stream and Event Processing
In the same survey of Spark developers, 67% of users need Spark for event stream processing, and streaming can also benefit from a persistent database.
A typical use might be to capture and structure event data on the fly, such as that from a high-traffic website. While the event stream may include a bevy of information about overall site and system health, as well as user behavior, it makes sense to structure and classify that data before passing to a database like SingleStore in a persistent queryable format.
Processing the stream in Spark, and passing to SingleStore, enables developers to
- Use Spark to segment event types
- Send each event type to a separate SingleStore table
- Immediately query real-time data across one or multiple tables in SingleStore
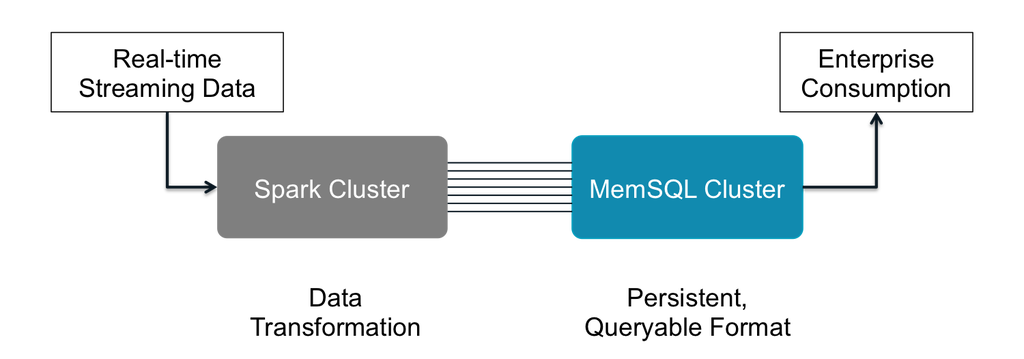
Figure 3: Stream and event processing
Extend SingleStore Analytics
Another use case brings extended functionality to SingleStore users who need capabilities beyond what can be offered natively with SQL or JSON. As SingleStore is typically the system-of-record for primary applications, it holds the freshest data for analysis. To extend SingleStore analytics, users can
- Set up a replicated cluster providing clear demarcation between operations and analytics teams
- Give Spark access to live production data for the most recent and relevant results
- Allow Spark to write results set back to the primary SingleStore cluster to put new analyses into production
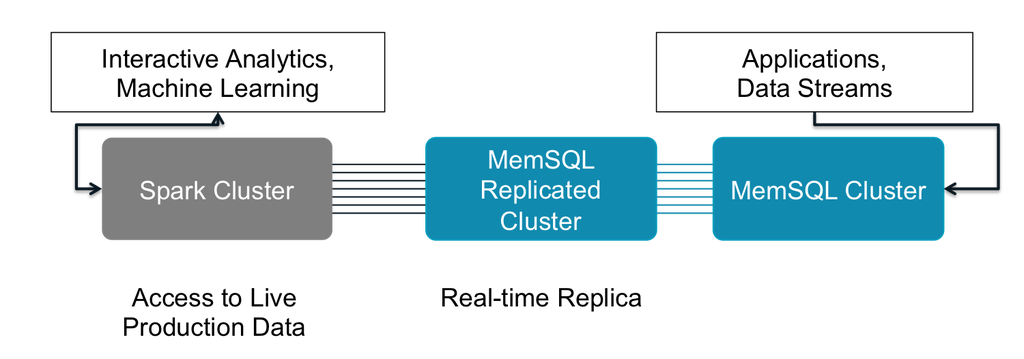
Figure 4: Extend SingleStore Analytics
Live dashboards and automated reports
Many companies run dashboards using SQL analytics, and the opportunity to do that in real-time with the most recent data provides a differentiating advantage.
There are, of course, advanced reports that cannot be easily accomplished with SQL. In these cases, Spark can easy access live production on the primary operational datastore to deliver custom real-time reports using the most relevant data.

Figure 5: Live Dashboards and automated reports
For more information on the SingleStore Spark Connector please visit:
Github Site for SingleStore Spark Connector
SingleStore Technical Blog Post
Get The SingleStore Spark Connector Guide
The 79 page guide covers how to design, build, and deploy Spark applications using the SingleStore Spark Connector. Inside, you will find code samples to help you get started and performance recommendations for your production-ready Apache Spark and SingleStore implementations.
Download Here



.png?width=24&disable=upscale&auto=webp)








