

This year’s ACM SIGMOD₁ database conference continued the recent trend of renewed interest in HTAP (Hybrid Transactional\Analytical Processing) by the database community, researchers and practitioners alike.
The conference featured four HTAP papers and an HTAP workshop. This is a significant increase over the past 3-4 years where the conference often had no HTAP papers at all.
One of these papers was our own SingleStoreDB architecture paper “Cloud-Native Transactions and Analytics in SingleStore”. This paper describes some key design decisions that enable SingleStoreDB to run a breadth of workloads — from more transactional (OLTP) to more analytical (OLAP) — with performance matching databases that specialize in one use case or the other.
Today, SingleStoreDB is one of the more widely deployed distributed HTAP SQL databases in the market. The remainder of this blog post is an overview of some of the important aspects of our paper, including a description of how SingleStoreDB performs on the mixed workload CH-benCHmark performance test.
HTAP databases like SingleStoreDB are starting to reverse a decades-long trend toward the development of specialized database systems designed to handle a single, narrow use case. With data lakes, in-memory caches, time-series databases, document databases, etc., the market is now saturated with specialized database engines. As of August 2022, DB-Engines ranks over 350 different databases. Amazon Web Services alone supports more than 15 different database products.
There is value in special-case systems, but when applications end up built as a complex web of different databases, a lot of that value is eroded. Developers are manually rebuilding the general-purpose databases of old via ETL, and data flows between specialized databases.
There are many benefits for users in having a single integrated, scalable database that can handle many application types — several of which result in reductions in:
- Training requirements for developers
- Data movement and data transformation
- The number of copies of data that must be stored — and the resulting reduction in storage costs
- Software license costs
- Hardware costs
Furthermore, SingleStoreDB enables modern workloads to provide interactive real-time insights and decision-making, by supporting both high-throughput low-latency writes and complex analytical queries over ever-changing data, with end-to-end latency of seconds to sub-seconds from new data arriving to analytical results. This outcome is difficult to achieve with multiple domain-specific databases, but is something SingleStoreDB excels at.
See more: The Technical Capabilities Your Database Needs for Real-Time Analytics.
Moreover, adding incrementally more functionality to cover different use cases with a single distributed database leverages existing fundamental qualities that any distributed data management system needs to provide. This yields more functionality per unit of engineering effort on the part of the vendor, contributing to lower net costs for the customer. For example, specialized scale-out systems for full-text search may need cluster management, transaction management, high availability and disaster recovery — just like a scale-out relational system requires. Some specialized systems may forgo some of these capabilities for expediency, compromising reliability.
SingleStoreDB is designed to deliver on the promise of HTAP. It excels at running complex, interactive queries over large datasets (up to 100s of terabytes) as well as running high-throughput, low-latency read and write queries with predictable response times (millions of rows written or updated per second). The two key aspects of SingleStoreDB described in more detail in our paper are:
- Unified table storage. SingleStoreDB’s unified table storage is unique in its ability to support the very fast scan performance of a columnstore (billions to trillions of rows scanned a second), while also having point read and write performance approaching that of a rowstore (millions of point writes a second) over a single data layout — no extra copies of data with different data layouts needed.
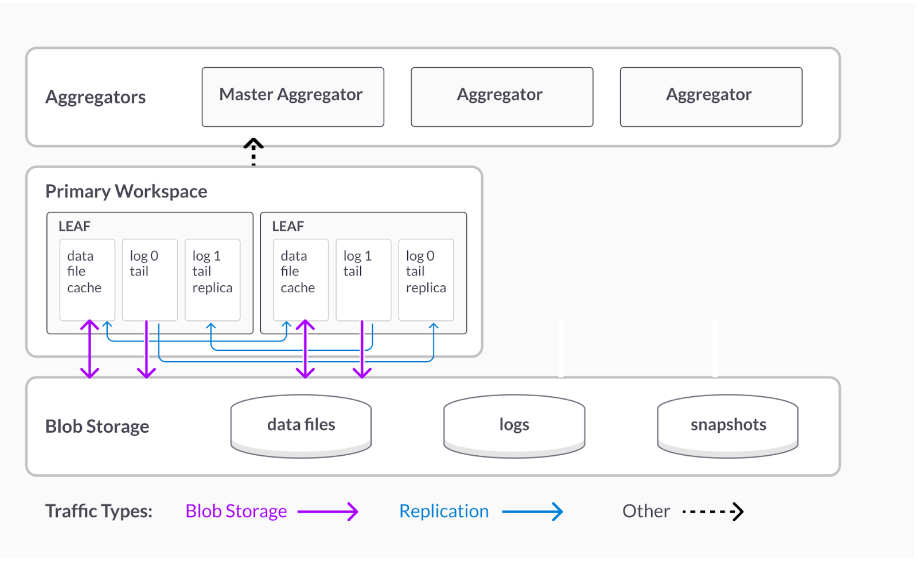
- Separation of storage and compute. SingleStoreDB’s separation of storage and compute design dictates how data is moved between memory, local disk and blob storage while maintaining high availability and durability of that data — and without impacting low latency write query throughput.
Unified Table Storage
In SingleStoreDB, both analytical (OLAP) and transactional (OLTP) workloads use a single unified table storage design. Data doesn’t need to be copied or replicated into different data layouts (as other HTAP databases often do). SingleStoreDB’s unified table storage internally makes use of both rowstore and columnstore formats, but end users aren’t made aware of this.
At a high level, the design is that of a columnstore with modifications to better support selective reads and writes in a manner that has very little impact on the columnstore’s compression and table scan performance.
The columnstore data is organized as a log-structured merge tree (LSM), with secondary hash indexes supported to speed up OLTP workloads. Unified tables support sort keys, secondary keys, shard keys, unique keys and row-level locking, which is an extensive and unique set of features for table storage in columnstore format. The paper describes in detail the LSM and secondary indexing layout as well as how it compares to other approaches.
Separation of Storage and Compute
SingleStoreDB is able to make efficient use of the cloud storage hierarchy (local memory, local disks and blob storage) based on how hot data is. This is an obvious design, yet most cloud data warehouses that support using blob storage as a shared remote disk don’t do it for newly written data. They force new data for a write transaction to be written out to blob storage before that transaction can be considered committed or durable (both Redshift and Snowflake do this).
This in effect forces hot data to be written to the blobstore, harming write latency. SingleStoreDB can commit on local disk and push data asynchronously to blob storage. This gives SingleStoreDB all the advantages of separation of storage and compute — without the write latency penalty of a cloud data warehouse. These advantages include fast pause and resume of compute (scale to 0) as well as cheaply storing history in blob storage for point in time restore (PITR).
CH-BenChMark: Mixed Workload Benchmark Results
One of the proof points in the paper was to show our results on the CH-benCHmark. This HTAP benchmark runs a mixed workload composed of parts from the famous TPC-C transactional benchmark running high throughput point read and write queries alongside a modified version of the TPC-H analytical benchmark running complex longer running queries over the same set of tables. It’s designed to test how well a database can run both a transactional workload (TW) and an analytical workload (AW) at the same time.
The following table shows our results. Test cases 1-3 were run with a single writable workspace with two leaves in it, each leaf having eight cores. Fifty concurrent TWs running parts of TPC-C resulted in the highest TpmC when they were run in isolation with no AWs (test case 1). Two AWs results in the highest queries per second (QPS) from TPC-H when run in isolation (test case 2).
When fifty TWs and two AWs are run together in the same workspace each slows down by about 50%, compared to when each is run in isolation (test case 3). This result demonstrates that TWs and AWs share resources almost equally when running together without an outsized impact on each other (i.e., the write workload from TPC-C does not have an outsized impact on the TPC-H analytical read workload).
Test case 4 introduces a read-only workspace with two leaves in it that is used to run AWs. This new workspace replicates the workload from the primary writable workspace that runs TWs, effectively doubling the compute available to the cluster. This new configuration (case 4) doesn’t impact TWs throughput when compared to test case 1 without the read-only workspace. AWs throughput is dramatically improved versus test case 3, where it shared a single workspace with TWs.
This is not too surprising as the AWs have their own dedicated compute resources in test case 4. The AWs QPS was impacted by ~20% compared to running the AWs workload without any TWs at all (test case 2), as SingleStoreDB needed to do some extra work to replicate the live TWs transactions in this case which used up some CPU. Regarding the replication lag, the AWs workspace had on average less than 1 ms of lag, being only a handful of transactions behind the TWs workspace. The paper has many more details on other benchmarking we did to show SingleStoreDB’s capability to run both transactional and analytical workloads with strong performance.

Summary of SingleStoreDB CH-BenCHmark results (1000 warehouses, 20-minute test executions)
With such a large market opportunity at stake for a database capable of running a breadth of workloads at scale, we expect to see more specific use-case databases being augmented with more general, HTAP-like capabilities. This includes the announcement by Snowflake of Unistore for transactional workloads, and MongoDB’s new columnstore index for analytical workloads.
Unlike these systems, SingleStoreDB was designed from its very early days to be a general purpose, distributed SQL database. This gives it an edge against some of the newer HTAP entrants that are bolting on new functionality to databases that were architected to target more specific workloads.
Even better, SingleStoreDB’s HTAP database is available for you to try today. Get started here.
Get the full research paper: Cloud-Native Transactions and Analytics in SingleStore
₁SIGMOD stands for “Special Interest Group for the Management of Data”. It’s one of the premiere database conferences for folks in both academia and industry to come together to share new ideas related to databases.










-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)

