
What is real-time analytics? The industry is still coming to terms with a standard name for this use case. It's sometimes called operational data warehousing, or operational analytics — and more recently, folks have started to use the term analytical applications.
In my view, these are all different names for very similar use cases. They all describe applications that need to run low latency analytical queries over fresh data. The most common pattern is an application designed to enable reporting, alerting or taking an action based on analysis of a live stream of data (click streams, application telemetry, data from IoT devices, equity or market data, logistical data, etc.). The workload combines reasonably complex analytic query shapes with the latency, concurrency and data freshness requirements more common in OLTP or operational applications.
SingleStoreDB has been running these types of workloads for many years. The first large deployment of SingleStoreDB (then called MemSQL) was doing real-time analytics based on in-game telemetry at pre-IPO Zynga way back in 2013. Since then, SingleStoreDB has developed a mature set of capabilities for real-time analytics born out of many years of production use by some of the world's largest and most demanding customers including Uber, Pinterest, Akamai, Comcast and many other large financial and high tech companies. As far back as 2016, Gartner rated SingleStoreDB as the top operational data warehouse in their survey of analytical databases. This article describes the key technical capabilities of SingleStoreDB that makes it well suited for real-time analytics.
At a high level, real-time analytics take an analytical workload (duh?) — so reasonably complex queries over reasonably large datasets (100s of GBs to 10s of TBs) — and applies some or all of these additional operational requirements to it:
- Low latency streaming data ingestion. Data is loaded and queryable within seconds of generation.
- Higher query concurrency requirements than a typical data warehousing workload (1000s of analytical queries a second). The apps are often user facing, and can experience spikes in usage.
- Low query latency requirements or strict latency SLAs (100s of ms or less is common) to be interactive.
The query workloads are also typically more precise than classical data warehousing. They often analyze or aggregate data for one (or a small number) of users or objects, instead of showing aggregate information over a large portion of the data set.
To make this discussion more concrete, here are some examples of real-time analytics among SingleStore’s customers:
- Energy & Utilities: Analysis of sensor data from oil wells to detect maintenance issues early, guide the drilling process and do profitability analysis. A similar use case applies to smart power meter telemetry for an electrical company.
- IoT & Telematics: Analysis of cell tower telemetry for a large cell phone carrier to detect phone call quality issues as early as possible.
- Gaming & Media: Behavioral analysis on the click traffic from web games or streaming video services to optimize end-user experience (like providing more personalized recommendations) and monitor quality of service.
- Marketing & Adtech: Market segmentation and ad targeting based on application telemetry, geospatial data and clickstream data from various sources.
- Retail & eCommerce: Low latency dashboards or
fastboardsto provide a live, 360-degree view of key company metrics - Fintech: Low latency stock portfolio analytics based on fresh market data for a large financial instiution’s high net worth customers.
- FinServ: Credit card fraud detection over a stream of purchase data and other telemetry.
- Cybersecurity: Security threat detection and analysis over device telemetry data
Explore more industry use cases for real-time analytics
These applications all involve analytical query shapes and yet, they’re use cases that traditional data warehouses do not handle very well. These workloads have technical requirements that set them apart from other analytics use cases:
- Low latency streaming data ingestion. Data should be ingested continuously as it is generated, and be immediately indexed and queryable. Batch data loading is not good enough.
- Flexible indexing to enable low latency data access in a variety of scenarios (selective queries, full-text search queries, geospatial queries, etc.).
- Good support for complex queries via ANSI SQL that matches top-tier data warehouses at data sizes in the 100s of GB, to 10s of TBs.
- Separation of storage and compute for improved elasticity and lower costs. Applications don’t need to give up elasticity to get low latency ingest and query capabilities.
- Strong high availability support to keep applications online in the face of hardware failures as well as when doing management operations such as database upgrades and schema changes
Before we jump into more detail on each of these features, let's first do a quick refresher of SingleStoreDB architecture and link to other blog posts where you can dive into much more detail. SingleStoreDB is a distributed (or clustered) SQL database. It can be self-managed inside a customer’s data center (or on a developers laptop), inside a customer’s cloud account (AWS, Azure, GCP) or accessed via a fully managed service. It speaks the MySQL wire protocol so MySQL client drivers and tools can connect to it. It hash partitions (or shards) data based on a user selected shard key, and spreads it amongst the nodes in the cluster. The storage is a universal table storage format that has the fast table scan performance of a columnstore, and selective seek performance approaching a B-Tree or other rowstore index. SingleStoreDB takes full advantage of the cloud storage hierarchy. Hot data is kept in memory, cooler data on local disks and cold data is kept in blob storage. This can be done without impacting query latency. SingleStoreDB has built-in high availability to handle node failures, and can be configured to handle availability zone and region failures.
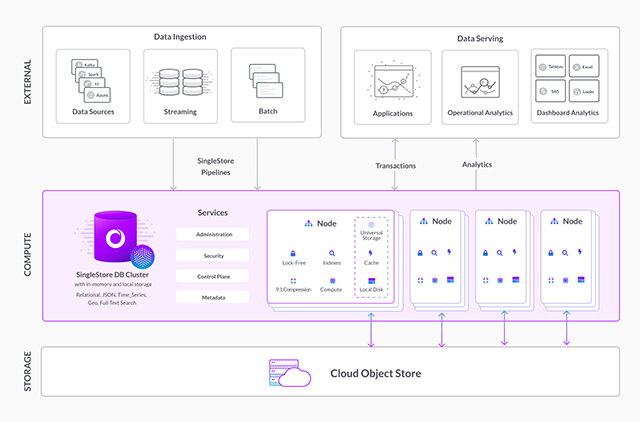
Now, let's look at important capabilities in SingleStoreDB for real-time analytics in more detail.
1. Low latency streaming data ingestion. As mentioned earlier, data freshness is important for real-time analytics. This makes streaming data ingestion — as opposed to bulk or batch data loading — an important capability. Because data is often generated in external systems and loaded into the database, loading of data in open formats (JSON, Parquet, Avro, CSV) is important for ease of use and interoperability. SingleStoreDB Pipelines were built specifically to satisfy these requirements. They support high throughput, exactly once data loading from Apache Kafka, blob stores (S3, Azure blob storage, GCS) or HDFS. Pipeline’s write performance scales with the size of the SingleStoreDB cluster and the capabilities of the target of the pipeline to keep data flowing. There is no single point of contention in an SingleStoreDB pipeline (i.e., data is not routed through a single node in the cluster). Pipelines also have a number of other useful features including built-in support for deduplication of data as it is inserted (if desired) and support for more general data transformation on loading via user-defined procedures that can transform the data as it loads.
SingleStoreDB also supports low latency and high-throughput SQL inserts/update/delete/load data statements so applications can import data in a manner that suits their specific needs. This feature may not seem that exceptional for a single box SQL database (like MySQL or Postgres), but data warehouses don’t have good support for these types of small writes — specifically for updates, upserts and deletes. All data warehouses today are columnstores and supporting point write queries against a columnstore is challenging because columnstores keep many rows tightly compressed together, making it slow and inefficient to modify only a few rows at a time. This is why SingleStoreDB employs a log structured merge (LSM) tree design with support for secondary indexes to enable efficient point write queries, including upserts (on duplicate key updates) over data in columnstore layout. There are more details on SingleStoreDB’s storage layout in the next section.
2. Flexible indexing. To deliver low query latencies, an application needs an efficient data layout optimized to match its query workload. As we’ve previously mentioned, SingleStoreDB on-disk storage is a columnstore. This gives it extremely fast scan performance for ad hoc analysis using well known techniques for column stores, like running filters directly on encoded data without decompressing first and executing filters on a batch of rows at a time using SIMD where possible. That said, fast table scan performance alone is not enough for most real-time analytics workloads. They still need mechanisms to limit the amount of data scanned for queries with selective filters, or when doing joins that only produce a few rows. Thus, SingleStoreDB supports a rich set of indexing techniques to speed up different data access patterns as shown in the following table. This is atypical for a columnstore, which usually has limited indexing capabilities.
| Index Type | Query Operations Improved or Enabled |
|---|---|
| Primary or unique keys | Equality queries (col=value), Upserts (ON DUPLICATE KEY UPDATE) |
| Secondary keys (inverted indexes) | Equality queries (col=value) |
| In-memory secondary keys (lockfree skiplists) | Range queries (col > value) over in-memory data only |
| Sort keys | Range queries (col > value), order bys, group bys and joins (merge joins). |
| Full-text keys | Full-text filters : MATCH (column) AGAINST ("term") |
| Geospatial keys | Point in polygon, nearest neighbor and other geospatial queries |
| Shard keys | Equality queries and push down joins and group bys (joins and groups on the shard key avoid the data movement of a reshuffle or broadcast |
| Zone maps (Min/Max indexing) | Range queries (col > value) Created on every column by default |
I won’t go into each of these indexing features in detail, but I do want to call out a few important capabilities that other analytical systems often don’t support:
- Shard keys: Joins and group-bys on the shard key columns can be executed without data movement (no need for a reshuffle or a broadcast). This is very important for high concurrency workloads. Shard keys also enable read queries that filter on the shard key to run on a subset of the nodes in the cluster (only those that own the shards the query is filtering for).
- Unique keys for easy deduplication: Most analytical databases don’t support unique keys that can do efficient row-level locking over terabytes of data. Unique keys enable high concurrency deduplication on data loading.
3. Strong analytical support for complex queries. SingleStoreDB’s SQL query processor matches the performance of top data warehouses on popular analytical benchmarks such as TPC-H and TPC-DS . These benchmarks are table stakes for analytical databases in 2022. They provide a reasonable baseline to judge the maturity of the database's complex SQL processing support, and the strength of its query noptimizer. I would be very suspicious of any database targeting real-time analytics that can’t run these benchmarks competitively with data warehouses. Many newer databases developed to support real-time analytics (Clickhouse or Apache Druid, for example) tend to focus on single table query performance with group-bys and aggregates, and have poor support for more complex query shapes that are common in analytical applications. This limits the types of applications that can be built with these systems, and often means applications need to do more work outside of the database to denormalize or pre-aggregate data. Non-trivial dashboarding is not possible on systems without top-tier analytical querying support, for example.
4. Separation of storage and compute. Separation of storage and compute is a critical component of a cloud-native analytical database. Being able to store data on a blob store such as S3 improves elasticity, lowers costs and improves durability. For example, scale up and scale down is more efficient if the data is stored in S3. Newly added hosts can pull data from S3 as needed, as opposed to needing to replicate it from existing hosts in the cluster. It also makes it cheaper to store colder historical data and enables point-in-time recovery to restore the database into a previous state (say, last week) in case of an application error. Cloud data warehouses all support separation of storage and compute, but they write new data directly to blob storage before acknowledging that data as committed — which is often not acceptable for real-time analytics (blob store latency is both variable and high; 10s to 100s of milliseconds per operation).
Use of a blob store for separated storage is often not a strict requirement for real-time analytics. The data sizes involved are typically small enough to use local disks in a classic, shared-nothing design that ties compute and storage. That said, the core requirements of the use case for low latency streaming ingest can still be accomplished by making proper use of the cloud storage hierarchy. Hot data should be kept in memory, cooler data on local disks and cold data in blob storage as SingleStoreDB does. There is no reason to give up the benefits of separated storage when doing real-time analytics.
5. Stronger availability requirements than typical data warehouses. Real-time analytics use cases often have availability requirements closer to those of operational applications than of a data warehouse. These use cases are not typically a “system of record,” but they are part of the serving layer for an application and are often customer facing so downtime can’t be tolerated. This includes no downtime for operational and maintenance work, and is why SingleStoreDB has features including online upgrades, online cluster expansion/shrink and online schema changes. SingleStoreDB has a robust set of availability features for cross-AZ and cross-region high availability, as well as support for full and incremental backups and point-in-time recovery (PITR) to ensure customers can meet their availability and durability goals.
Hopefully this quick features tour gave you a good intuition as to why so many companies have adopted SingleStoreDB for their analytical applications or real-time analytics use cases. We believe we are likely among the market leaders (as far as revenue share) for this small — but growing — market segment. Even still, we continue to add new features and improvements to make doing real analytics on SingleStoreDB easier and more efficient.











