
SingleStore has now released a new version of the Apache Spark Connector – Version 3.0 – which includes many new enhancements. The new Connector supports robust SQL pushdown, is compatible with the latest versions of Spark and the SingleStore engine, contains tight integration with Spark’s widely used DataSource API, and provides flexible load data compression options to expedite data ingest. Read on to learn more about the enhancements of the connector, and how you can accelerate your workload using Apache Spark and SingleStore together.
Apache Spark is widely known as a leading technology for big data and AI. If you use Spark in your workflow today, you already know that it’s a powerful data processing engine and that it’s best-in-class for data enrichment, computation, and analytics. Not only is it flexible, due to all the native libraries it contains (e.g., Structured Streaming, SQL, and machine learning), but it also supports a variety of programming languages.
What you might not know is how you can use Spark and SingleStore together to accelerate and transform your data processing and analytics at scale. While Spark shines at analyzing large datasets, many workloads require a solution for data persistence. SingleStore can be your persisted operational storage layer, and at the same time, it can be the analytical backbone for Spark.
SingleStore provides the solution – a fast database that is scalable, ingests data very rapidly, supports SQL, and supports queries with high performance and high concurrency. You can use SingleStore as self-managed software that you download and run in any cloud, or on-premises; or you can use Singlestore Helios, our fully managed, elastic cloud offering, on major public clouds.
How do Spark and SingleStore work together most effectively? The answer, as hinted above, is the SingleStore Spark Connector; SingleStore has developed a new version of our Spark Connector, Version 3.0, now available to customers (documentation here). Using SingleStore’s Spark Connector 3.0, you can leverage the computational power of Spark in tandem with the speedy data ingest and durable storage benefits of SingleStore.
More on the Spark Connector
The Spark Connector 3.0 is already used by many SingleStore customers. Like previous versions, this version of the Connector can load and extract data from database tables and Spark Dataframes, leveraging the SingleStore LOAD DATA command to accelerate ingest from Spark via smart compression.
The Connector also serves as a true Spark Data Source, so it can be used with a variety of different languages, including Scala, Python, Java, SQL, and R. And the Connector supports robust SQL pushdown; that is, applicable operations in Spark get translated to true SQL and executed, with high performance and excellent concurrency, on SingleStore.
The new Spark Connector 3.0 is compatible with the recent versions of Spark (versions 2.3 and 2.4). It is now easier to use and maintain, because it is fully integrated with JDBC’s API.
Note: For those that are new to Spark and would like to learn more about it, please visit the Apache Spark documentation.
SingleStore and Spark Reference Architecture
There are many ways in which SingleStore and Spark can be used together in a solution architecture. SingleStore can be the input to Spark for analytics work; SingleStore can store output from Spark after data enrichment; or SingleStore can do both at the same time.
Below is a reference architecture using Spark and SingleStore together. In this architecture, there is an application telemetry source streaming information into Kafka. The Kafka stream is then loading a subset of the data directly into SingleStore, and loading another subset into Spark for enrichment and further analytics prior to loading it into SingleStore. Furthermore, the architecture highlights that the SingleStore Spark Connector ensures seamless movement of data between the two sources, in either direction. Let’s dive into the details on how to use the SingleStore Spark Connector to implement this architecture.
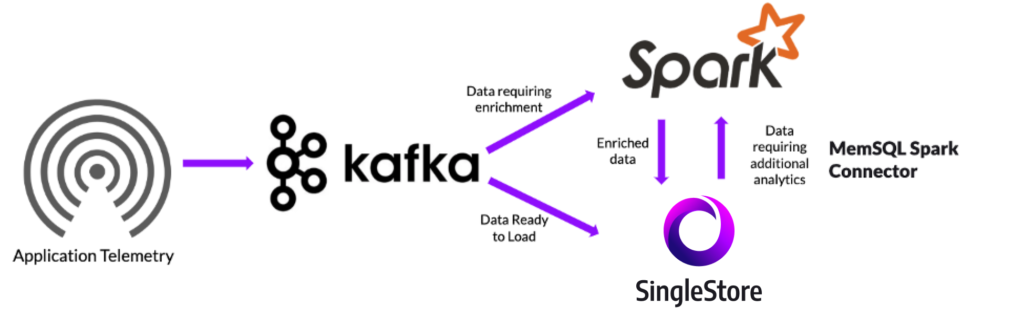
Using SingleStore Spark Connector 3.0
How do you actually put the SingleStoreDB Self-Managed 3.0 Spark Connector to use? Let’s say you need to capture and structure telemetry data from your high-traffic application on the fly, similar to the architecture above.
While the event stream may include a great deal of unstructured information about user interactions within the application, it may make sense to structure and classify a subset of that data before passing it to a database like SingleStore in a persistent, queryable format. Additionally, you may want to push existing data from the database into Spark, transform it, and return the enriched data back into the database. Processing data from your high-throughput stream in Spark allows you to efficiently segment or enrich the application events before writing data into a SingleStore table and querying it in real-time.
True Spark Data Source
Here we’ll describe some of the enhancements that make the SingleStore Spark Connector 3.0 different. The SingleStore Spark Connector 3.0 is a true Spark data source. It has robust SQL pushdown – the ability to execute SQL commands in SingleStore, instead of Spark – for maximum query performance benefits. And the new version of the Connector supports more load-data compression options. Details on these new capabilities follow.
Our connector is compatible with Spark’s DataSource API. This API is beneficial because results are returned as a Spark DataFrame, and the results can quickly be processed in Spark SQL or joined with other data sources. Additionally, as a JDBC API, the DataSource API is standard across the industry. This API allows you to write high-level, easy-to-use programs that operate seamlessly with and across many different databases, without requiring you to know most of the low-level database implementation details.
For example, to read data from SingleStore, you can use the following options, which will read from the table myTable in the database db.
val df = spark.read
.format("memsql")
.option("ddlEndpoint", "memsql-master.cluster.internal")
.option("user", "admin")
.option("password","S3cur3pA$$")
.load("db.myTable")
The integration with the reader/writer API allows us to use the JDBC standard spark.read.format syntax as we did above, specifying SingleStore as the data source format. Additionally, the ddlEndpoint, user, and password are SingleStore configuration options you can specify per query, or globally via Spark Configuration. In the above example, the options are specified at the query level.
You can also run queries to create tables and load data using SparkSQL, since the connector is a native SparkSQL plugin. For example, the following will register the table my_table that exists in SingleStore in your Spark table registry under data. You can then execute SparkSQL queries against data in Spark directly, which will select from your SingleStore table.
spark.sql("CREATE TABLE data USING memsql OPTIONS ('dbtable'='my_table')")
spark.sql("select * from data limit 10").show()
Finally, you can write data from Spark to SingleStore using the standard API df.write syntax. For example, this query writes a dataframe, mydataframe, to a SingleStore table called memsqldata:
mydataframe.write
.format("memsql")
.option("ddlEndpoint", "memsql-master.cluster.internal")
.option("user", "admin")
.option("password","S3cur3pA$$")
.option("overwriteBehavior", "dropAndCreate")
.mode(SaveMode.Overwrite)
.save("test.memsqldata")
The overwriteBehavior option specified in the configuration will drop and create the target SingleStore table to write the values in. You can also optionally specify truncate or merge. Using truncate will truncate the table before writing new values (rather than dropping them), while merge will replace all new rows, and update any existing ones, by matching on the primary key.
For more information on the SingleStore Spark Connector configuration options, please visit the README or the Spark Connector 3.0 documentation.
SQL Pushdown and SQL Optimization
The most cutting-edge aspect of the SingleStore Spark Connector 3.0 is its SQL pushdown support – the ability for SQL statements to be evaluated much faster, in the database, rather than in Spark, where they would run slower.
Complete statements are evaluated entirely in the database, where possible. The connector also supports partial pushdown, in cases where part of a query (e.g., a custom Spark function) must be evaluated in Spark.
Our connector supports optimization and rewrites for most query shapes and compatible expressions. Additionally, our query optimizations utilize deep integration with Spark’s query optimizer.
SQL Pushdown in Action
To demonstrate the behavior of partial SQL pushdown, let’s assume we have a large table in SingleStore called temperatures_allthat contains all cities in the United States, and their average high and low temperatures in Celsius for a given time period. Here’s a sample of the table below:
|city|state|avg_low|avg_high|
|Pasadena|California|18|27|
|San Francisco|California|20|24|
|St. Paul|Minnesota|1|22|
...
We want to do some computation in Spark using a custom user-defined function (UDF) to convert the high and low temperatures from Celsius into Fahrenheit, then obtain the result for San Francisco. So we register our SingleStore table temperatures_all using SparkSQL, under the name temperatures:
spark.sql("CREATE TABLE temperatures USING memsql OPTIONS ('dbtable'='temperatures_all')")
We create and register our UDF in Spark:
spark.udf.register("TOFAHRENHEIT", (degreesCelcius: Double) => ((degreesCelcius * 9.0 / 5.0) + 32.0))
Then, using SparkSQL, we run the following query to convert the averages from Celsius to Fahrenheit.
spark.sql("select city, state, TOFAHRENHEIT(avg_high) as high_f, TOFAHRENHEIT(avg_low) as low_f from temperatures where city='San Francisco'").show()
+-------------+----------+------+-----+
| city| state|high_f|low_f|
+-------------+----------+------+-----+
|San Francisco|California|75.2 |63.5|
+-------------+----------+------+-----+
In this case, the SingleStoreDB Self-Managed 3.0 connector will be able to push down the following to SingleStore:
- ‘SELECT city, state…’
- “…where city = ‘San Francisco’”
It will leave the evaluation of the ‘TOFAHRENHEIT’ UDF on the fields avg_highand avg_low to Spark, since that is where the UDF lives.
Appending.explain()to the query shows you the execution plan. This shows you exactly what is and isn’t getting pushed down from Spark to SingleStore. As you can see below, the final plan indicates a single projection on top of a SingleStore scan.
Gather partitions:all alias:remote_0
Project [a34.city AS `city#6`, a34.state AS `state#7`, a34.avg_high AS `avg_high#8`, a34.avg_low AS `avg_low#9`]
Filter [a34.city IS NOT NULL AND a34.city = 'San Francisco']
TableScan test.temperatures_all AS a34 table_type:sharded_rowstore
As expected, in SingleStore the query shows that the ‘where‘ clause was pushed down, along with the specific column selection for the projection.
SingleStore Query
Variables: (San Francisco)
SQL:
SELECT `city#6` , `state#7` , `avg_high#8` , `avg_low#9`
FROM (
-- Spark LogicalPlan: Filter (isnotnull(city#6) && (city#6 = San Francisco))
SELECT *
FROM (
SELECT ( `city` ) AS `city#6` , ( `state` ) AS `state#7` , ( `avg_high` ) AS `avg_high#8` , ( `avg_low` ) AS `avg_low#9`
FROM (
SELECT * FROM `test`.`temperatures_all`
) AS `a32`
) AS `a33`
WHERE ( ( `city#6` ) IS NOT NULL AND ( `city#6` = ? ) )
) AS `a34`
To see all the stages of the optimization and pushdown process, you can append .explain(true)to your statement, which will provide more detailed information on the execution process.
The above example shows the power of pushdown on a small data set. When you have billions of rows of data you are analyzing, the performance benefits of evaluating operations in SingleStore versus Spark are immense.
Load Data Compression
SingleStore’s Spark connector supports flexible load data compression options; you can use GZip or LZ4. Compression ensures maximum data loading performance when you are loading data from Spark into SingleStore. As an example, the following will write the table myTable from Spark into SingleStore, and use LZ4 compression.
df.write
.format("memsql")
.option("loadDataCompression", "LZ4")
.save("test.myTable")
Conclusion
Using SingleStore and Spark together has great benefits for high-velocity applications which require fast computation and diverse analytic libraries, extremely fast loading, and the need to query data as it’s being loaded. The SingleStore Spark connector ensures a tight integration between the two systems, providing high performance, and maximizing the benefits of SingleStore as the data source and Spark as the analytics framework.
You can try the Spark Connector 3.0 by adding it to your library from SingleStore’s Github repository. Follow the README for detailed instructions on usage. We also have a guide on using Kafka, Spark, and SingleStore together, and a demo of the Connector you can test with Docker. If you are not yet using SingleStore, you can try SingleStore for free or contact SingleStore.















