
In this webinar, Mike Boyarski and Eric Hanson of SingleStore describe the promise of machine learning and AI. They show how businesses need to upgrade their data infrastructure for predictive analytics, machine learning, and AI. They then dive deep into using SingleStore to power operational machine learning and AI.
In this blog post, we will first describe how SingleStore helps you master the data challenges associated with machine learning (ML) and artificial intelligence (AI). We’ll then show how to implement ML/AI functions in SingleStore. At any point, feel free to view the (excellent) webinar.
Challenges to Machine Learning and AI
Predictive analytics is helping to transform how companies do business, and machine learning and AI are a huge part of that. The McKinsey Global Institute analysis shows ML/AI having trillions of dollars of impact in industry sectors ranging from telecommunications to banking to retail. AI investments are focused in automation, analytics, and fraud, among other areas.
However, McKinsey goes on to report that only 15% of organizations have the right technology infrastructure, and only 8% of the needed data is available to AI systems across an organization. The vast majority of AI projects have serious challenges in moving from concept to production, and half the time needed to deploy an AI project is spent in preparation and aggregation of large datasets.
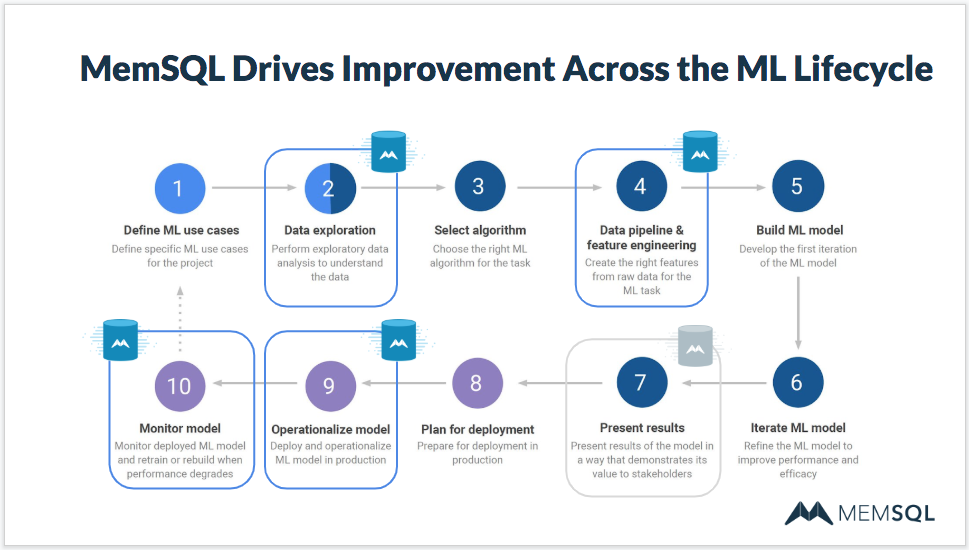
The machine learning and AI lifecycle has ten steps, and several of them have data-related challenges. SingleStore addresses many of the toughest ones:
- Define ML use cases. Find specific ML use cases for the project.
- Data exploration. Perform exploratory data analysis. SingleStore’s ability to aggregate disparate sources of data and its speed and responsiveness, even on large data sets, help here.
- Select algorithm. Choose the ML algorithm that will best perform the task.
- Data pipeline and feature engineering. Profile your incoming data to identify the relevant features that will support the ML task. SingleStore helps here due to its flexibility in dealing with data in memory (rowstore) and on disk (columnstore), as well as its scalability to handle arbitrarily large data volumes.
- Build ML model. Develop the first iteration of the ML model.
- Iterate ML model. Refine the model to improve performance and efficacy – increasingly, this process can itself be ML-assisted.
- Present results. Present results of the model in a way that demonstrates its value to stakeholders. SingleStore can power dashboards or other tools for showing the results of ML model refinement.
- Plan for deployment. Prepare for deployment to production.
- Operationalize model. Deploy and operationalize ML model in production. This is where SingleStore makes the biggest difference. SingleStore’s speed, scalability, and SQL support all make the implemented model faster and more effective.
- Monitor model. Monitor the model in production; retrain or rebuild it to add features or improve performance. SingleStore has built-in monitoring tools that can play an important role in the overall monitoring process.
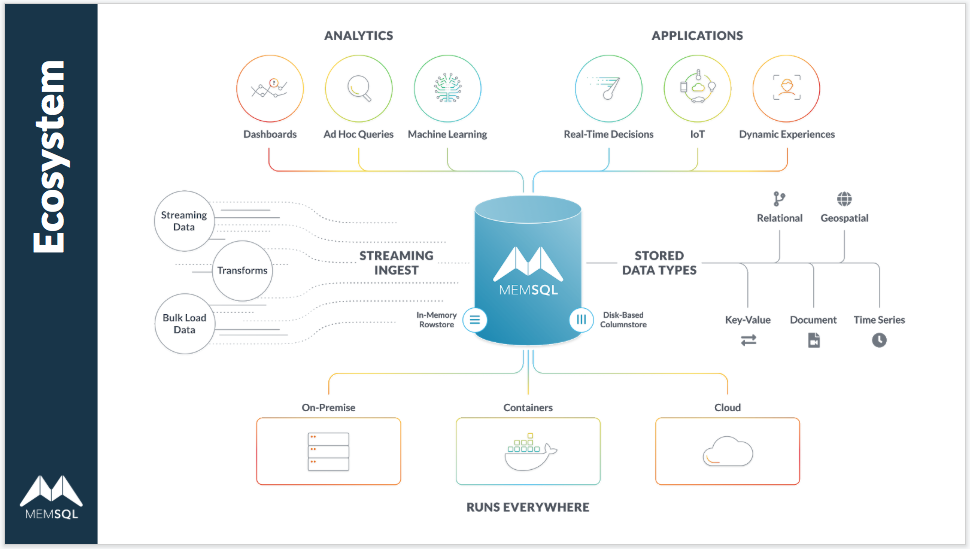
To sum up, key challenges in ML/AI implementation that are addressed by SingleStore include modernizing data infrastructure; simplifying and accelerating query performance against big data; and adding scalability and convergence to the process of operationalizing AI.
Overview of AI/ML Support in SingleStore
SingleStore has features that support key aspects of the machine learning and AI lifecycle:
- Integration with ML/AI tools
- The transforms capability in SingleStore Pipelines, for seamless scoring of relevant features as data is loaded
- Using SingleStore extensibility for additional and more complex scoring
- Built-in vector similarity functions with very fast performance
Here’s an example of using the transforms capability in SingleStore Pipelines:
CREATE PIPELINE mypipeline AS
LOAD DATA KAFKA '192.168.1.100:9092/my-topic'
WITH TRANSFORM ('http://www.singlestore.com/my-transform.tar.gz', 'my-executable.py', '')
INTO TABLE t
For more information, see the SingleStore Documentation.
Image recognition is an important capability enabled by ML/AI, and SingleStore has several customers using this today. You can train the model with other data components that connect well to SingleStore, including Apache Spark, TensorFlow, and Gluon. You can then use your model to extract feature vectors (called embeddings) from images. The feature vectors can then be stored in a SingleStore table for fast processing.
There are several SingleStore functions that are directly useful for vector similarity matching:
- DOT_PRODUCT(vector, vector)
- EUCLIDEAN_DISTANCE(vector, vector)
- JSON_ARRAY_PACK(‘[float [, …]]’)
SingleStore’s capabilities are applicable to a variety of different job tasks in the machine learning and AI lifecycle.

SingleStore’s connectivity, capabilities, and speed make it a solid choice for machine learning and AI development and deployment.
For more information, view the webinar.








