

This webinar describes what’s needed to successfully migrate your data to the cloud. What does a good cloud data migration look like? What are the strategic decisions you have to make as to priorities, and what are the challenges you’ll face in carrying out your plans? We will describe a tried and tested approach you can use to get your first wave of applications successfully migrated to the cloud.
About This Webinar Series
This is the second part of a three-part series. Last week we covered migration strategies; broad-brush business considerations to think about, beyond just the technical lift and shift strategy or data migration. And the business decisions and business strategy to guide you as to picking what sorts of workloads you will migrate. What sorts of new application architectures you might take advantage of.
In today’s webinar we’ll go one level deeper. Once those decisions are mapped out, what does a good cloud data migration look like? And in the final session, we’ll go a layer deeper, and we’ll get into migrating a particular source to target database.
Challenges of Database Migrations
So you’re looking at migrating an on-premises, so-called legacy database. You have particular IT responsibilities that span lots of different areas, lots of different infrastructure, lots of different layers. You’ve got the responsibility of all of these things. But a lot of this work doesn’t provide any differentiation for you in the marketplace or for your business.
So when you look at what’s possible in moving to a cloud database, the main thing that you get to take advantage of is a lot of that infrastructure is taken care of for you. And so any cloud database is going to greatly reduce that cost of ownership in terms of the infrastructure management.
So the general value proposition of a cloud database, or any SaaS service, is that it allows you to reduce all of this work and focus on the business differentiation of your application.

There are still challenges that you have to address in moving to a cloud database. First is the dependencies of applications. So an application may use particular proprietary data types. There may be custom logic and stored procedures, custom functions, etc., and SQL extensions that you’ll need to look at in your initial assessment.
But it’s not just the database itself that has to be considered when you’re doing a migration. There’s an ecosystem around the database, tooling and such, doing things such as replication. You may have real-time data integration in and out of your database through ETL, Kafka, middleware products, that sort of thing.
You want to look for what visibility you have in terms of monitoring and management. And any sorts of practices or automation that you have around your existing visibility and monitoring. You have to look at that in terms of migration, or redo those processes and techniques and backup and recovery. And you have to discover and set your goals.
Ask the right questions:
- Determine which applications and data can – and cannot – be readily moved to a cloud environment.
- Identify the workload types – maybe high-frequency transactions on an OLTP type of database, or needs further into the analytics spectrum.
- Determine which applications you do not want to move to cloud.
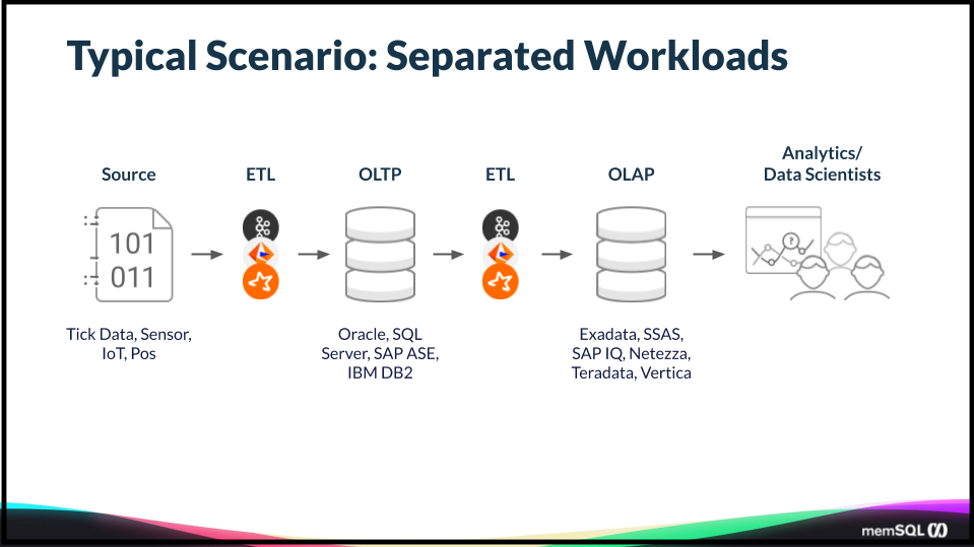
There’s a data integration process – extract, transform, and load (ETL) – that provides significant latency between when data’s written to the original source and into an analytic store for queries. The trade-off and the cost of this is that you have latency introduced here in the queries to the right.
So this might be fine if this is a weekly report. It’s not a report that has to run in a particular timeframe. But, as you move into real-time scenarios, this is what we at SingleStore call operational analytics.
There’s no time for ETL etc. anymore. Thus, your reasons for moving to a cloud database. One is to scale further because your data is expected to grow. You also want to avoid the cost of all of that infrastructure. And you want a better consumption model for going forward. Things like Oracle tend to be very expensive. They perform, up to a point, but they’re expensive and difficult to scale.

So what about the data itself? What do we think about what to look for here? And there’s four aspects essentially, when you’re looking at the migration from a particular database to a cloud database. And the first is the shape, which follows from what I just discussed in terms of data models. How the data is structured in the schema and what types are used will dictate that shape.
if you’ve got row structure data along with JSON you may want to join … It would be easier in your application and simplify your application if you could join the array structure of JSON with rows. If you could do distributed joins across any of the distributed data. SingleStore allows this converged model across these different types of data shapes.
So what is the total dataset size? Is it somewhat fixed, or is it something that is unbounded – that you expect to grow on a continual basis? You collect this data because it has consequences to your business operations. How efficient or how well that operation’s doing, and time matters.
You want to make decisions in the moment. What’s the subset of the data that’s going to be queried? So it could be terabytes and terabytes, maybe petabytes. We can query that in a way that we can spread data across a distributed database, such as SingleStore, and get parallelism. The goal should be to serve the largest variety of workloads with the least amount of infrastructure.
You can do that in a cloud native database like Singlestore Helios that handles all of these workloads. So that simplification is really important, especially in the cloud era, when infrastructure in the cloud is so easy to create. With just a push of a button – or not even that, an automated API call.
So let’s take a poll of you, the people attending.

So overwhelmingly the attendees, you’ve reported that a traditional relational database – Oracle; SQL Server; Aurora, which is either a Postgres or MySQL variant; and MySQL are your most common. And that’s not a surprise; MySQL is the most popular database in the world.
Typically we also find that the analytic warehouses are the ones to move first to the cloud because there’s less risk. But what we’re seeing now, and it’s happening in a big way, is the operational database moving to the cloud and handling these cloud-scale, mixed workload things.
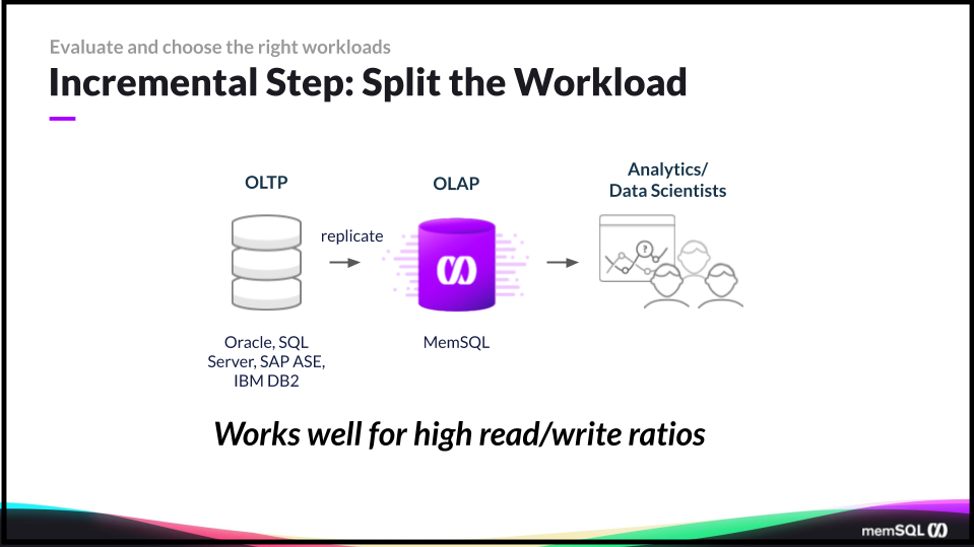
One pattern that’s worked for SingleStore with our customers, is to take an incremental step. And to split some of the workload from maybe that transactional system that might be handling all of the ingestion of the transactions as well as analytics. If you can have a near-real-time, or with the smallest lag possible, to do analytics against that transaction and scale the concurrency. So that’s a good initial first step, to do a partial migration and replicate the data needed for analytics – provide it to the applications, the data scientists, the analysts.
SingleStore, as a distributed database, allows you to handle highly concurrent reads. The nodes of the database for handling those inbound queries can be scaled independently of the data nodes themselves. And so that allows you to do this cost-effectively. If you’re using Singlestore Helios for this, it’s as simple as pushing a button and resizing your cluster. But if you have this on-prem, or self-managed SingleStore in the cloud, again you’re scaling the aggregators to allow this concurrency.
So this pattern is a good initial first step that helps to minimize risk. Especially, it works when you’ve got really high read to write ratios on this data. In talking to some of our banking customers, sometimes if we’re talking about retail banking and it’s a mobile banking application, that sort of thing. Or the web application, it can be as much as nine-to-one or 10-to-one in terms of reads to writes.
Data Migration
In moving applications to the cloud, you’re dealing typically with really large amounts of data. And so how you handle the replication itself, for example, should be elastic. Just in the way that a modern database like SingleStore is distributed and Singlestore Helios is elastic.

You often have massive amounts of data. It could be hundreds of terabytes, from tens to hundreds of databases. So doing it in a serial single fashion can take quite a lot of time. So you want to be able to distribute that migration and replication work and parallelize it as much as possible.

SingleStore Replicate is a built in capability of the product. It’s not something separate. It allows you to do this replication from sources such as Oracle, Oracle RAC, SQL Server.
And in the future we’ll be doing more with it. Today these are the sources. You’ll find more information about this at docs.singlestore.com. And it supports what I’ve just described earlier. The essential characteristics of reliable cloud data migration, where it comes to the data migration and replication itself. And then it supports the essential elasticity.
It’s distributed, it can replicate in parallel. It can recover from checkpoints. So that when you’re moving massive datasets from your operational database, you can get all of that reliably into your target system.
So at this point, I’ll pause for a polling question: what types of replication are you using today? Some of this might be dictated by the database ecosystem that your company currently uses. GoldenGate for instance, is part of the Oracle Suite. Informatica is independent.
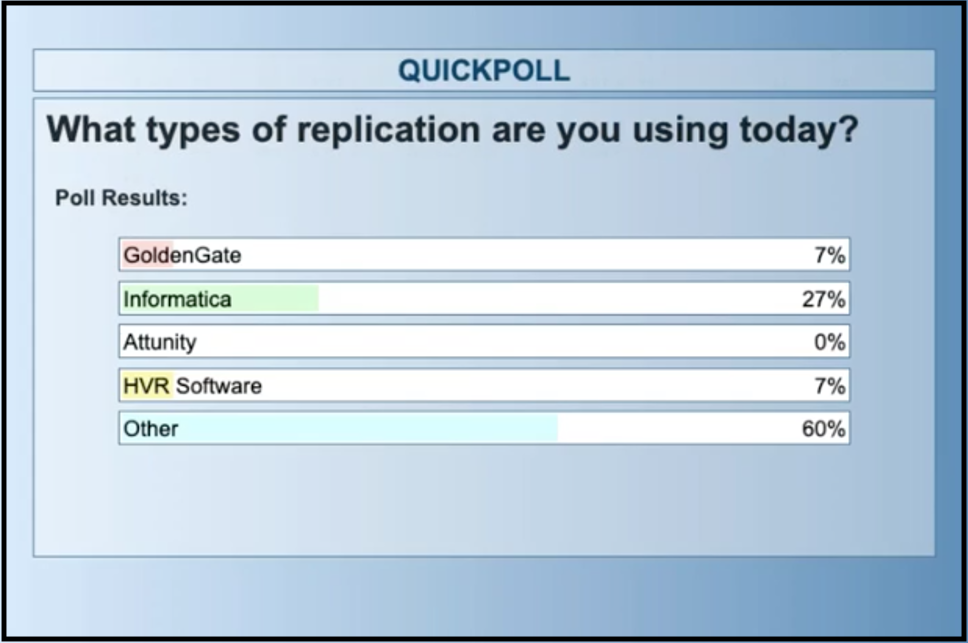
So what types of replication are you using today? That’s an interesting result. This space of data integration and ETL has grown quite a lot in recent years. Especially in the cloud context. There are other cloud native ways such as Google, Alooma to do integrations with their databases. Matillion is another one that comes to mind.
So I think this result, to put it in perspective, indicates what we’ve seen in the large amount of options that have grown. And also the fact that there’s so many choices here that it shows how much data migration or database migration to the cloud is happening.

I’ll leave you with these three takeaways, and that there’s lots to consider when migrating an operational database to the cloud.
First and foremost, assessing the workload. It’s important to understand that you may find different shapes of data, different data types, different data models used. And that no longer are you restricted to having to move in a one-to-one fashion or a one-to-many fashion. In the way that Amazon has moved from Oracle databases and to five or more different types of databases. That’s a complex scenario. And it’s expanded their infrastructure in terms of the variety and types.
That’s more complex to manage. So you have to consider, does your business have the staff and skills to manage a growing variety of database types. Or can you look to move to a cloud database that supports these multiple types of models in a converged fashion, as Singlestore Helios does.
Secondly, migration of a database is not an all-or-none proposition. You can do this in a partial migration using a pattern that we’ve seen successful with our customers. If the workload ratio of reads to writes is very high, and needs high concurrency for reporting, web, mobile access for users, then consider just replicating the data to Singlestore Helios to first provide the analytical workload in the cloud. And then secondly, come back and move the transactional workload.
Thirdly, automate as much as possible in the migration process. Tools are a big part of the answer, but they’re not the only part.
And as I said, no matter what source or target database you’re moving from or moving to, the stored procedures, procedural languages is where you should expect some manual work. Even if you’re moving from one version of MySQL to another version of MySQL or one version of PostgreSQL to another, you’ll have those problems.
For the next session, the final session of the series, I’ll be talking about database migration best practices. And so I’ll get into one more level of technical specifics of how you do this with SingleStore and replicate, as I showed you. So you have something concrete in terms of seeing how this process is done.
Q&A and Conclusion
Have any SingleStore customers migrated from Oracle?
Yes. I would say that’s the most common. Oracle has a very large footprint in the enterprise. And we’ve migrated from Oracle RAC and Oracle DB and Oracle Exadata. Not only Oracle though, we’ve also migrated from Microsoft SQL Server, SAP HANA. And then newer types of databases as well, such as migrations from Snowflake to SingleStore and SAP HANA to SingleStore. And in the Snowflake example, it’s often because there’s a need for lower latency for operational analytics, including greater concurrency. And the way that SingleStore was built allows for that low latency, real-time result – an HTAP, hybrid transactional/analytical process use case.
Besides replicate, what are ways to get data into SingleStore?
A real-time way to get data in is through SingleStore Pipelines. So that is an integration capability built into this product that allows you to subscribe to Kafka topics. You can do ingestion in parallel. If you’ve got multiple Kafka partitions, then those can map to the distributed partitions of Singlestore Helios, such that you can ingest in parallel. It’s a little bit different of an integration strategy, because you’re not getting all of the guarantees that I just described in replication through SingleStore Replicate. But it is an initial way to get data in. And then finally a bulk load of data from a flat file source, CSV, Hadoop, S3 buckets. What I would call data at rest, or static data. You can bulk load in that way.
Can I manage SingleStore in my own cloud environment?
Yes. So Singlestore Helios provides SingleStore as a database as a service. But with Singlestore Helios, you’re not managing any of the infrastructure. You can also deploy SingleStore in a cloud environment and manage it yourself. We make that easy because we provide the Docker image and the Kubernetes Operator. Such that if that’s the fashion that you’re doing it in your VPC, it’s fairly easy to do. Or you can do it with just the native binaries and install it in your cloud environment yourself. You’ll also find it on the Amazon marketplace, and you can try out setting that up in Amazon.
You can try SingleStore for free – either Singlestore Helios, or the SingleStoreDB Self-Managed that you manage yourself – or contact SingleStore today.













