

SingleStore Universal Storage は、データベースの動作方法に関する新しいビジョンです。現在の行ストア テーブルと列ストア テーブルの違いは最初はあいまいになり、その後、ほとんどのユース ケースで完全になくなります。SingleStore Universal Storage™ Phase 1 は、SingleStoreDB Self-Managed 7.0 (現在ベータ版) の一部として出荷され、行ストア テーブルで NULL 圧縮が可能になり、多くの場合 TCO が 50% 削減されます。列ストア テーブルでは、高速なシークと更新をサポートするシーク可能な列ストアが実現され、行ストア テーブルのパフォーマンスとユーザビリティに関する多くの機能が列ストア テーブルに提供されます。開発者がこれまで行ストア テーブルと列ストア テーブルの中間、または行ストア データベース ソフトウェアと列ストア データベース ソフトウェアを別々に提供するという難しい選択に直面していた状況が大幅に軽減され、コストが削減され、パフォーマンスが向上します。SingleStoreDB Self-Managed 7.0 で提供される新しい System of Record の改善により、「1 つのデータベースですべてを管理する」というビジョンが実現し始めます。
これは、SingleStore独自の特許取得済みUniversal Storage機能について説明する4部構成の記事の第1回です。全容をご理解いただくには、シリーズの第2部、第3部、第4部をお読みください。
SingleStore Universal Storageのご紹介
SingleStore Universal Storageは、データベースストレージアーキテクチャにおける画期的な技術であり、運用ワークロードと分析ワークロードを単一のテーブルタイプで処理することを可能にします。これにより、開発者の作業が簡素化されるとともに、優れたスケーラビリティとパフォーマンスが実現し、コストも最小限に抑えられます。
SingleStoreDB Self-Managed 7.0 の重要な第一歩として、Universal Storage Phase 1 では、OLTP アプリケーションが列ストアテーブルを使用して、RAM をはるかに超えるデータに対して運用トランザクションを実行できるようになります。これは、新しいハッシュインデックスと、ディスクベースの列ストアテーブルにおける関連する速度および同時実行性の向上によってサポートされ、インメモリ速度でのシークと更新を実現します。Universal Storage Phase 1 では、高速なメモリベースの行ストアテーブルにおける null 値のインメモリ圧縮により、大規模なデータセットに対するトランザクションアプリケーションをより経済的にサポートするようになりました。これにより、多くのユースケースで約 50% のメモリ節約が実現します。
これらの改善により、SingleStore のお客様は、低コストで優れたパフォーマンス、コンピューティング リソースを最大限に活用する柔軟性、そして最大のデータ管理�問題に経済的に取り組む能力を獲得できます。
究極のテーブルフォーマットのビジョン
SingleStoreは、同一データベース内で2種類のデータテーブルをサポートします。1つはインメモリ行ストアで、オンライントランザクション処理(OLTP)およびハイブリッドトランザクション/分析(HTAP)アプリケーションに最適です。もう1つはディスクベースの列ストアで、純粋に分析のみを行うアプリケーションに最適です。お客様は、OLTPおよびHTAPにおける行ストアの速度と予測可能性を高く評価しています。また、列ストアの驚異的な分析パフォーマンスと、RAMに経済的に収まる量をはるかに超えるデータを保存できる能力も高く評価されています。
しかし、お客様からは、行ストアの総所有コスト(TCO)の改善を求められています。これは、テーブルが大きくなると大量の RAM を搭載したサーバーをプロビジョニングする必要があり、コストがかかる可能性があるためです。また、高速 UPSERTS や一意制約など、OLTP のような機能を列ストアに追加するよう求められています。これに対し、私たちは、1 つのテーブル タイプを、利用可能な RAM をはるかに超える任意の大規模なデータセットの OLTP、HTAP、分析に使用でき、パフォーマンスと TCO をすべて最適化できるという将来ビジョンを開発しました。私たちはこれをSingleStore Universal Storage�と呼んでいます。
Universal Storageの最終的な目標は、明示的に定義された行ストアテーブルに必要なRAM容量が利用可能であれば、OLTPとHTAPのパフォーマンスが行ストアテーブルと同等になること、そして利用可能なRAM容量がそれよりも少ない場合でもOLTPのパフォーマンスが適切に低下することです。大規模なスキャン、結合、集計などを利用する分析においては、列ストアテーブルと同等のパフォーマンスを提供することが目標です。
RAMよりも大きなテーブルでOLTPをサポートする従来の方法は、Bツリーのようなレガシーストレージ構造を使用することです。しかし、これはパフォーマンスの大幅な低下につながる可能性があり、改善が必要です。ユニバーサルストレージのビジョンでは、現在のストレージ構造とコンパイル済みベクトル化クエリ実行機能のパフォーマンスと予測可能性を維持し、さらに向上させます。同時に、データベースソフトウェアにさらなる機能を組み込むことで、データベースの設計、開発、運用の複雑さとコストを削減します。
7.0 リリ��ースでは、上記で概説したお客様の要件を解決し、最終的には 2 つの異なる方法で「Universal Storage」のビジョンを実現することを目指しています。1 つは、スパース行ストアが同じ量の RAM でより多くのデータを保存できるようにすることで、シークに対して低い変動で優れたパフォーマンスを維持しながら TCO を削減することです。これは、スパース インメモリ圧縮によって実現されます。もう 1 つは、高度な同時読み取り/書き込みアクセスを可能にするシーク可能な列ストアをサポートすることです。はい、その通りです。シーク可能な列ストアです。これは矛盾ではありません。これを実現するために、ハッシュ インデックスと列ストアの新しい行レベルのロック スキーム、および列ストアの列の小さな部分を独立して効率的に読み取る方法であるサブセグメント アクセスを使用します。
以下では、SingleStoreDB Self-Managed 7.0におけるUniversal Storageのビジョン実現に向けた重要な第一歩を、どのように達成したかを説明します。そして、これはほんの始まりに過ぎません。
スパース行ストア圧縮
金融業界でよく見られる、NULL値の割合が高い幅の広いテーブルを持つお客様のTCOに関する懸念に対処するため、インメモリ行ストアデータを圧縮する手法を開発しました。この手法では、ビットマップを使用してどのフィールドがNULLであるかを示します。しかし、レコードの一部を固定幅フィールドの構造として維持することで、NULL値のデータ保存量を削減するというこの確立された手法に独自の工夫を加えました。これにより、コンパイル済みクエリの実行とインデックスシークは、最高レベルのパフォーマンスを維持できます。基本的に、レコードを2つの部分に分割します。1つは非スパースフィールドとインデックスキーを含む固定幅部分、もう1つはスパースとして指定されたフィールドを含む可変幅部分です。
NULLビットマップは、将来の拡張に備え、フィールドごとに1ビットではなく4ビットを使用します。空白やゼロなどのデフォルト値を圧縮する機能を追加できるほか、通常は固定幅のフィールドを可変幅フィールドとして保存する機能も備えています。例えば、bigintとして宣言された小さな整数は、8バイトではなく数バイトで保存できます。
次の図は、4つの列を持つテーブルでスパース圧縮がどのように機能するかを示しています。このテーブルには最後の3つの列がSPARSE列として指定されていま�す(最初の列は一意のNOT NULL列であるため、SPARSE列として指定されていないものとします)。最初の列がスパース列ではなく、最後の3つの列がスパース列である可能性があるという事実は、テーブルレベルのメタデータに記録されます。
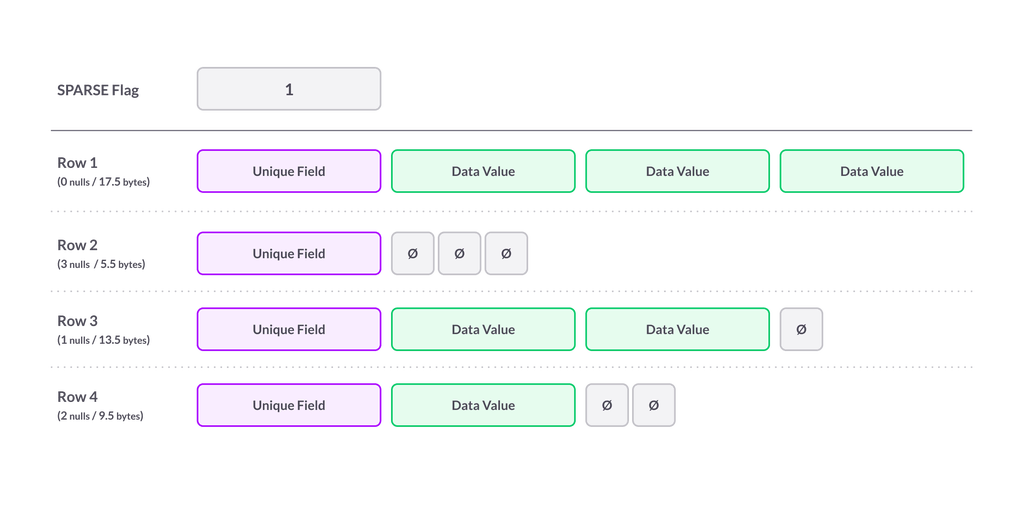
表では、ワイドフィールドの幅は32ビット、ナローフィールドの幅は4ビットを表しています。実際のスペース使用量はインデックスやストレージ割り当て構造の有無にも依存するため、簡単にまとめることはできませんが、この図はNULLになり得るスパースフィールドのスペース節約を視覚的に表すのに便利です。
SPARSE圧縮の最適な対象は、NULL値が半分以上を占めるワイドな行ストアテーブルです。以下に例を示します。
1CREATE TABLE t (2 c1 double,3 c2 double,4 -- …5 c300 double6) compression = sparse;
Specifying compression = sparse at the end of CREATE TABLE causes SingleStore to use sparse encoding for nullable structured fields, including numbers, dates, datetimes, timestamps, times, and varchars.
Using this table schema with SingleStoreDB Self-Managed 7.0, loaded with 1.05 million rows, of which two-thirds are NULL, we observe the following memory usage with no compression vs. roughly half the memory usage with sparse compression:
compression = sparse をCREATE TABLE の最後に指定すると、SingleStore は数値、日付、日付時刻、タイムスタンプ、時刻、varchar などの null 許容構造化フィールドにスパース エンコーディングを使用します。
このテーブル スキーマを SingleStoreDB Self-Managed 7.0 で使用すると、105 万行 (そのうち 3 分の 2 は NULL) がロードされ、圧縮なしの場合のメモリ使用量は次のようになりますが、スパース圧縮の場合はメモリ使用量が約半分になります。
| 圧縮�設定 | メモリ使用量 | 節約 (パーセント) |
|---|---|---|
| NONE | 2.62GB | N/A |
| SPARSE | 1.23GB | 53% |
つまり、3分の2がNULL値であるこの幅の広いテーブルでは、同じRAM容量で2倍以上のデータを保存できます。これはもちろん、TCOの大幅な削減につながるだけでなく、SingleStoreを活用してより大きな課題に取り組み、より多くのビジネス価値を生み出すことも可能にします。
この実験に使用された MPSQL コードは付録 A に記載されています。
注意:テーブルメモリ使用量を計算するための便利なクエリは次のとおりです。
1select database_name, table_name, format(sum(memory_use), 0) m2from information_schema.table_statistics3group by 1, 2;
これにより、各行ストア テーブルに実際に使用されたメモリが示されます。
高い同時実行性をサポートするシーク可能な列ストア
SingleStore でクラス最高のパフォーマンスと TCO を実現しながら運用分析や OLTP アプリケーションの処理範囲を拡大するには、前のセクションで説明したスパース行ストア圧縮方式が大きな効果を発揮します。ただし、この方法でもすべてのデータを RAM に保存する必要があるため、一部のユーザーにとっては TCO とスケールの制限につながります。運用アプリケーションを実行しながら行あたりの TCO を真に低減するために、列ストアも強化しました。(SingleStore の列ストアはディスクベースで、一部はメモリにキャッシュされるため、パフォーマンスが向上します。)
ユニバーサルストレージフェーズ1の2つ目の柱であるこの機能強化は、列ストアをシーク可能にすることです。一体どうやってそれが可能なのでしょうか?列ストアは高速スキャン向けに設計されており、OLTPスタイルのシークを十分に高速化することは考慮されていないのではないでしょうか?市場で入手可能な他の列ストア実装を参考にすると、そう思われるかもしれません。しかし、SingleStoreDB Self-Managed 7.0では、列ストアをシーク可能にし、高い同時実行性で細粒度で更新できるようにする新しいテクノロジーが導入されています。
まず、変更点を理解していただくために、列ストアの実装について少し背景を説明します。SingleStore列ストアテーブルは、セグメントと呼ばれる100万行単位のチャンクに分割されます。各セグメント内では、列は独立して保存されます。ファイルの連続した部分に保存することも、それ自体をファイルとして保存することもできます。保存された列のチャンクは列セグメントと呼ばれます。7.0より前のバージョンでは、1行のフィールドにアクセスするには、そのフィールドの100万行の列セグメント全体をスキャンする必要がありました。
サブセグメントアクセス
SingleStoreDB Self-Managed 7.0 では、システムが行のデータの位置を計算し、その行を具体化するために必要な列セグメントの部分のみを読み取ることで、列ストア内の行へのアクセスを高速化します。これはサブセグメント アクセスと呼ばれます。このアクセスでは、最大数千行のデータの読み取りが必要になる場合がありますが、セグメントの百万行すべてを読み取ることはありません。セグメント内の行のオフセットが分かれば、通常はその行と隣接する行の一部のみを取得すれば済みます。ランレングス エンコードされた列など、圧縮戦略の性質上、列を具体化するために取得する必要があるデータのバイト数はごくわずかです。これにより、効率的なシークも可能になります。
下の図は、セグメント内の特定の位置にある 1 行または数行を見つけるために、セグメントのファイル データの一部だけを読み取る必要があることを示しています。

サブセグメントアクセスでは、セグメント内の行位置が分かれば、シークスタイルのアクセスによって行を効率的にマテリアライズできます。そこで問題となるのは、どのようにして行位置を把握し、それを効率的に行うかということです。一つの方法は、単一の列をスキャンしてフィルターを適用し、フィルターに一致する行番号を記録することです。これはSingleStoreでは非常に高速に実行できますが、エンコードされたデータに対する操作とベクトル化を利用するため、最終的には行数に比例した時間がかかる可能性があります。
列ストアハッシュインデックス
選択的クエリをさらに高速に実行するには、インデックスが必要です。そのため、SingleStoreDB Self-Managed 7.0では、列ストアにハッシュインデックスが導入されました。列ストアテーブル内の任意の列にハッシュインデックスを作成できます。これにより、これらの列に対するフィルターをインデックスを使用して解決できます。選択的フィルターを解決するためのハッシュインデックスのシークにより、スキャンよりも桁違いに高速な速度で、条件に該当する行の位置を特定できます。行の位置が判明したら、新しいサブセグメントアクセス機能を使用して、クエリで参照される各列をシークし、条件に該当するレコードのデータを取得します。
複数列のフィルターは、インデックス交差を介して複数のハッシュ インデックスで解決することもできます。つまり、複数のインデックスからの rowid リストを交差させて、最終的な適格な rowid セットを生成します。
列ストアの細粒度ロック
高度に選択的なOLTPスタイルのクエリを列ストアで高速に処理できるようになった今、毎秒数百、あるいは数千ものトランザクションを効率よく読み書きするアクセスを阻むものは何でしょうか?もちろん、こうした細粒度の読み書きトランザクションを待機させるものなら何でも構いません。では、何を待機させるのでしょうか?それは、互いのトランザクションです。
SingleStoreDB Self-Managed 6.8以前では、100万行単位のセグメント単位でロックを行うため、列ストアの更新が他の更新と競合し、待機が発生する可能性がありました。この粒度はやや粗いため、全体的な同時実行性が制限される可能性があります。7.0では、列ストアの行レベルロックにより、同時実行性が大幅に向上しました。
パフォーマンスの向上
ハッシュインデックスによる列ストアシークのパフォーマンスを測定するために、10億7400万行(1024 x 1024 x 1024)のテーブルを作成しました。このテーブルには2つの列があり、各列にハッシュインデックスが設定されています。2つの列の順序は全く異なり、列内の各値は一意かそれに近い値です。このテーブルのスキーマは次のとおりです。
1create table f (2 a bigint,3 b bigint,4 shard key(a),5 key(a) using clustered columnstore,6 key(a) using hash,7 key(b) using hash8);
探している列
| テーブルサイズ(数百万行) | 実行時間(ミリ秒)、6.8、ハッシュインデックスなし | 実行時間(ミリ秒)、7.0、ハッシュインデックス付き | スピードアップ(倍) | |
|---|---|---|---|---|
| a | 1,074 | 6.70 | 2.46 | 2.72X |
| b | 1,074 | 271 | 2.54 | 107X |
列ストアキー(a)で順序付けされていない列bのシーク速度が107倍も劇的に向上していることに注目してください。これは、ハッシュインデックスとサブセグメントアクセスの相乗効果を示しています。重要なのは、列bのシーク時間が、バージョン6.8では高度な同時実行を行うOLTPアプリケーションには遅すぎる(271ミリ秒)のに対し、ハッシュインデックスを使用したバージョン7.0ではOLTPに十分な速度(2.54ミリ秒)にまで改善されていることです。これにより、列ストアテーブルで実行できるワークロードの種類が大幅に広がります。
これらのテストに使用したMPSQLコードは付録Bに記載されています。テーブルに列を追加するなど、テストのバリエーションを試すこともできます。もちろん、列を追加すると各列にアクセスする必要が生じるため、シーク時間は遅くなります�。しかし、数十列の場合でも、ハードウェアによってはシーク時間が1桁ミリ秒に抑えられるため、多くの同時実行アプリケーションでボトルネックとならない程度には十分です。さらに、数百列の非常に幅の広いテーブルであっても、クエリが1列から数十列を選択する場合、サブセグメントアクセスとハッシュインデックスを使用することで、行の検索時間を1桁ミリ秒に抑えることができます。
設計と運用の改善
SingleStore は、行ストアテーブルと列ストアテーブルの両方を単一のデータベースソフトウェアで提供し、JOIN などの操作が 2 つのテーブルタイプ間でスムーズに機能します(SingleStoreDB Self-Managed 7.0 では、さらにスムーズに機能します)。これにより、競合ソリューションよりもデータベースの設計と操作が簡素化されます。
しかし、SingleStore を使用したとしても、様々な問題を解決するためにどのテーブルタイプ、またはテーブルタイプのセットを使用するかを選択するのは依然として複雑です。また、使用される個別のテーブルや異なるテーブルタイプが増えるにつれて、操作はより複雑になります。
多くのユースケースにおいて、Universal Storage はデータベース設計プロセスを簡素化し、結果として得られる実装に必要な運用作業のレベルも低減します。これらの改善は、Universal Storage Phase 1 / SingleStoreDB Self-Managed 7.0 で提供される機能強化によって大幅に実現されており、Universal Storage が将来のリリースでより完全に実現されるにつれて、さらに拡張される可能性があります。
これらの改善がお客様にどのような影響を与えるかは、もちろん、お客様が達成したい具体的な目標によって異なります。一般的に、改善には以下のようなものがあります。
- 行ストアはより多くの要件に対応します。OLTPやHTAPの作業を行うお客様は、必要なRAM容量が高すぎる、あるいは現実的ではないため、ニーズの一部または全部に列ストアを使用せざるを得ない場合があります。Universal Storage Phase 1のNULL圧縮は非常に有効で、前述の通り、多くのお客様で2倍の圧縮率を実現しています。行ストア圧縮の今後の改善により、このメリットはさらに拡大される予定です(IntelのOptaneメモリもその一助となるでしょう)。
- 列ストアはより多くの要件に対応します。行ストア型の問題を解決したいものの、コストや実用性の観点から列ストアを使用せざるを得ないお客様、あるいは、一部の実行不可能なほど遅い操作を除けば列ストアが適しているお客様は、列ストアのパフォーマンスが大幅に向上することを実感していただけるでしょう。この改善はUniversal Storageの初期実装において非常に顕著であり、将来のバージョンでもさらに向上する余地があります。
- 行ストアと列ストア間の複雑な運用を回避できます。お客様は多くの場合、新しいアクティブデータを高速化するために行ストアに格納し、コスト上の理由から古くなったデータを列ストアに移動する必要がありますが、これはアプリケーションの複雑さを増大させます。あるいは、一部の操作のためにデータのサブセットを行ストアの論理テーブルに格納し、広範な分析のためにデータセット全体を列ストアに格納することで、テーブルタイプ間で大量のデータが重複することになります。Universal Storageを使用すれば、複数のテーブルタイプを使用する必要性がなくなることがよくあります。SingleStoreが複雑なテーブルアーキテクチャを必要としていた従来のニーズをデータベースソフトウェアの機能強化で吸収するため、将来のバージョンではこの必要性がさらに軽減されるでしょう。
まとめと今後の展開
SingleStoreDB Self-Managed 7.0 では、OLTP、HTAP、分析ワークロードでより多くのデータを効率的に処理できるようにする 2 つの主要なカテゴリの機能強化が導入されています。
- 複数のアクセスパスで非常に高速かつ予測可能な行検索時間を必要とするOLTPスタイルのアプリケーションのTCOを改善するためのスパース行ストア圧縮、および
- サブセグメント アクセス、ハッシュ インデックス、および列ストア テーブルの同時実行性の向上により、使用可能な RAM よりも大きい列ストア テーブルで、より多くの OLTP スタイルの作業を効率的に実行できるようになります。
7.0 用に構築したユニバーサル ストレージ機能は、将来のリリースで想定している次のような追加機能への初期投資です。
- 既存の列ストアを進化させたハイブリッド行/列ストアテーブルでは、更新可能なインメモリ行ストアセグメントに使用するRAMの量を調整できるほか、データのあらゆる部分に対してよりきめ細かなインデックス制御が可能で�す。これにより、お客様がアプリケーション制御下でデータを2つの異なる方法で保存する必要がなくなり、アプリケーション開発が簡素化されます。
- 列ストアの一意のハッシュインデックスと一意の制約
- 列ストア上の複数列ハッシュインデックス
- 列ストア上の順序付きセカンダリインデックス
- 列ストアのシークの結果をキャッシュする行ストア
- 列ストアの更新可能な行ストアセグメントのサイズの自動調整
- 単純にファイルシステムのバッファプールに依存するのではなく、SingleStore によって直接管理される列ストア バッファプール
- ゼロと空白の行ストア圧縮、および小さな値の可変幅エンコード
ご覧のとおり、SingleStoreDB Self-Managed 7.0リリースは、Universal Storageのビジョンの大きな部分を実現します。SingleStoreのスピード、パワー、そ�してシンプルさは今後もさらに進化し、向上していくことが期待できます。SingleStore Universal Storageは、まさにあらゆるものを管理するストアとなるでしょう。
SingleStore の特許取得済みUniversal Storage機能の全容を知るには、シリーズのパート 2、パート 3、パート 4をお読みください。
付録A: SPARSE圧縮測定のためのデータ生成SP
1set sql_mode = PIPES_AS_CONCAT;2 3-- load t using SPARSE compression4call buildTbl(300, 0.666, 1000*1000, "compression = sparse");5-- load t with no compression6call buildTbl(300, 0.666, 1000*1000, "compression = none");7 8delimiter //9create or replace procedure buildTbl(numCols int, sparsePercent float, nRows bigint,10 compression text)11as12begin13 drop table if exists t;14 call createTbl(numCols, compression);15 call loadTbl(numCols, sparsePercent, nRows);16end //17 18create or replace procedure createTbl(numCols int, compression text) as19declare stmt text;20begin21 stmt = "create table t(";22 for i in 1..numCols - 1 loop23 stmt = stmt || "c" || i || " double, ";24 end loop;25 stmt = stmt || "c" || numCols || " double) " || compression || ";";26 execute immediate stmt;27end //28 29delimiter //30create or replace procedure loadTbl(numCols int, sparseFraction float,31 nRows bigint) as32declare stmt text;33declare q query(c bigint) = select count(*) from t;34declare n int;35begin36 stmt = "insert into t values(";37 for i in 1..ceil(sparseFraction * numCols) loop38 stmt = stmt || "NULL,";39 end loop;40 for i in (ceil(sparseFraction * numCols) + 1)..numCols - 1 loop41 stmt = stmt || "1,";42 end loop;43 stmt = stmt || "1);";44 execute immediate stmt;45 n = scalar(q);46 -- Double table size repeatedly until we exceed desired number47 -- of rows.48 while n < nRows loop49 insert into t select * from t;50 n = scalar(q);51 end loop;52end //53delimiter ;
1create database if not exists db1;2use db1;3drop table if exists f;4 5-- hash indexes on columnstores6create table f(a bigint, b bigint,7 shard key(a), key(a) using clustered columnstore, key(a) using hash,8 key(b) using hash9);10/*11-- Create table without hash indexes, for comparison12create table f(a bigint, b bigint,13 shard key(a), key(a) using clustered columnstore14);15*/16 17-- This will keep increasing the size of f until it has a t least n rows.18-- the b column is a hash function of the a column and will19-- be unique for ascending20-- a values 1, 2, 3, ... up until 941083987-1. The data in the b column will21-- be in a different order than the a column. So you can seek on a value of22-- a and a value of b separately to show the benefit of hash indexes without23-- worrying about whether the sort key on a is skewing performance on seeks24-- on column b.25delimiter //26create or replace procedure inflate_data(n bigint) as27declare q query(c bigint) = select count(*) as c from f;28declare tbl_size bigint;29begin30tbl_size = scalar(q);31if tbl_size = 0 then32 insert f values(1, 1);33end if;34while (tbl_size < n) loop35 insert into f36 -- use of two prime numbers in this formula for b37 -- guarantees unique b for a=1..941083987-138 select a + (select max(a) from f), ((a + (select max(a) from f)) * 1500000001) % 94108398739 from f;40 tbl_size = scalar(q);41end loop;42optimize table f flush;43echo select format(count(*), 0) as total_rows from f;44end //45delimiter ;46 47-- load the data48call inflate_data(1024*1024*1024);49 50-- try some seeks - should take single-digit milliseconds in 7.051select * from f where b = 937719351;52select * from f where a = 2206889;53 54-- show non-sortedness of column b when ordered by a.55select * from f order by a limit 100;56select * from f order by b limit 100;57 58delimiter //59create or replace procedure measure_q(stmt text, n int)60as61declare62 q query(a bigint, b bigint) = to_query(stmt);63 a array(record(a bigint, b bigint));64 end_time datetime(6);65 start_time datetime(6);66 d bigint;67begin68 start_time = now(6);69 for i in 1..n loop70 a = collect(q);71 end loop;72 end_time = now(6);73 d = timestampdiff(MICROSECOND, start_time, end_time) as diff_us;74 echo select format(d/n, 0) as avg_time_us;75end //76delimiter ;77 78-- measure seek time by seeking 100 times and taking the average,79-- seeking on b, then a columns independently80call measure_q("select * from f where b = 937719351", 100);81call measure_q("select * from f where a = 2206889", 100);










