
.svg?width=200&disable=upscale&auto=webp)
Heap Takes Aim at the Enterprise with Real-time Performance and Big-Time Cost Reduction via SingleStore on Azure
“We were able to build more confidence in our ability to provide a platform we could grow with that could operate cost-effectively at scale. SingleStore struck the right balance of performance, cost, expressiveness and partnership.”
Molly Shelestak
Principal Product Manager, Heap by Contentsquare
Annual cost savings
$2M
Can now support 10x more data
10x
Faster ingest
60x
Reduced cost of goods sold by 25%
-25% COGS
Sub-second average query duration
<1sec
3M events/sec; 1B events/mo.
3M; 1B
Heap by Contentsquare is a digital insights platform that offers complete understanding of customers’ digital journeys. With Heap, companies can use quantitative and qualitative insights to make data-informed decisions on how to improve their products, and thus quickly improve conversion, retention, and customer delight.
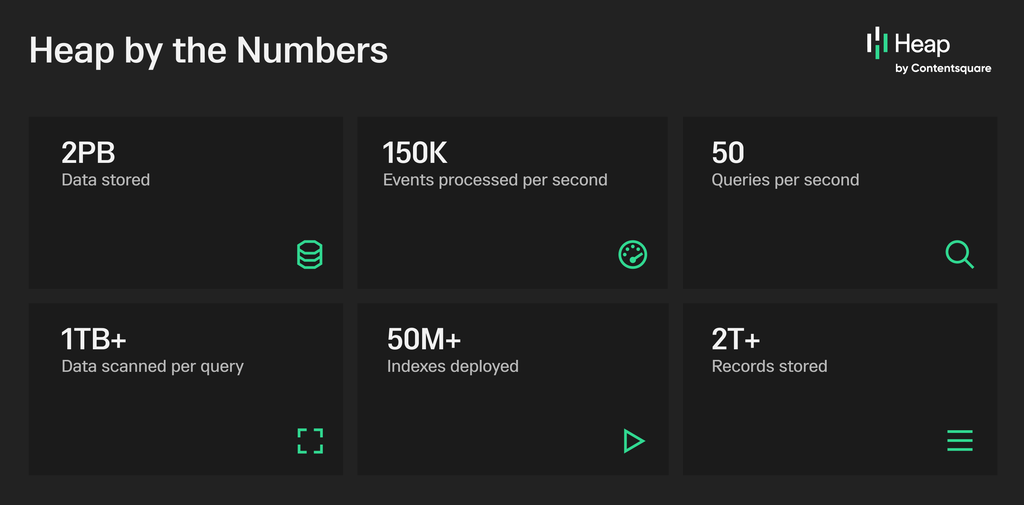
Heap by the Numbers
The platform provides interactive behavioral analytics, session replay, and managed ETL to the data warehouses of its customers including Crunchbase, E*TRADE, esurance, Freshworks, HelloSign, Lending Club, Northwestern Mutual, Redfin, and many more. Unlike traditional analytics, where you have to make a tracking plan for specified interactions and require an engineer’s time and expertise to implement that plan, Heap collects all of that data for you automatically.
For example, if you want to see how logins are changing over time, you can isolate login events — events that have a click on a button with text login — and with Heap you can quickly access the complete historical data set on it.
Challenges/Goals
Heap adds a very simple tag to its customers’ web and mobile presence to track all customer behavior, and this creates petabytes of data. Heap supports true complex analytics queries; a query may scan billions of data records. The team runs a high compression ratio, 80-90%. In short, Heap is a demanding data product.
Heap was built on PostgreSQL with a CitusData layer on top of it to provide distributed PostgreSQL, but the team ran into problems with its legacy architecture because Postgres and Citus are designed to serve as transactional databases, whereas Heap’s core value is providing rapid analytical insights to its customers. The team worked around this with indexing strategies, but faced technical and business limitations for which there were no real workarounds:
- Coupled Storage and Compute = Limited Analytics. PostgreSQL couples storage and compute, which means, for example, that an operational workload running in the background must run on the same hardware and in the same database as queries its customers are running that are production-critical and customer experience-impacting. As a result, for years Heap had not built new features and in fact, entire classes of analyses, such as account-based analysis, that it wanted to build.
- Not Optimized for Shuffling A Lot of Data. The system was not optimized for shuffling large amounts of data, so the team built the system in a way that simply omitted features because those features would have required large shuffles.
- Indexing Helps Read/Hurts Write/Increases Cost. The team developed a unique indexing approach as a coping strategy, but while indexing is great on the Read path, it comes at a cost on the Write path: write throughput was a challenge. With tens of millions of indexes running across Heap, keeping them all up to date was expensive.
- High Maintenance Effort and Cost. Heap was spending almost $3 million per year on infrastructure costs alone, and that, coupled with high maintenance requirements, meant that its cost of goods sold (COGS) was hurting margins.
The combined effects of these issues with its existing data infrastructure had led to Heap losing existing revenue through customer churn and what it calculated as $5 million in new revenue in two recent quarters alone as its data limitations prevented it from pursuing enterprise customers.
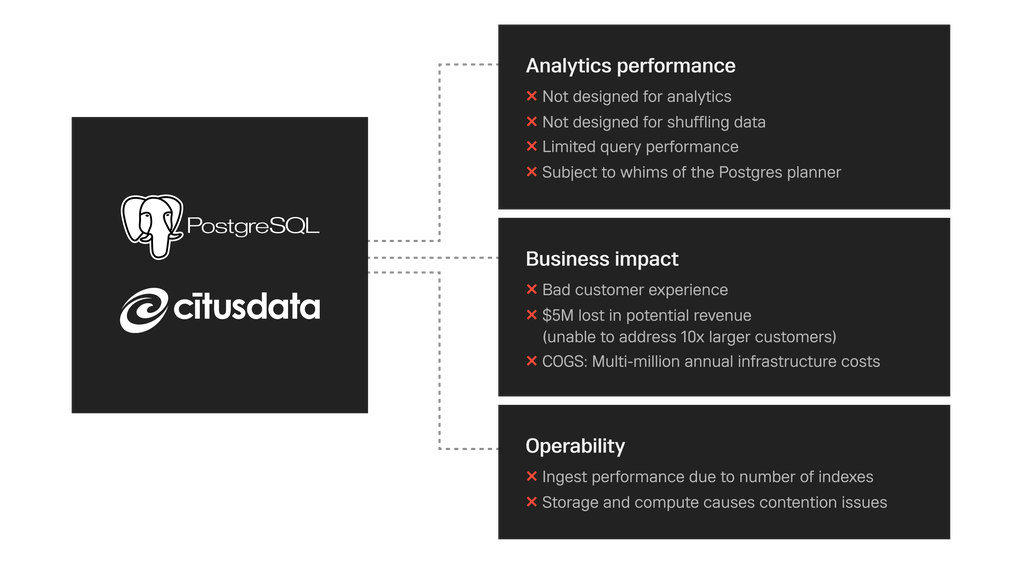
Heap’s Core Drivers Toward a New Solution
Heap needed a next-generation database to meet its SLAs, support large enterprise customers, scale as they grow, and partner with them. Heap’s data costs were growing linearly with event volume and size, and that does not translate directly into added value or revenue, so the company needed a cost-effective solution.
Technology Requirements
Heap wanted a more modern, columnar database that decoupled storage from compute, one designed for high-throughput analytics.
Core Specifications
- Data Type and Size: large, sparse JSON objects; 2+ petabytes
- Ingest: 500,000 rows per second
- 10X Scale Support: ability to support customers at 10X the existing size limitations; this translates into one billion events per month for a given environment and three million events per second at peak load
- Shuffle Ops-Ready: to execute those large-scale shuffle operations, resolve user identity at query time, and perform other non-user-based analyses such as account-based analysis, without negatively impacting overall system performance
- GDPR Compliant: Heap is moving into the EU market, with a new data center in-region, and the new system had to be GDPR-compliant to quickly provide data portability, data erasure/right to be forgotten requests, and more
Query Requirements
- Query Speeds: 3-9 seconds on funnel queries
- End-to-End Latency: from data creation to queryability in <5 minutes
- Concurrency: 40 concurrent queries at peak
- P95 Response: 9000ms (9sec) required, 3000ms (3sec) target
- 10X Scale Concurrency: 100 concurrent queries at peak
- 10X Scale P95 Response: 15000ms (15sec) required, 9000ms (9sec) target
“Expressiveness was key, to handle all of those complex queries and also to enable us to build out new features,” said Molly Shelestak, Principal Product Manager, Heap by Contentsquare. “Developer experience was essential: we wanted to make it easy for any developer to write new types of analyses.”

Molly Shelestak, Principal Product Manager, Heap by Contentsquare
Performance is challenging as you collect more and more data, and Heap needed to be able to provide sub-second query response even as it scaled the system to support its planned 10x data growth.
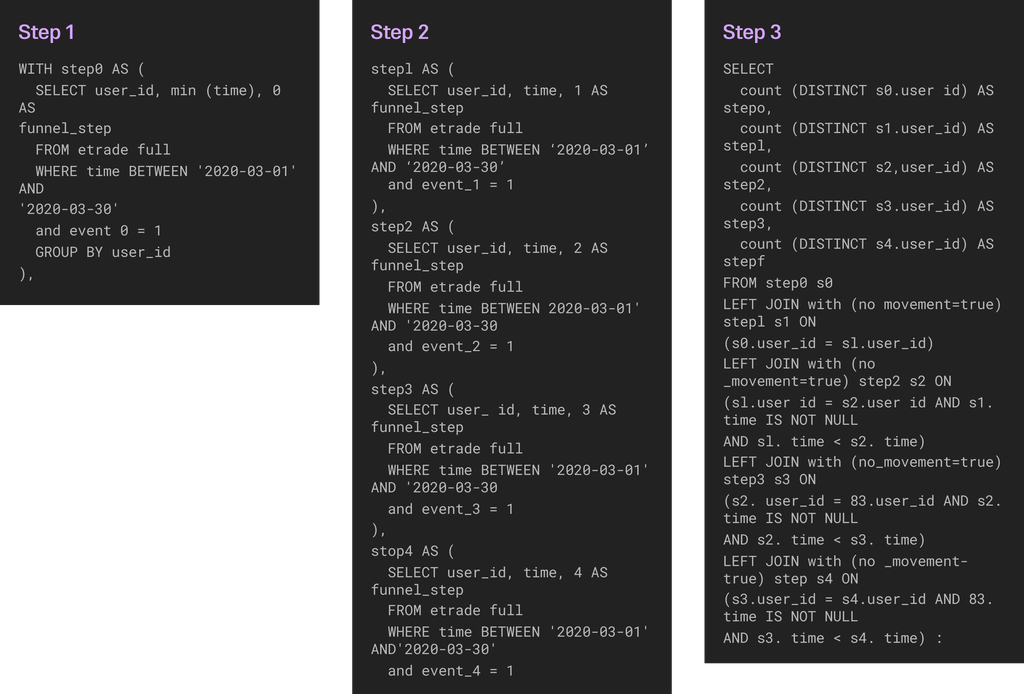
Example of a Funnel Query in Heap
Why SingleStore
Heap undertook an extremely thorough evaluation of a dozen databases including Dremio, Druid, Firebolt, Snowflake and Vertica. A number of them were knocked out immediately because like PostgreSQL, they couple compute and storage. “Others solely offer a managed service,” said Shelestak, and Heap needs to be able to host its own solutions. Some fell short because they cannot support performant shuffle operations; others because they offer no UDF support.
“A lot of OLAP data warehouses are designed with traditional OLAP workloads in mind, where everything is denormalized into a single table and you can follow the MapReduce paradigm. If you can confine your workloads to these types of queries, these systems can do ok,” she added, “but they are not capable of supporting distributed joins, or they deliver poor performance when it comes to things like repartitioning.”
Since complex analyses can be tough to express performantly in SQL, Heap needed the ability to put procedural code in the database and run it from a SQL interface. Some analytics systems couldn’t do that at all, or could but it was a huge hassle to try to implement.

Heap’s Database Selection Process
There was also the issue of cost.
“We store a lot of data, and the pricing of some of these other tools, particularly managed services, was going to hurt margin and force us to raise prices."
And Then There Were Two: SingleStore and Snowflake
When the dust cleared, only two remained: SingleStore and Snowflake. Snowflake performed well on many queries, but its support for JSON was not strong enough and its ingest was not fast enough. “SingleStore’s performance shone through in the PoC, delivering 10x better performance than our current system,” said Shelestak, “and with SingleStore we can execute distributed joins so we can resolve identity on Read and a range of non-user analyses.”
SingleStore Ticked All the Tech Boxes…
In the words of the Heap team, SingleStore ticked all the boxes, including:
- Columnstore, which is the default table type in SingleStore.
- Decoupled storage and compute with its Unlimited (Bottomless) Storage
- Fast ingest
- Low latency analytical queries
- Seekable JSON support for analytics on sparse objects
- Support for 10X data size
“SingleStore had performed better than competitive databases in previous testing,” said Shelestak. “Its underlying primitives are blazing-fast. Then with Bottomless Storage it solved our main structural issue of coupled storage and compute."

Why Heap Chose SingleStore
“SingleStore had performed better than competitive databases in previous testing. Its underlying primitives are blazing-fast. Then with Bottomless Storage it solved our main structural issue of coupled storage and compute.”
Molly Shelestak
Principal Product Manager, Heap by Contentsquare
…and Closed the Deal with Cost-Effective Performance
Heap found Snowflake too expensive. Its pricing model was opaque and it was hard for the team to get an idea of what cost would look like. “We had little control over those costs, so we didn’t feel confident we could build a cost-effective solution right out of the gate,” said Shelestak, much less at (10X) scale.
“We were able to build more confidence in our ability to provide a platform we could grow with that could operate cost-effectively at scale for those large-data-volume customers,” she added. “In the end, SingleStore struck the right balance of performance, cost, expressiveness and partnership.”
Solution
Heap is now built on SingleStore Self-Managed running on Azure. SingleStore is the query layer on top of Heap’s data system and the data lives in SingleStore. When a customer runs a query from Heap, the App sends a JSON payload to the App Server, the App Server compiles to SQL and fires it off to SingleStore, the results come back, the App server post-processes and sends it back to the Front End.
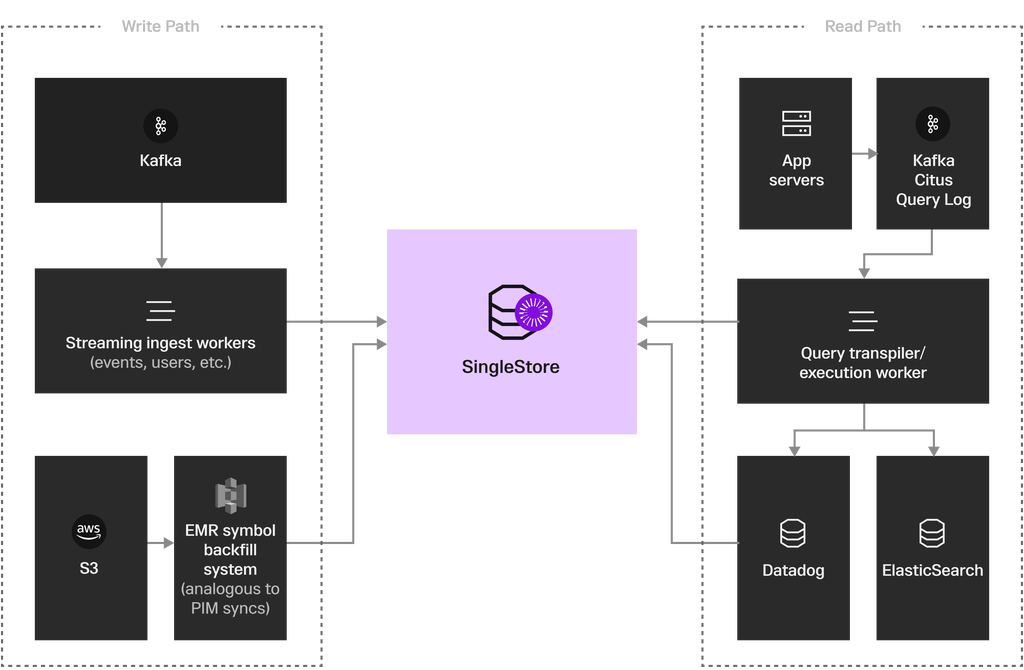
Heap NextGen Phase 2 Architecture Overview
Previously, PostgreSQL was both the Query Layer and Fundamental Durability Layer. As shown in Heap’s High-Level End State Architecture, now a shared Data Lake is the shared Durability Layer and SingleStore is the Query Layer serving all interactive queries because they must run extremely fast to meet the needs of the business.
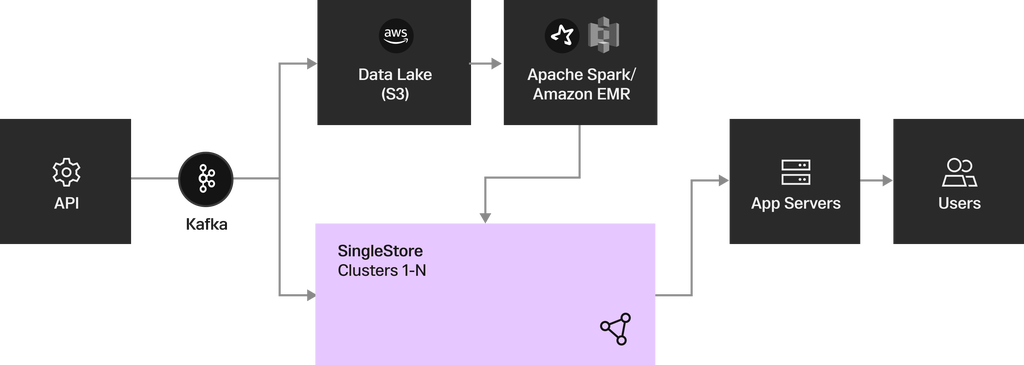
Heap’s High-Level End State Architecture
Customers create some definitions, e.g., “This particular slice of my data is interesting,” that Heap cannot serve quickly with hash indexes because they require Regex or something else that would run slowly. So the team is now routing those requests through a Materialization system that kicks off a Spark job to get all the relevant records from its Data Lake and flow then into SingleStore to benefit from SingleStore’s blazing-fast ingest throughput.
Heap migrated its multi-petabyte data set from its Data Lake into SingleStore. “SingleStore has made it super-easy to switch to a multi-cluster model,” explained Shelestak. With PostgreSQL, Heap has had one big cluster that served nearly all of its customers, but switching to multi-cluster:
- 'Limits the blast radius' if one customer is running a lot of really expensive queries and causing contention issues
- Accelerates Heap’s expansion in the EU by letting it create clusters in-region for customers who need to store their data solely in the EU
Heap commended SingleStore for its ongoing partnership from day one, providing guidance during the initial phase, helping debug issues, being on call to triage issues during off-hours. Now in the data migration phase, “They continue as incredible partners, including building features to enhance some of our features including our JSON workloads,” said Shelestak.
Heap has deployed SingleStore on a 40-node cluster that provides high I/O performance, low latency, minimal latency variability, and security with always-on encryption.
Outcomes
As shown in the adjacent table and discussed throughout this story, Heap’s expertise and savvy as a data innovator is now delivering success after success:
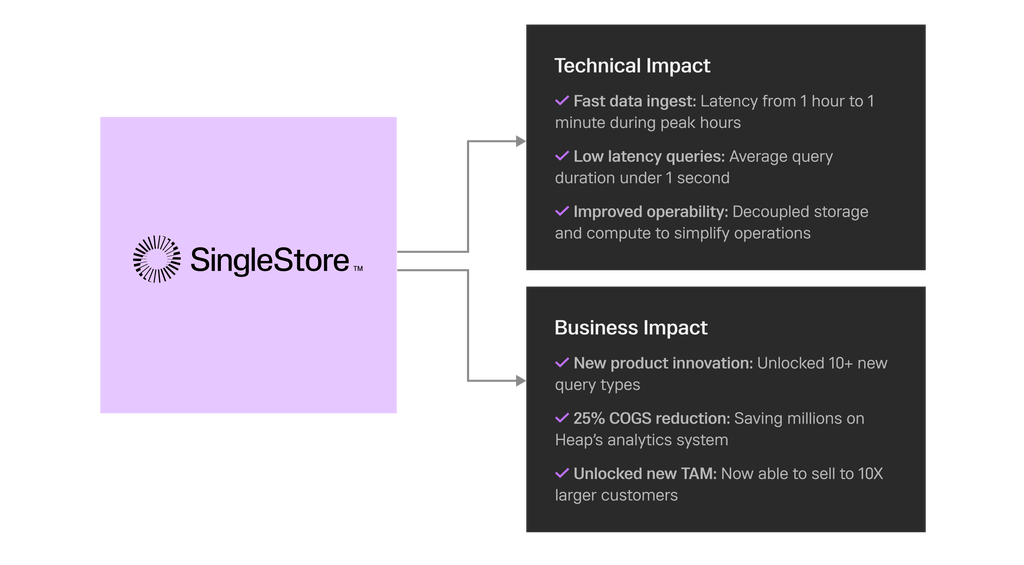
Heap Results with SingleStore
- $2 million in annual cost-savings
- The ability to support 10x more data so it can now safely and effectively sell to the large enterprise customers that were beyond its reach before
- A 25% reduction in cost of goods sold, which, like the $2 million, goes directly to the bottom line
- 60x faster data ingest during peak hours, from 1 hour to 1 minute
- Sub-second average query duration
- Successfully handling three million events per second and a billion events per month
Supporting 10 times more data also means Heap can be confident that its days of losing millions in potential revenue every few months because its legacy infrastructure wasn’t up to the job are over. Heap has future-proofed its platform with scalability and greater predictability.
“Teams are already unblocked and working on new types of analyses to support our customers,” said Shelestak. “We can now provide a cost-effective solution for our larger customers, a new COGs model, and new pricing: across the board we’re doing a lot better with SingleStore.” Heap is also looking at SingleStore as a replacement for its existing Apache Flink solution for stream and batch processing.
Heap is recognized globally for its quality of insights that help companies optimize their products, and it now has a data infrastructure that supports its enterprise vision. Its customers, who can now access the real-time insights they need to compete in today’s economy are happier, and that means higher NPS Scores for Heap. As Heap’s high-performance reputation precedes it in the market, that also improves close rates for the Heap sales force, which is valuable at any time but particularly with Heap making its move into the EU market and supporting that new data center.
SINGLESTORE FAST FACT / Heap is one of our core customers who inspired SingleStore to double down on JSON and introduce SingleStore KAI™. The JSON enhancements in the SingleStore 8.0 Release were based in part on Heap’s workload.
SingleStore is helping companies compete and win across every vertical. Learn more →