Data
Integration
Native support for seamless ETL/CDC between various sources and targets
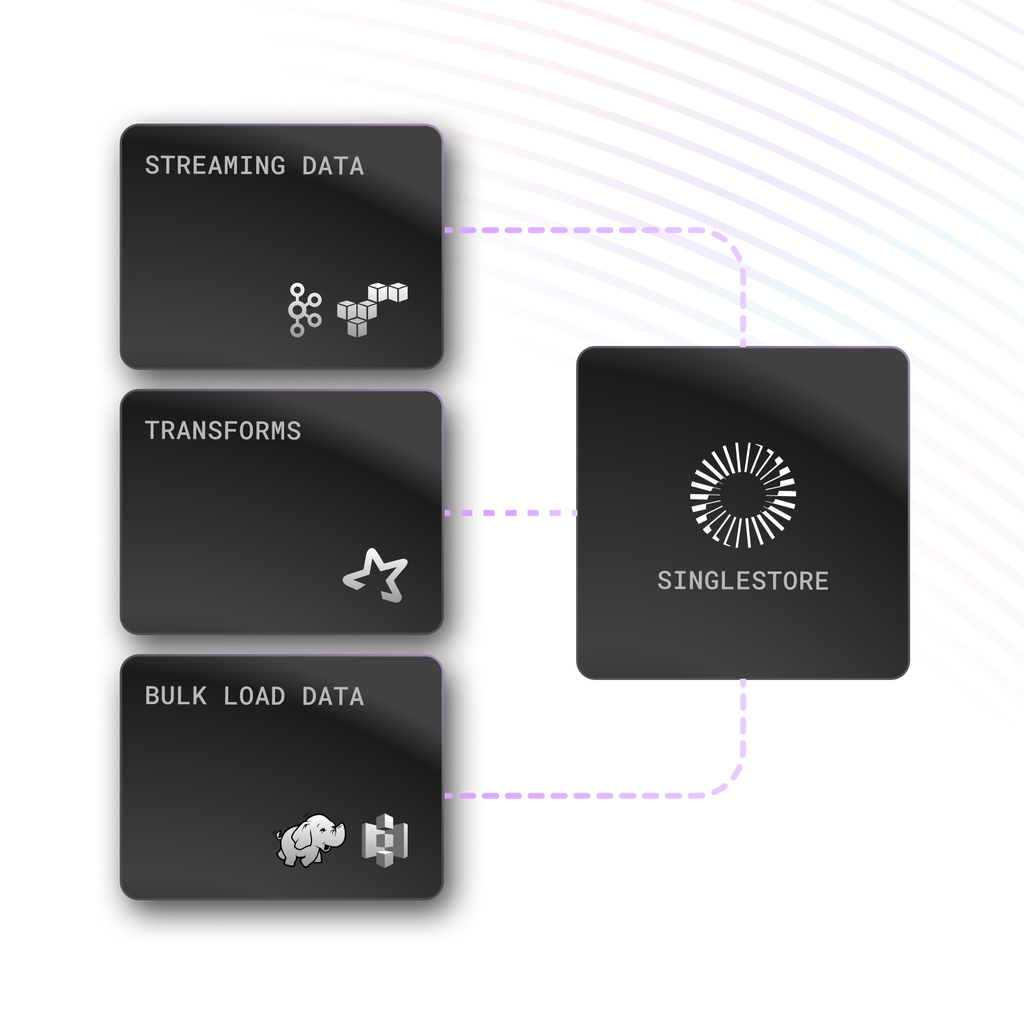
Rapid data ingestion (with optional transforms) from multiple data sources including Kafka, Amazon S3, HDFS and Iceberg tables, powered by SingleStore Pipelines.
Continuously load millions of events per second, in parallel, natively in our platform.
No external tools needed
SingleStore Pipelines are robust, scalable, highly performant and support fully distributed workloads
Support for JSON, Avro, Parquet and CSV data formats

Michael Zimberg
CTO, Digital Asset Research
Some batches are running at around seven milliseconds. They're so unbelievably fast. SingleStore enables us to be thousands of times faster. Our platform can do everything we need it to in less than a second.Read customer story
Drastically simplify the job of developers by monitoring a source folder or Kafka queue, automatically loading events as they arrive.
Frictionless snapshot data load and Change Data Capture (CDC) from MySQL and MongoDB® with SingleStore Pipelines.
Other database sources are supported with third-party tooling.

Ingest data from and write back to Iceberg tables — in real time, with no additional tooling required. SingleStore’s native integration provides super low-latency analytics on your lakehouse data.
Unlock real-time insights on your data lake and commercial lakehouse data that was previously inaccessible.
Automatically manage schema evolution/changes and updates, ensuring changes in Iceberg tables are reflected in your SingleStore database without manual intervention.
Ingest from Iceberg tables
Zero ETL ingest from Iceberg tables without requiring additional ETL tools
External tables from Iceberg (soon)
Analyze Iceberg data directly with SQL queries — without creating a local copy
Data sharing to Iceberg (preview)
Write-to-Iceberg tables with support for Glue catalog, enabling bi-directional data
Check out some of our Jupyter Notebooks showing how data integration works on SingleStore


Start building today
Your intelligent apps are about to get even better