

SingleStore is a hybrid relational database geared toward data-intensive applications that runs on-prem, or in a private or public cloud. What is a data-intensive application, and why use SingleStore even if I don’t think I have one?
Unfortunately, the ‘why’ becomes difficult because several database vendors lean into the idea of data intensity — and messaging around the fastest databases, best performance and more become even more complicated when analytic and reporting tool vendors add a data front end in their offering. This blog post explores what a data-intensive application means, what makes SingleStore unique and why you should start using SingleStore today.
What Is Data Intensity?
When you hear the phrase ‘data intensive,’ your first thoughts might be “what does data intensive mean”? Or even, “I don’t think I have a data-intensive application.”
The truth is, a lot of your existing applications should be data intensive — but limitations of database and hardware technology have guided architectural decisions every step of the way. Back in the ‘80s, I worked on a server with a 50MB drive. We had to severely limit what information we wanted to capture. When I started in data warehousing, the company I worked for specialized in successfully building multi-TB, customer-centric data warehouses. Although this was an unusual feat in 1998, what made us successful was our architectural decisions not only on what we could include, but also what we should exclude from the data warehouse. Updates were run in a weekend batch, with hopes it would be ready for Monday morning. That logic is still being applied today!
We know that data comes in real time to most of our record keeping systems and applications, but we still use the same approach to our architecture. We limit our designs around bottlenecks. We don’t bring in too much data so our load process doesn't choke. We report on stale data since our processes are batched to our analytics and reporting databases. We limit access so as not to overload the database. We archive data because drives fill up and are expensive. We create aggregate tables and cubes in batches at fixed periods of time, because reporting on large volumes of data is just too slow. We extract, transform and load data multiple times going from our source systems to operational data stores, to data warehouses to data marts, to cubes to data lakes — and then we flatten our data.
We have created this complicated architecture to overcome speed limitations with our storage and retrieval process. I worked for a large online retailer and assisted on a project a few years ago for hourly reporting. We ended up having a completely separate process for the hourly reporting, since our data came in nightly batch runs. Not only that, but it took 10 - 15 minutes into each hour before you could see the previous hour’s data. And, users could only see the results for half the company.
Even if you’re able to work around these limitations, our need for data-intensive applications is in our future. Five years ago it would have been inconceivable to track a UPS truck driving through a neighborhood. Now, I watch it right on my phone. The expectation for real-time access to the things that impact our day-to-day only continues to grow. And if we take out the limitations of technology, we start to see how we can better interact with our customers and suppliers — starting with a database that handles data-intensive applications, and sets the foundation for the future.
Get the C-Suite’s Guide for Data-Intensive Applications
We can start now, phasing in applications that are limited by current designs. We can augment our existing application where data-intensive apps demand it — building new applications, and modernizing what we have. This allows us to seamlessly move into the next generation that is data intensive. It also removes the need and associated costs of migrating later, handling everything under pressure to choose a database, programming language and deployment environment.
The other consideration for SingleStore implementations is to have a lower total cost of ownership (TCO) on less intensive applications — allowing budget to be redirected not only from the database, but also the cost of the infrastructure (servers) and to better utilize your organization’s manpower.
Recognizing Data-Intensive Applications: 5 Key Criteria
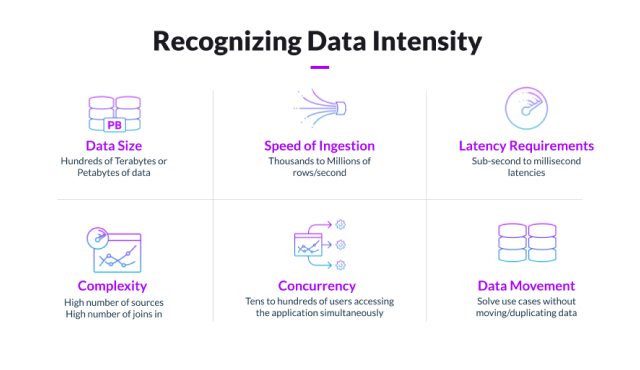
So, now you know what data intensity means. But what makes up a data-intensive application? Here are five criteria to consider:
- Low latency: Latency is a key ingredient for excellent user experiences. Experiments at Amazon revealed that every 100 ms increase in load time on a page decreases sales by 1%. Any company that has an online presence needs to worry about low latency. I know that my local superstore has chocolate chip cookies in stock on aisle A23, or bake and serve on A33, because hitting the location icon shows me where in the store’s layout. At checkout, I use my watch to pay for my groceries. My bank takes in my data, runs fraud detection and returns my approval in under 50 ms using SingleStore. Low latency goes hand in hand with concurrency. You need to maintain low latency even as your application grows to tens of thousands of simultaneous users. Those users expect that high level of service — or companies risk losing them to competitors who are delivering those experiences. With the exponential growth of real-time data requirements, the need for low latency on large volumes of data puts SingleStore into a different class.
- Data Size: It is important to have both transactional and analytical data in one database. This makes it easier to quickly transition from high-level analytics to transactional data — and having both transactions and analytics in one database makes combining the data for reports far simpler, while also reducing instances of duplicate data. This also means the database needs to store a large volume of transactional and aggregated data. With SingleStore, there is no need to limit analysis on aggregated data when it runs queries at speed and scale for petabytes of transactional data. Aggregation is by choice and not forced by a lack of performance. Patented technology allows a single table to be in memory, on-disk and on remote object storage (AWS S3 Bucket, Azure Container, GCP Buckets and NFS). Keeping track of when data is hot or cold means that performance doesn’t suffer, even as data volume increases. This is all done automatically. Using unlimited storage removes the need to archive data for lack of space, allowing data scientists to utilize more data for their findings. Also, customers see 70 - 80% reduction in data due to automatic compression. 100TB becomes 20TB. SingleStore’s query processor works on the compressed data and only expands the data returned in the recordset — setting us apart from our competitors.
- Speed of Ingest: As we move from traditional data sources to IoT data, being able to handle both the batch and real-time data is the foundation of modern architecture. I have lost track of how many devices in my home send information to me (my watch, scale, thermometer, BP monitor, washing machine, solar panels, garage door opener, printers, router, TV sets, etc.). Businesses are required by customers to track more and more data in real time. SingleStore handles both real-time and batch data at speed that other databases can’t match — around 10M + transactions per second, compared to ~100k - 1M for other databases. SingleStore’s speed means fewer budget dollars are spent on databases and infrastructure. And just because you don’t have a high volume of data now doesn’t mean you can’t scale with SingleStore in the future as your data needs increase.
- Concurrency: How often do we give up when things take too long to return? This has to do with concurrency, and the system struggling to handle the number of active users. SingleStore was built from the ground up using a lock-free stack, so batch updates and backups do not impact real-time users. One of SingleStore’s customers handles 40K+ clients at the same time using their wealth management dashboard. Designed as a distributed, massively parallel processing system, SingleStore can handle a significantly higher number of concurrent users — at a lower TCO — than competitors.
- Complexity: SingleStore’s unique approach to queries optimization allows for greater speed on complex queries. SingleStore embeds an industrial strength compiler to produce highly efficient machine code, enabling low-level optimizations. Other databases in the market use interpreted models that can not achieve the speeds we see in SingleStore. The queries are stored in a plancache for subsequent utilization. In addition, the query processor utilized indexes to optimize joining multiple files of different types together. Other databases can claim fast performance, but when it comes down to it, the queries must be simple or their performance is lacking. Results are cached, not the query like SingleStore. Their 'caching' does not work for real-time data.
It is the combination of these data-intensive properties that make SingleStore unique. Some SingleStore competitors claim they have low latency (which they do) — but only when supporting 50 or 60 concurrent users. Some claim to have high data volumes, but can’t support simple joins at speed. Reading data is quick, but updates and deletes are slow since writes block reads. For some, their numbers look good, but when looking closely they are a function of using in-memory data frames with development languages like Spark or Python, and not in the database.
SingleStore’s connectors allow you to work with dataframes and enhance dataframe performance. Ingest speed is quick — but vendors take minutes (or hours) for data to be usable in queries. SingleStore excels at handling data-intensive requirements at high speeds, complexity and concurrency, and at a lower cost than the competition. Customer Proof of Concepts (POC) and real world deployments have shown SingleStore to be 10 - 100x faster at ⅓ the cost.
Success with data intensity: How IEX Cloud Increased Financial Data Distribution Speeds by 15x
Trading ‘or’ for ‘and’: Database Features You Don’t Have to Decide Between
What makes SingleStore unique? SingleStore is able to handle what used to be trade-offs in data architecture. Most database vendors will say they can handle these trade-offs, and they can. It is just a matter of degree. From my personal experience, traditional databases like SQL Server are able to handle these requirements, but on a different scale. Instead of ingesting 10M transactions per second like SingleStore, completing 15,000-20,000 is a challenge. - Our 'new' database competitors boast 100K - 1M transactions per second. In most cases, you will need multiple database offerings from our competitors to handle those needs with duplicate ETL processes, resulting in database sprawl.
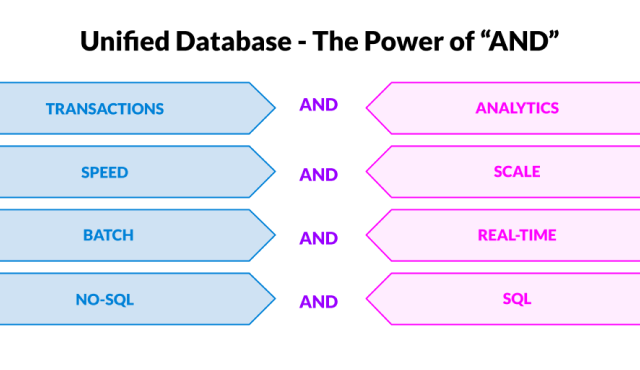
- Trade-off: Transactions v.s. analytics. You pick a database for transactions for enterprise reporting/ad hoc queries; OR you choose to aggregate into an analytical database for batch analysis and processing; OR more often than not, you have two different databases to get the performance you need. That means additional processes to extract, transform and load the data for each database. It also means it is difficult to combine new transactional data and analytical data, requiring you to have the aggregated data for queries. With SingleStores patented Universal Storage, SingleStore is able to handle both transactional AND analytical data at speed— fast real-time ingest and queries, along with fast real-time analytics and fast batch analytics where days are reduced to minutes. In most other databases, the combination of transactional and analytical data causes issues with speed, data updates, deletions and more.
- Trade-off: Speed v.s. scale. You choose a database for speed, OR you choose one for scale. But unfortunately, you can’t get both in equal measure. SingleStore is the fastest in-memory database available today — and with our universal storage, you get speed AND scale. Not to mention as the number of concurrent users goes up, performance doesn’t falter. It’s speed, scale, high concurrency and fast response times all rolled into a unified database.
- Trade-off: Batch v.s. real time. With the internet of things (IoT), expectations are for real-time data. I look at my phone and my heart rate is 87 bpm, my body temperature is 99.3 and my blood pressure is high at 140/90. Being at my desk, I have not walked that much today — only 1,129 steps. I can share this data with my physician. Not quite in real time, but we’re not far off from that capability.
On the flip side, we still need to have large scale ingestion of data from other sources that are not in real time. The trade-off was batch OR real time. Being able to load and transform large volumes of data speed up the analysis and discovery on that data. SingleStore is able to handle the demands of real-time data as efficiently as it handles batch processing — batch AND real time. Other databases can have long lags between ingesting data and when it is available for reporting. Being able to run Machine Learning algorithms at speed and scale makes predictions that save lives — like for Thorn, where reducing ingest time to reporting from 20 minutes to 200 milliseconds made all of the difference in the world.
- Trade-off: Structured v.s. unstructured data. Data comes in a number of different formats, and has a number of different uses. Unstructured data and No-SQL data is useful for applications that work on small volumes of data that change frequently. Websites are a great example, gathering new information quickly and for a short period of time is fairly common. Web and mobile application developers prefer unstructured data. With a relational database, to add a column, you need to modify the ETL process and set up the defaults. That means your choice was structured OR unstructured data. SingleStore can handle both No SQL AND SQL data structures in the same database. You can run a query against both, storing and filtering the data in the format that makes the most sense. In addition, SingleStore can handle geospatial functions, vector functions, full-text search and time-series functions at speeds that used to require separate specialized databases. This integrates your data in one place, eliminating database sprawl and associated expenses, while simplifying your architecture.
In Summary: Why Choose SingleStore?
- Ideal for data-intensive performance: SingleStore handles current and future needs for data size, speed of ingest, query latency, query complexity and query concurrency.
- Hybrid transactional & analytical processing: We’re designed to handle operational and real-time analytics on both transactional and large data volumes.
- Three-tiered storage: SingleStore automatically keeps data in memory, on disk and is always accessible for fast query responses. This is done automatically by SingleStore, without any intervention once the database is created.
- Consolidation & multi-model: With SingleStore, you eliminate the need, costs and complexity of managing specialty databases, data lakes, data warehouses and more. And, you can process multiple data types (CSV, JSON, time-series, geospatial, vector, etc., in one system).
- Interoperability: Connect to your existing systems to speed them up, and scale them out. Streaming systems (Kafka, StreamSet), BI tools (PowerBi, Tableau, SAS) complement ELT tools (Informatica, Talend) and customer-facing applications.
- Distributed scalability: As data demands increase, you aren’t limited to the size of your servers so you can continue to scale out the massively parallel processing (MPP) clusters on generic low cost servers. And that means you won’t run out of CPU, memory or disk.
- Hybrid & multi cloud: SingleStore delivers greater flexibility, allowing you to deploy and run in hybrid, multi-cloud or on-prem environments.
Get the only database designed for data-intensive applications.




.png?width=24&disable=upscale&auto=webp)




