

A version of this blog post first appeared in the developer-oriented website, The New Stack. It describes how SingleStore works with Apache Kafka to guarantee exactly-once semantics within a data stream.
Apache Kafka usage is becoming more and more widespread. As the amount of data that companies deal with explodes, and as demands on data continue to grow, Kafka serves a valuable purpose. This includes its use as a standardized messaging bus due to several key attributes.
One of the most important attributes of Kafka is its ability to support exactly-once semantics. With exactly-once semantics, you avoid losing data in transit, but you also avoid receiving the same data multiple times. This avoids problems such as a resend of an old database update overwriting a newer update that was processed successfully the first time.
However, because Kafka is used for messaging, it can’t keep the exactly-once promise on its own. Other components in the data stream have to cooperate – if a data store, for example, were to make the same update multiple times, it would violate the exactly-once promise of the Kafka stream as a whole.
Kafka and SingleStore are a very powerful combination. Our resources on the topic include instructions on quickly creating an IoT Kafka pipeline; how to do real-time analytics with Kafka and SingleStore; a webinar on using Kafka with SingleStore; and an overview of using SingleStore pipelines with Kafka in SingleStore’s documentation.
How SingleStore Works with Kafka
SingleStore is fast, scalable, relational database software, with SQL support. SingleStore works in containers, virtual machines, and in multiple clouds – anywhere you can run Linux.
This is a novel combination of attributes: the scalability formerly available only with NoSQL, along with the power, compatibility, and usability of a relational, SQL database. This makes SingleStore a leading light in the NewSQL movement – along with Amazon Aurora, Google Spanner, and others.
The ability to combine scalable performance, ACID guarantees, and SQL access to data is relevant anywhere that people want to store, update, and analyze data, from a venerable on-premise transactional database to ephemeral workloads running in a microservices architecture.
NewSQL allows database users to gain both the main benefit of NoSQL – scalability across industry-standard servers – and the many benefits of traditional relational databases, which can be summarized as schema (structure) and SQL support.
In our role as NewSQL stalwarts, Apache Kafka is one of our favorite things. One of the main reasons is that Kafka, like SingleStore, supports exactly-once semantics. In fact, Kafka is somewhat famous for this, as shown in my favorite headline from The New Stack: Apache Kafka 1.0 Released Exactly Once.
What Is Exactly-Once?
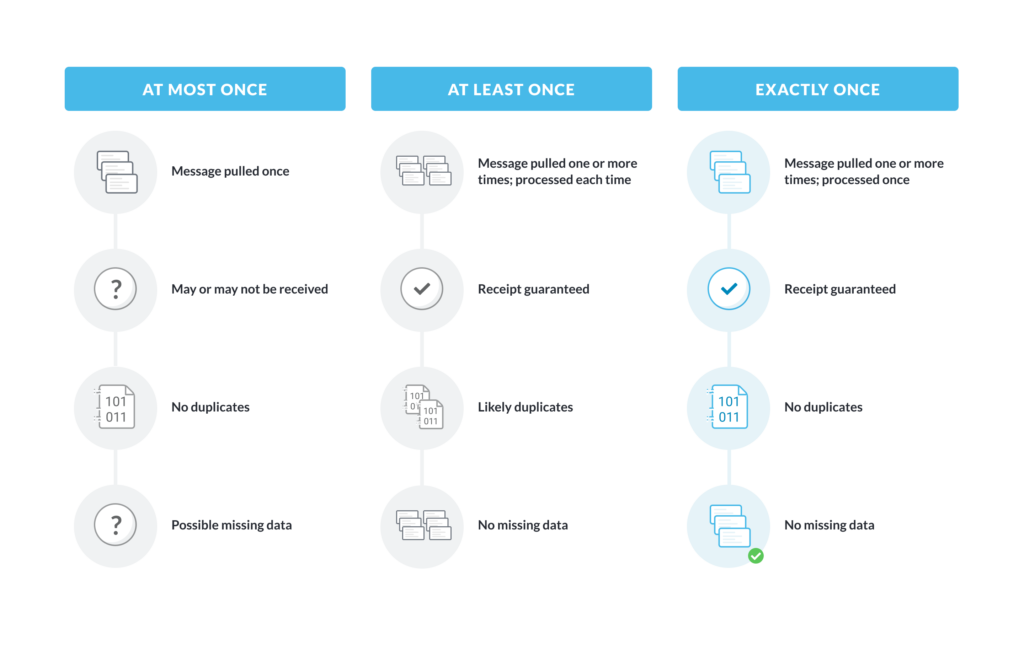
To briefly describe exactly-once, it’s one of three alternatives for processing a stream event – or a database update:
- At-most-once. This is the “fire and forget” of event processing. The initiator puts an event on the wire, or sends an update to a database, and doesn’t check whether it’s received or not. Some lower-value Internet of Things streams work this way, because updates are so voluminous, or may be of a type that won’t be missed much. (Though you’ll want an alert if updates stop completely.)
- At-least-once. This is checking whether an event landed, but not making sure that it hasn’t landed multiple times. The initiator sends an event, waits for an acknowledgement, and resends if none is received. Sending is repeated until the sender gets an acknowledgement. However, the initiator doesn’t bother to check whether one or more of the non-acknowledged event(s) got processed, along with the final, acknowledged one that terminated the send attempts. (Think of adding the same record to a database multiple times; in some cases, this will cause problems, and in others, it won’t.)
- Exactly-once. This is checking whether an event landed, and freezing and rolling back the system if it doesn’t. Then, the sender will resend and repeat until the event is accepted and acknowledged. When an event doesn’t make it (doesn’t get acknowledged), all the operators on the stream stop and roll back to a “known good” state. Then, processing is restarted. This cycle is repeated until the errant event is processed successfully.
How SingleStore Joins In with Pipelines
The availability of exactly-once semantics in Kafka gives an opportunity to other participants in the processing of streaming data, such as database makers, to support that capability in their software. SingleStore saw this early. The SingleStore Pipelines capability was first launched in the fall of 2016, as part of SingleStoreDB Self-Managed 5.5; you can see a video here. There’s also more about the Pipelines feature in our documentation – original and updated. We also have specific documentation on connecting a Pipeline to Kafka.
The Pipelines feature basically hotwires the data transfer process, replacing the well known ETL (Extract, Transform, and Load) process by a direction connection between the database and a data source. Some limited changes are available to the data as it streams in, and it’s then loaded into the SingleStore database.
From the beginning, Pipelines have supported exactly-once semantics. When you connect a message broker with exactly-once semantics, such as Kafka, to SingleStore Pipelines, we support exactly-once semantics on database operations.
The key feature of a Pipeline is that it’s fast. That’s vital to exactly-once semantics, which represent a promise to back up and try again whenever an operation fails.
Like most things worth having in life, exactly-once semantics places certain demands on those who wish to benefit from it. Making the exactly-once promise make sense requires two things:
- Having few operations fail.
- Running each operation so fast that retries, when needed, are not too extensive or time-consuming.
If these two conditions are both met, you get the benefits of exactly-once semantics without a lot of performance overhead, even when a certain number of crashes occur. If either of these conditions is not met, the costs can start to outweigh the benefits.
SingleStoreDB Self-Managed 5.5 met these challenges, and the Pipelines capability is popular with our customers. But to help people get the most out of it, we needed to widen the pipe. So, in the recent SingleStoreDB Self-Managed 6.5 release, we announced Pipelines to stored procedures. This feature does what it says on the tin: you can write SQL code and attach it to a SingleStore Pipeline. Adding custom code greatly extends the transformation capability of Pipelines.
Stored procedures can both query SingleStore tables and insert into them, which means the feature is quite powerful. However, in order to meet the desiderata for exactly-once semantics, there are limitations on it. Stored procedures are SingleStore-specific; third-party libraries are not supported; and developers have to be thoughtful as to overall system throughput when using stored procedures.
Because SingleStore is SQL-compliant, stored procedures are written in standard ANSI SQL. And because SingleStore is very fast, developers can fit a lot of functionality into them, without disrupting exactly-once semantics.
Pipelines are Fast and Flexible
The Pipelines capability is not only fast – it’s also flexible, both on its own, and when used with other tools. That’s because more and more data processing components can support exactly-once semantics.
For instance, here are two ways to enrich a stream with outside data. The first is to create a stored procedure to do the work in SingleStore.
The following stored procedure uses an existing SingleStore table to join an incoming IP address batch with existing geospatial data about its location:
CREATE PROCEDURE proc(batch query(ip varchar, ...))
AS
BEGIN
INSERT INTO t
SELECT batch.*, ip_to_point_table.geopoint
FROM batch
JOIN ip_to_point_table
ON ip_prefix(ip) = ip_to_point_table.ip;
END
(For a lot more on what you can do with stored procedures, see our documentation, which also describes how to add SSL and Kerberos to a Kafka pipeline.)
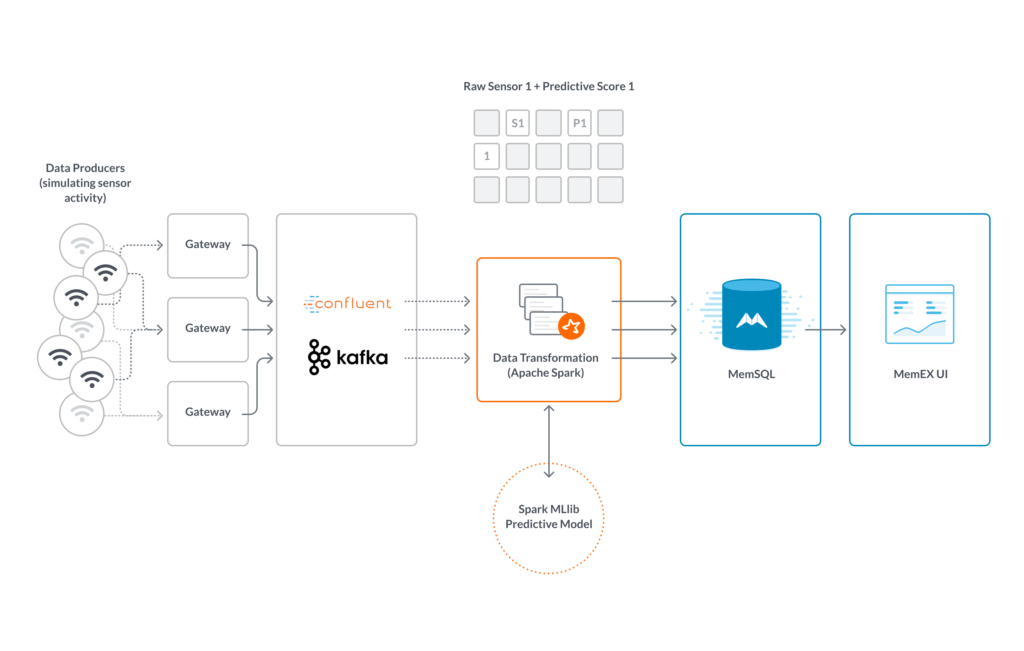
You can also handle the transformation with Apache Spark, and you can do it in such a way as to support exactly-once semantics, as described in this article. (As the article’s author, Ji Zhang, puts it: “But surely knowing how to achieve exactly-once is a good chance of learning, and it’s a great fun.”)
Once Apache Spark has done its work, stream the results right on into SingleStore via Pipelines. (Which were not available when we first described using Kafka, Spark, and SingleStore to power a model city.)
Try it Yourself
You can try all of this yourself, quickly and easily. SingleStoreDB Self-Managed is now available for free, with community support, up to a fairly powerful cluster. This allows you to develop, experiment, test, and even deploy for free. If you want to discuss a specific use case with us, contact SingleStore.




.png?width=24&disable=upscale&auto=webp)




