

SingleStore co-founder and co-CEO Nikita Shamgunov gave the keynote address and a session talk at the AI Data Science Summit in Jerusalem earlier this summer. The session talk, presented here, describes the use of SingleStore as a data backbone for machine learning and AI. In this talk, he gives a demonstration of the power of SingleStore for AI, describes how SingleStore relates to a standard ML and AI development workflow, and answers audience questions. This blog post is adapted from the video for Nikita’s talk, titled Powering Real-Time AI Applications with SingleStore. – Ed.
Demonstrating the Speed of SingleStore for AI Applications
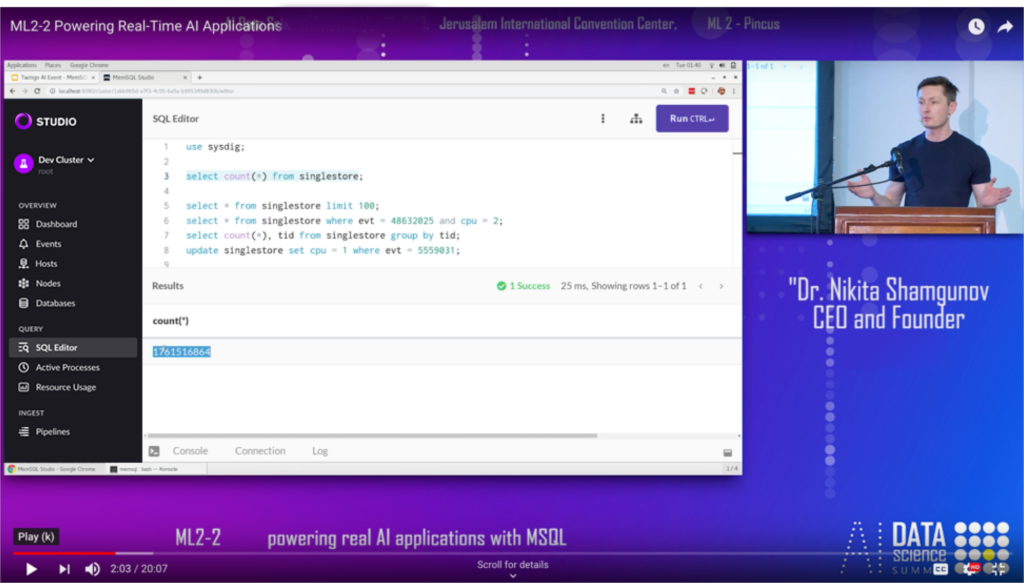
SingleStore allows you to deal with large datasets. And here, on my laptop, running Linux, I am going to show you a table here using this wonderful tool which we call SingleStore Studio. I’m going to show you a table that has 1.7 billion records. So I’m storing 1.7 billion records on my laptop. (Note 1761516864 highlighted in SingleStore Studio – Ed.)
How many of you know what SQL is, and how to use SQL? (Most of the audience raises their hands. – Ed.) That’s very good. That’s very convenient, and I always ask this question because usually I get a very positive response. So people in general know SQL, and in a data science world, people often start with SQL to pull data into their own tools or frameworks because SQL is so convenient to slice and dice data before you move it somewhere else.
So again, to level set of what SingleStore is before we go into the actual application, the system is a relational database. It stores data in an incredibly compressed format. So here I’m storing 1.7 billion records on my laptop. The whole thing takes 11 gigabytes.
The kind of data here is somewhat typical, so data I collected from the telemetry from my own laptop. So I used a tool called Sysdig, and it starts telling all that information … telemetry that is happening in my own laptop.
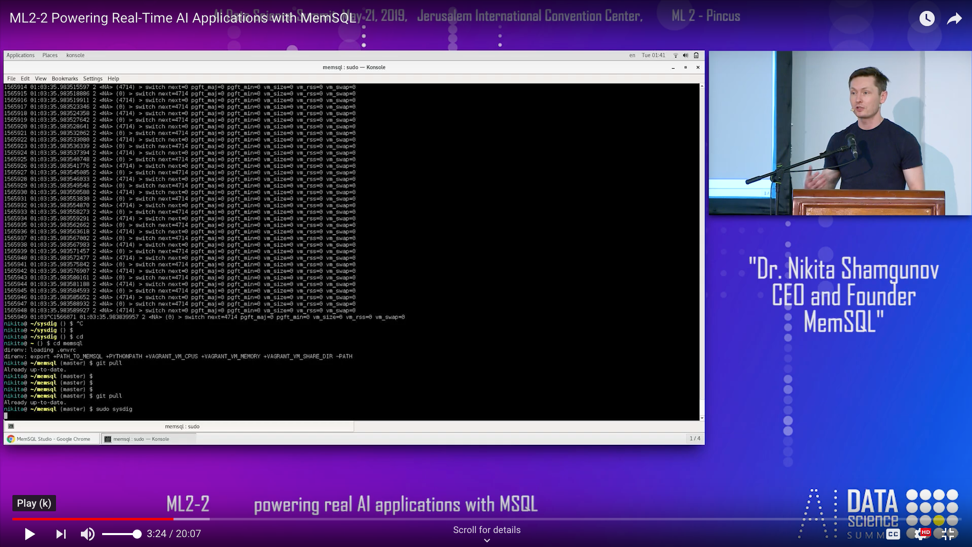
All the system calls, temperature, all the various telemetry and data points and events that are happening on my laptop. So obviously, you can run machine learning models to start predicting what’s going to happen next and there are startups in San Francisco that are doing exactly that for monitoring very large data centers, for monitoring Kubernetes containers and whatnot.
So I captured that data and I captured that data in SingleStore, loaded it. And the trick is that you can load that data in real time, so you can connect to anything that emits data. You can connect to stream processing systems like Kafka, and the data will just start flowing into SingleStore. And you can assume that SingleStore is completely limitless, right? So you can land as much data in SingleStore as you want.
But the data is not just stored in some sort of cold storage. If you want to get an individual data point out of the data, you can retrieve that data in an incredibly fast way. So those who work with S3, Hadoop… If you want to take one individual record stored on HDFS in a Parquet file and you want to get it back, some sort of big gears need to shift before you get this record back.
Well, in this case, let’s just try to fetch a record here, out of SingleStore, out of my laptop. I can put limit one to get one record and stuff comes back in two milliseconds.
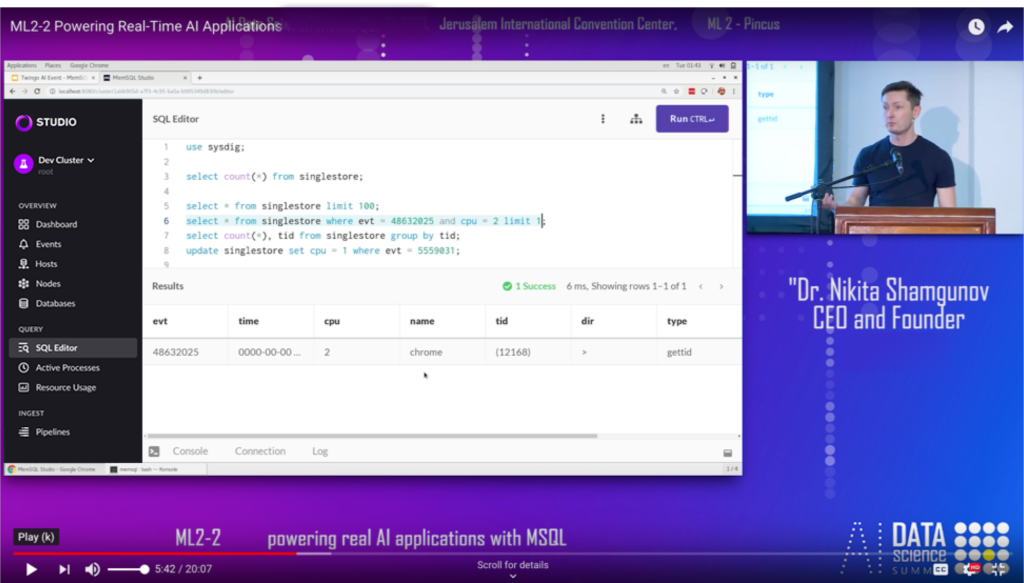
And what that means is you can actually … once you deploy those models, right? And then when you deploy models into production, usually it’s the combination of intelligence that’s delivered through a model and some source that serves data to the application, you put them together and you can achieve incredibly low latencies eventually delivered to what people recently called smart apps.
So that’s what SingleStore is. Typically, in data science there are multiple parts of the workflow, as you put systems into production, when you need to extract individual data points out of the system, you can do it with incredibly low latency. People do it for fraud detection all the time. You swipe a credit card, you need to understand if it’s a fraudulent transaction, or you’re walking into a building, you’re doing face recognition. That’s the thing … it has to be a real time system.
Or you want to extract data from the system and slice and dice it. And I’ll give you an example of that as well. In this query I’m going to scan the whole 1.7 billion records and understand some basic information. So group, group, group those 1.7 billion records by this field that’s called GID. And that is actually happening also very, very quickly, in 1.2 seconds. In 1.2 seconds we processed a billion records here.
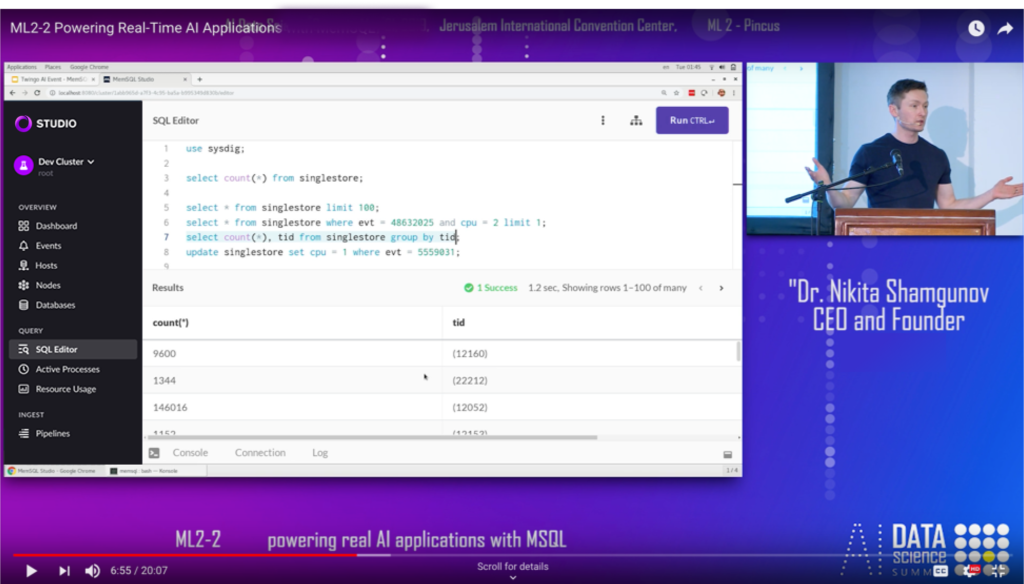
So now, why this matters is because the system is incredibly convenient in becoming the backbone of where you want to land data, where you want to do feature engineering, where you want to expose that data set to your team. It’s very lightweight. It can run on your laptop and it’s free to run on your laptop. And then you can open up your laptop and put it on the server, put it in the cloud, scale it, and then go from analytics and data science to pixels that are displayed on people’s apps on the website in an incredibly efficient way.
Q. What is SingleStore focused on here?
A. SingleStore is focused on both fetching data and updating data. So here let’s go and update something. There’s an update statement. I can run it and it’s instant. And the idea is you can build apps. It’s a transactional database. And usually when you have apps you want to insert, update, delete, aggregate, produce reports, deliver analytics back to the application. And we give you basically infinite compute.
We have this mechanism of locking your record. And in fact, we only lock on writes, so you will only have conflict on writes, and reads never take locks. So that makes it incredibly convenient to build apps because what people hate is when apps start to spin. There’s a spinning, like a wheel, on the app. Very often, when we win business from large companies, the definition of success is no spin.
Q. What’s the drawback?
A. What’s the drawback? Well, humbly, there are no drawbacks. So I think the only drawback is that it is in fact a distributed system so you need to use a distributed system versus sometimes the workloads are such that they fit on a small system and that they fit on a small system, it’s no better. So you’re kind of wasting that ability to scale. (The advantages of SingleStore are not evident at small scale – Ed.)
Using SingleStore for Machine Learning and AI Workflow
Q. What about the workflow for AI and ML? (This refers to the ML and AI workflow Nikita showed during his keynote address on data infrastructure for ML and AI at the same conference. – Ed.)
A. So the question is … So what’s the workflow? And when do you build a model? So typically, this is kind of a very high level definition of the workflow. You define machine learning use cases. You define ML use cases, you do some data explorations. So you don’t need SingleStore to define ML use cases, but when you want to do data exploration, typically, people want to play with the data.
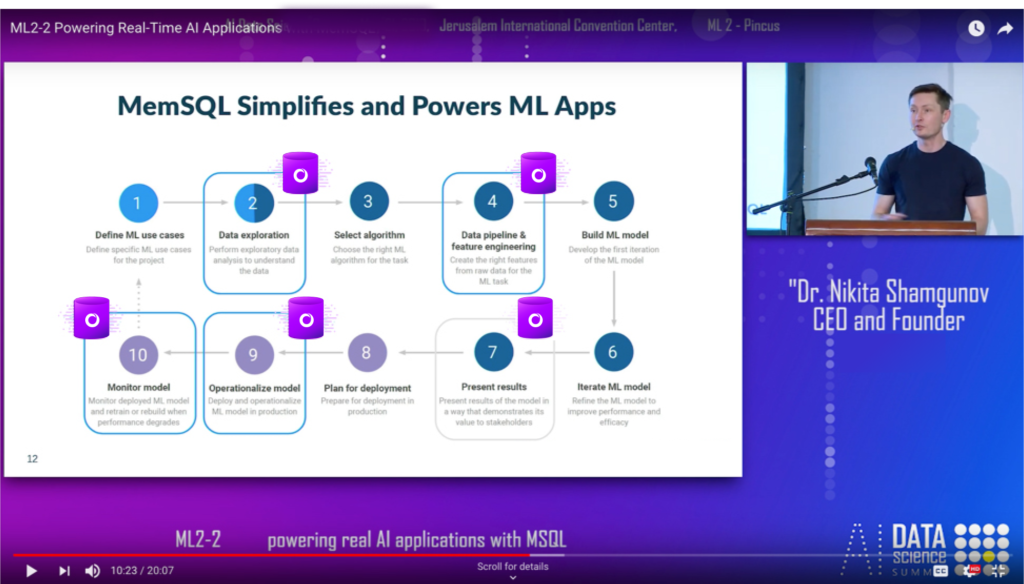
And once you push data into SingleStore, it’s very, very efficient. You can explore data yourself by running SQL statements directly against the database. You can attach a business intelligence (BI) tool. You can visualize it, you can attach a notebook. Now you’ll be pulling data into Python or Spark, and SingleStore integrates and works with Spark incredibly well. So you can play with the data.
Q. Where can I get the connector?
A. The connector, it’s on GitHub, so you download the SingleStore connector, and what we do is we give you very fast data exchange between SingleStore and Spark data frames. And that’s what people use all the time, where SingleStore gives you basically storage and compute with SQL, and Spark gives you training and ad hoc analysis, ATL, feature engineering.
And what people do is they create a data frame and they call “save to SingleStore” on a data frame and the data drops in there and it’s reliable, transactional, all those good things.
Data pipeline. (Refers to step 4., Data pipeline and feature engineering, in the workflow diagram. – Ed.) So everywhere I go into modern organizations, there are data pipelines. You take data, extract it from multiple systems, and oftentimes people use Spark. Sophisticated customers and some of them are here in Israel, use change data capture (CDC) tools when they pull data from relational databases, MySQL, Oracle, massage the data and push it into SingleStore.
So we spent years and put a lot of work into making that process very, very simple. And one of the most common patterns with data pipelines … usually there’s Kafka somewhere and once data is in Kafka, you can put in data into SingleStore at the click of a button. You say, “Create pipeline,” point at Kafka, data’s flowing in.
Build ML model. (Refers to step 5., Build ML model, in the workflow diagram. – Ed.) So this is what you’re going to do using Python packages, and then people iterate, right? Obviously, there’s a lot going on when you develop a model and you think about a million things, but once you’re kind of out and proud with a model, you want to present results and you want to deploy that model. And typically, you deploy a model and then you run in some sort of parallel environment to make sure that you don’t screw up.
And really depending on the use case, right? In some cases, the bar for quality is low and we have some customers that perform fraud detection on electricity IoT data such that, you know, “This household spent more on electricity than last month.”
Okay, we want to look at that. Well, that’s not very sophisticated. And then anything you do there will improve their quality of fraud detection dramatically. And then we have customers that do financial analysis, risk analysis, understanding risk of an individual loan. That’s where the bar is very, very high because you improve the model by a little bit and then you’re saving millions of dollars.
Then you plan for deployment and then you operationalize the model. (Refers to step 8., Plan for deployment, and step 9., Operationalize model, in the workflow diagram. – Ed.) And so that’s where some people deconstruct that model, and let’s say they do image recognition … And I showed you that video in the keynote.
Maybe I’ll show that again here. So in this video, you can point a smartphone at anything and it will go and find that that’s an item in the catalog. So it does it in a very, very fluid way and it allows people to compare prices, efficiently shop. Or you’re talking to a friend and you want to buy the same thing that the friend has and whatnot.
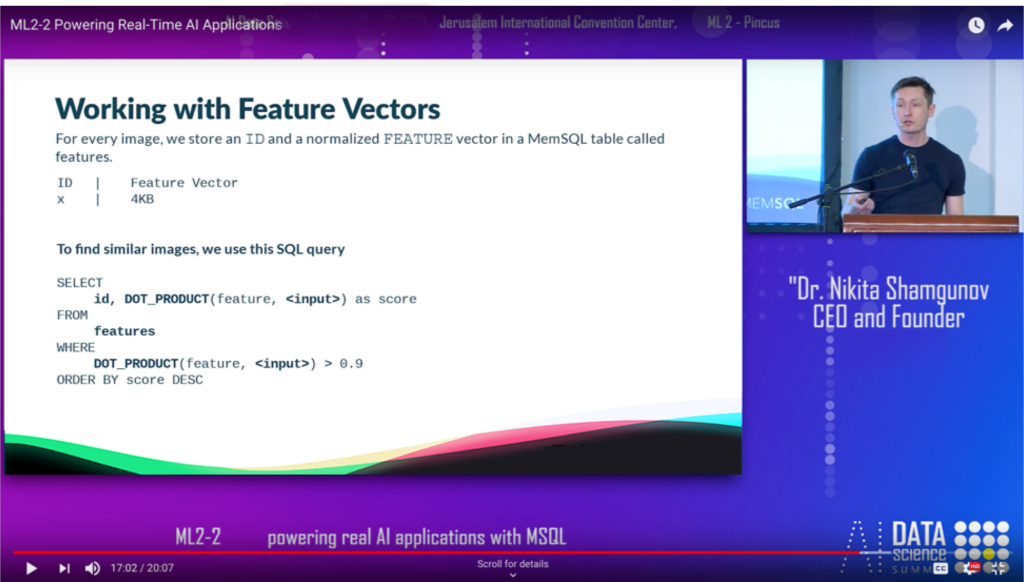
So in this case, they took a model and they deconstructed that model and they expressed that model in feature vectors and used basic operations that we offer in SingleStore, such as vector dot products, Euclidean distance, to run a very simple query. These are the primitive operations that we offer in SingleStore, so if you store feature vectors in a table, now, using a scale-out kind of limitless compute, you can run a query that will scan all the records in that table, compute dot product against the feature vector which you got from an image with all the feature vectors already there.

Well, I’m not going to explain you what a dot product is, but basically running that query where all the feature vectors are greater than 0.9, that’s your similarity search.
SingleStore’s Future for Machine Learning and AI
Now, the advantage of doing this in a database is that the actual model … in this case, incredibly primitive … but co-locating the model and the data opens up all the possibilities that you can do. And now, what we’re working on now is the ability to push TensorFlow and Caffe and PyTorch models directly into SingleStore.
And with that, you’re able to run those models in production, inside the database, right next to the data and deliver great user experiences by building smart apps.
Final Q&A and Conclusion
Q. How do transactions work for Spark?
Very good question. So the way transactions work in SingleStore, as a transactional system, everything that’s between begin transaction and commit is atomic. So with Spark, it’s no different. If you take a data frame and you save to SingleStore, this data frame drops into SingleStore in a transactional way. So until every record makes it from the data frame, makes it into SingleStore, nobody else sees that data. There are transaction boundaries around “Save to SingleStore.” In the case of Kafka, we go micro-batch to micro-batch and the transaction boundaries are around the micro-batch.
And in fact, if there is a failure, then if a micro-batch … So we will never persist half of a micro-batch. So each micro batch is going to be delivered to SingleStore as a whole, which gives you exactly-once semantics from Kafka.
Q. Do I use SingleStore for training my model?
Yeah. Training is done outside of SingleStore, so we do not support training, but we can be the data backbone for training, and if training needs data and queries, SingleStore periodically – that’s a perfect low-latency solution for that. All right. Thank you.
You can download and run SingleStore for free or contact SingleStore – Ed.










