

You won’t believe the technology that goes into making SingleStore the fastest modern cloud database. And our latest features bring mission-critical capabilities to developers of all kinds, from enterprise database engineers to SaaS application developers. In this post, Micah Bhatki and Eric Hanson from SingleStore’s Product Management team reveal what’s new.

SingleStore’s Mission-Critical Capabilities for Enterprise Applications
Eric Hanson / Micah Bhakti
SingleStore’s newest capabilities allow us to take on new mission-critical workloads. As a developer, you will have the control you need to feel confident running your mission-critical, data-intensive applications on SingleStore. And SingleStore can be deployed anywhere you run your applications, on AWS, Azure, and GCP, or self-hosted on your own infrastructure with unmatched performance, scalability, and durability.
SingleStore’s unique patented Universal Storage delivers the separation of storage and compute, and has enabled the following features in a new product edition, SingleStore Premium, to complement the existing SingleStore Standard. SingleStore Premium is designed for mission-critical applications that have stringent requirements for availability, auditability, and recovery.
Key Mission-Critical Features included in Premium:
- Point-In-Time Recovery
- Multi-AZ Failover
- Resource Governance
- Audit Logging
- HIPAA Compliance
- 99.99% Availability
- Silver Support
These capabilities allow enterprises running mission-critical internal and customer-facing applications with the most stringent requirements to guarantee availability, durability, and auditability of all of their information, while delivering the performance and scalability SingleStore is known for.
This article explains these and other performance and usability improvements now available in SingleStore.
Point-in-Time Recovery
For years, SingleStore has supported transactions via log-based recovery, multi-version concurrency control, lock-based write/write synchronization, built-in high-availability, and disaster recovery. But customers and prospects have asked for one feature in particular to help them recover to a consistent database state in the event of data corruption—Point-in-time recovery, or PITR.
PITR is now generally available after previously debuting as a preview. It allows you to recover a database to a transaction-consistent state at any point in time, down to datetime(6) resolution, or to any named milestone you created in the past.
For example, suppose you deployed an application change at 2:00 am and discovered at 2:30 am that it corrupted the database. You can detach the database, and reattach it as of 2:00 am, to get the data back to the consistent state it was in before you deployed the application change.
Moreover, even though SingleStore is a distributed database, with separate transaction logs for each partition, PITR uses a new technology called global versioning that allows the system to bring the database to a transaction-consistent state after recovery.
Point-in-time recovery works by:
- recovering the latest snapshots taken just before the point in time desired, which contain rowstore data and metadata that references columnstore blob files,
- playing back the log files to the desired point in time or milestone.
This is illustrated in the following diagram:
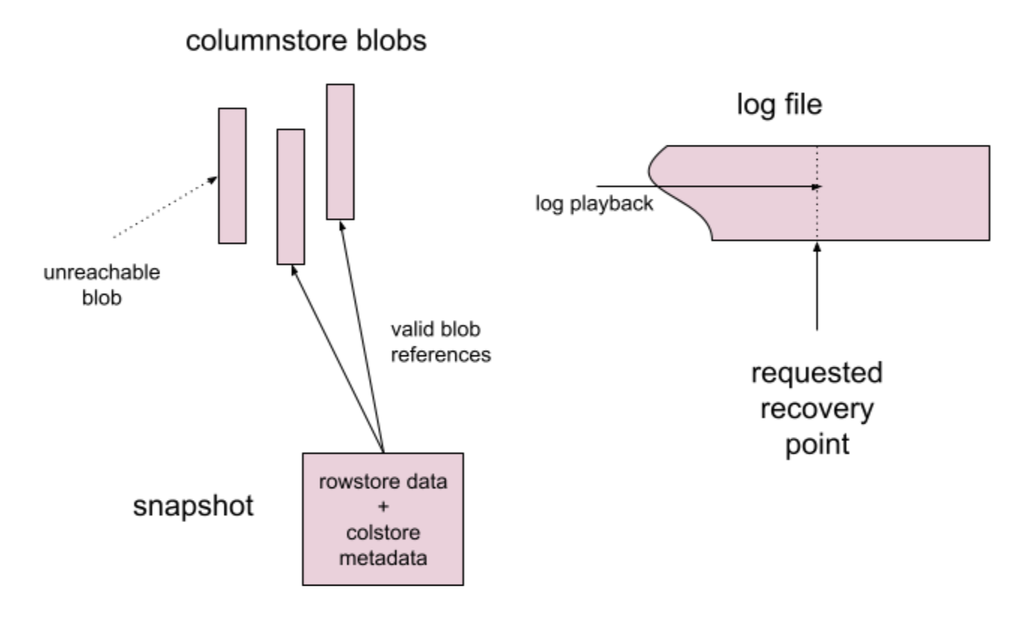
Columnstore blobs are immutable, so the blobs visible in metadata after this process are all and only the blobs needed. They will be read from storage on demand when query processing commences after a PITR. This helps the performance of PITR, since not all data must be read to resume query processing.
As the database lifecycle progresses, older, historical data, such as blobs whose data have been fully deleted from tables, may still be in the defined history window for PITR. However, those blobs will not be actively queried, so they will age out of the local cache on the cluster. They'll thus only be stored on object storage, which is very low cost. Moreover, this frees up space on the local cluster to keep the hot data around, allowing fast query performance.
Finally, SingleStore PITR is easy to use. You just need to detach a database and attach it at a time or named milestone, either from the SQL prompt, or from our managed service UI. There's no need to install and learn any external recovery manager software. And if you want to try a different time point, you just detach the database and attach it again at the new point, which can be before or after the original point to which you recovered.
For mission-critical workloads, PITR ensures that data can always be recovered from unexpected writes to or corruption of the database. This provides the highest levels of confidence in data integrity, and allows enterprises to use SingleStore as the single source of truth for data-intensive applications.
For how to use PITR, see our documentation.
Multi-AZ Failover
SingleStore ensures high availability by redundantly storing data across availability groups. Each availability group contains a copy of every partition in the system—some as masters and some as replicas. As a result, SingleStore has two copies of your data in the system to protect the data against single node failure.
With SingleStore Premium we now place availability groups in separate Availability Zones (AZs) on your cloud provider of choice. When combined with “Unlimited Storage” which replicates all data to highly-durable Multi-AZ object storage, both availability and durability can be retained, even in the event of a catastrophic failure to an entire cloud availability zone.
This combined with our unique “Load-Balanced Failover” ensures maximum performance with minimal impacts to ensure applications remain available even when cloud infrastructure fails.
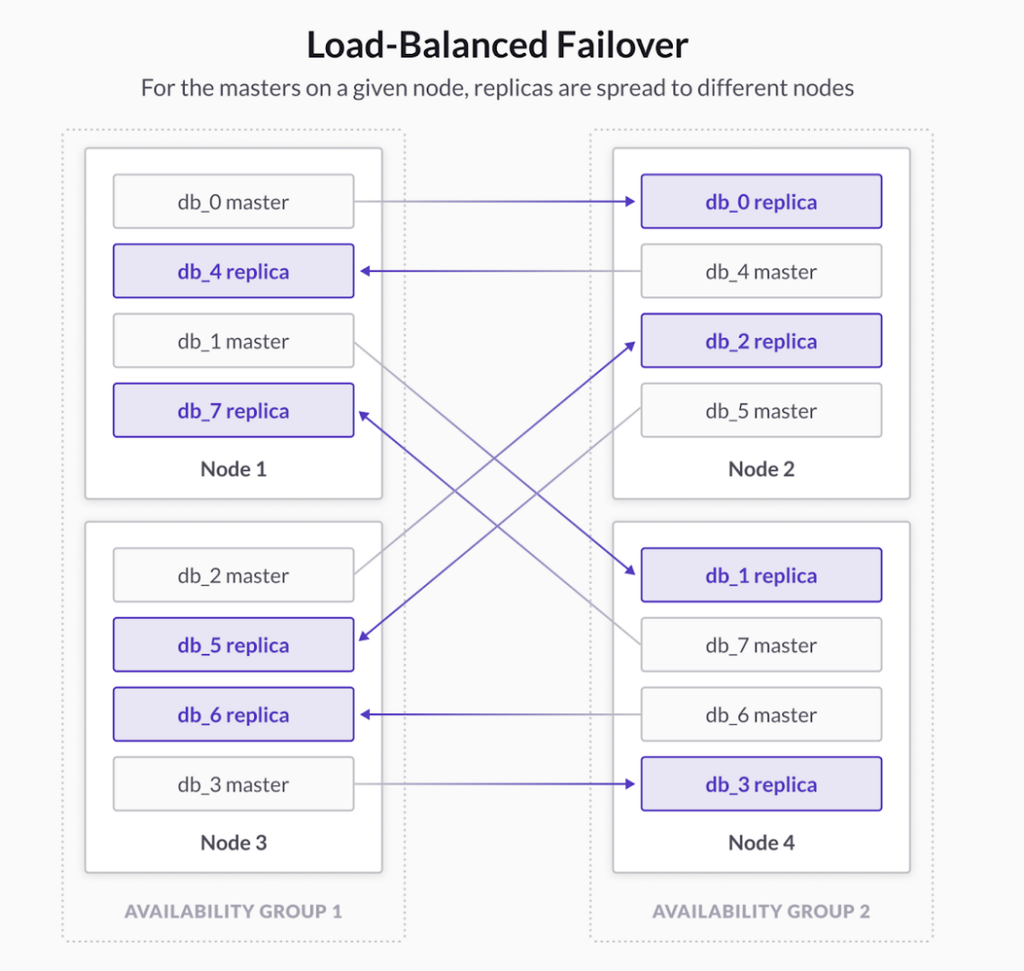
This provides the availability needed for mission-critical applications and services to meet the targets of even the most dissenting enterprises.
Resource Governance
SingleStore’s workload manager automatically manages cluster workloads by limiting execution of queries that require fully distributed execution, to ensure that they are matched with available system resources.
With Resource Governance, SingleStore now allows you to define resource pools, which can specify resource limits. As an example, you can use resource limits to prevent one user’s query from making the system unusable for others connected to the database. This allows you to prevent non-critical workloads from overloading the system. For more information, see Setting Resource Limits.
Audit Logging
With data driving today’s organizations, it’s important to know who can access data, who has viewed it, and why. SingleStore now provides full access to audit logs ensuring a complete audit trail. These logs can be viewed by authorized users on-demand through cluster reports, which enables customers to proactively understand the activity within their own cluster(s) for complete peace of mind.
HIPAA Compliance
SingleStore has built security into all aspects of our product. Encryption, authentication, access, and monitoring are all things SingleStore automates so you can focus on data and the value it brings to your organization.
Because of this, SingleStore has met the compliance requirements to deploy HIPAA workloads when using SingleStore Premium. This allows healthcare and medical organizations to take advantage of SingleStore while ensuring data is protected at all times.

Lock-free Backup
Previously, doing a backup in SingleStore required the system to take an exclusive lock for a split second, quiescing the multi-partition write transactions in the system to create a synchronization point to start the backup. Although the lock was short, this created a noticeable pause in the flow of these multi-partition writes for some applications.
Read transactions were not affected because SingleStore uses multi-version concurrency control so writers don't block readers. Also, single-partition write transactions did not have to wait. Even so, multi-partition writes are somewhat common, so it was a noticeable problem.
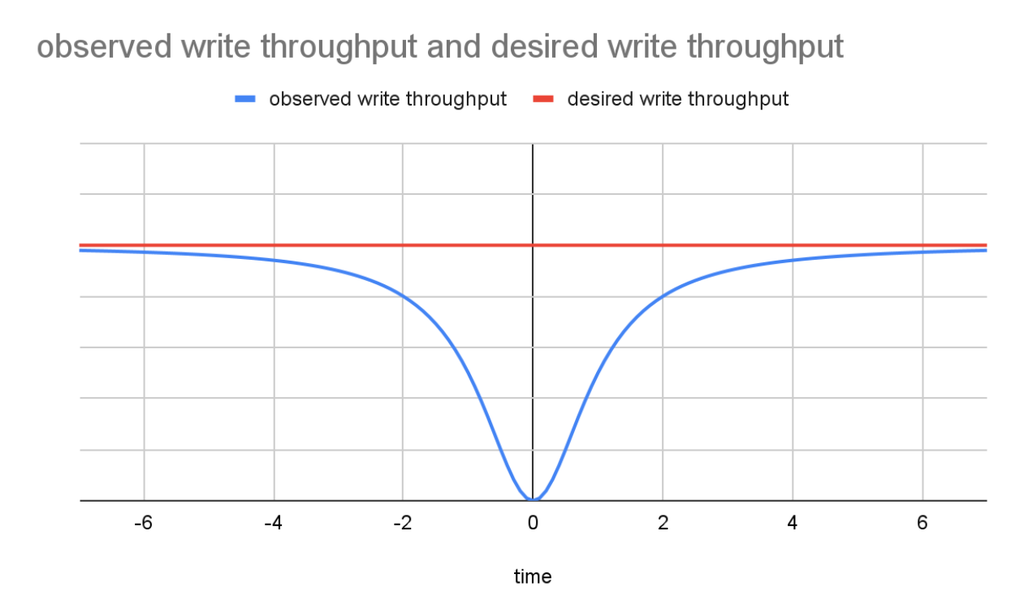
Now, backups don't have to take a lock. Rather, they create a synchronization point based on our global versioning technology. The figure below is a qualitative illustration of the difference in multi-partition write throughput between the old approach (observed throughput) and the new approach (desired throughput), assuming that the backup lock is obtained at point 0 on the timeline. With lock-free backup, multi-partition write throughput will be largely unaffected, similar to the red, desired throughput curve, around the time a backup is started.
Execute SPs With Either Definer or Invoker Permissions
Stored procedures (SPs) in SingleStore prior to the latest release ran with definer permissions, meaning that queries in the body of the SP run under the permissions granted to the user who defined the SP. This is the default model in Oracle, and is a popular approach because it allows you to control access procedurally via an SP to information that the calling user would not otherwise be able to access. A set of SPs can thus become controlled entry points to access data.
On the other hand, there are different scenarios where people would like the queries in the SP to run with the permissions of the invoker (caller) of the SP. This approach is the default in Microsoft SQL Server and Azure SQL DB, for example. In order to satisfy both requirements, for SPs to be able to run either as their definer or their invoker, we've added invoker permissions as an option in this latest release.
For example, consider these SPs:
create procedure p() authorize as current_user as
begin
echo select current_user();
end
create procedure t() authorize as definer as
begin
echo select current_user();
end
The first procedure, p, will run as the current user (invoker) calling it. You can see the authorization model for each SP by querying metadata:
singlestore> select specific_name, definer from information_schema.routines;
+---------------+---------+-----------------+
| specific_name | definer | invocation_mode |
+---------------+---------+-----------------+
| p | root@% | CURRENT_USER |
| t | root@% | DEFINER |
+---------------+---------+-----------------+
Suppose we create a user "user" and log in as that user, then call p and t. As you can see, calling p outputs the userid of the caller, and calling t outputs the userid of the definer:
singlestore> call p();
+----------------+
| current_user() |
+----------------+
| user@% |
+----------------+
singlestore> call t();
+----------------+
| current_user() |
+----------------+
| root@% |
+----------------+
Ingest Support for Kafka Transactions
Kafka transactions allow you to write a sequence of messages into a kafka queue atomically. SingleStore pipelines can now read from a Kafka queue that has transactions enabled, and they will only read committed groups of messages.
Enterprise users have begun to use Kafka transactions for atomicity guarantees when it's meaningful to add messages to a queue in discrete groups. Now, these users can use SingleStore pipelines to load data from these queues successfully and do so in a transaction-consistent way.
By default, SingleStore Kafka pipelines will support read-committed Kafka transactions. This means that pipelines will never read uncommitted messages from Kafka queues that have transactions enabled. Users can optionally configure pipelines to use Kafka's read-uncommitted isolation, making uncommitted messages visible.
Conclusion
SingleStore is an enterprise cloud database—and with the latest enhancements it can handle even your most demanding mission-critical applications.
If you want to try SingleStore, you can get started completely free. If you have questions or get stuck, connect with the SingleStore community and get all of your questions answered, or check out more cool developer content on our SingleStore resources page. The community forums are the best place to get your SingleStore questions answered.
To further explore the features and benefits of SingleStore, we invite you to check out the SingleStore Training page which includes self-paced courses like Schema Design, Data Ingestion, Optimizing Queries, and more.
Follow us on Twitter to keep up on our latest news for developers.
Watch this recorded webinar from the blog authors for a comprehensive overview of SingleStore capabilities.








_feature.png?height=187&disable=upscale&auto=webp)
