
I used to pump gas at a Shell station in Oregon, where they still fill your tank for you. I patched the occasional tire and changed some belts and hoses too, taught by two great mechanics who could fix anything. Those guys were pros — tough and skillful men. But there was one thing that always turned them into little kids: the arrival of the Snap-on tool truck — the mechanics' toy store on wheels!
You database application developers are makers and fixers too. You're grown up. But what grown-up builder doesn't like their toys? We're proud to announce the arrival of the SingleStoreDB tool truck for Spring 2022!

Query processing
Speed, scale and elasticity
Some things make your toys better — even if you can't touch and use them directly, you feel their power anyway! Think bigger batteries and more powerful Estes rocket engines. The new SingleStoreDB release (7.8) has query processing features like that, including performance, scale and elasticity improvements.
Flexible parallelism
In this new release, Flexible parallelism (FP) lets you use all the cores on your machines to process a single query, regardless of how many partitions your database has. Before this release, the system used one thread per partition. So if you grew your hardware by adding nodes or making each one have more cores, it wouldn't make a query run faster when executing by itself. FP makes the most of your hardware toys.
Read our blog on Flexible Parallelism.
With FP, when running one parallel query when you have four times as many cores as partitions, your CPU meter will look like this:
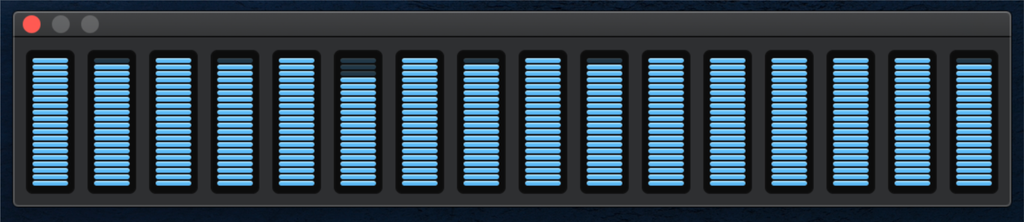
instead of this:
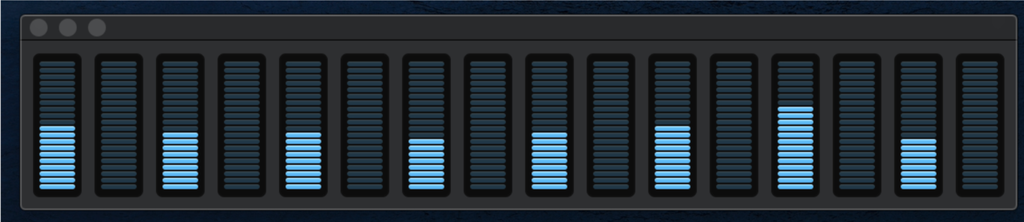
Your shiny new CPU cores will not be idling in the toybox, so they'll get your queries done a lot quicker — potentially many times faster!
Spilling
In this release, Spilling for hash group-by, select-distinct and count-distinct operations is on by default. If they'd use more memory than available, part of the in-memory hash table for the operations will be written (spilled) to disk. This allows queries to run (albeit more slowly), rather than fail if they hit the memory limit. Here are the variables that control spilling:
singlestore> show variables like '%spill%';
+------------------------------------------+-----------+
| Variable_name | Value |
+------------------------------------------+-----------+
| enable_spilling | ON |
| spilling_minimal_disk_space | 500 |
| spilling_node_memory_threshold_ratio | 0.750000 |
| spilling_query_operator_memory_threshold | 104857600 |
+------------------------------------------+-----------+
Notice that enable_spilling is on by default. The defaults are sensible — you won't normally have to touch them. See our documentation for more details on the variables.
LLVM upgrade
We upgraded our LLVM code generation framework to version 10 from version 3.8. Most queries perform (at most) marginally faster. A few queries, like a simple delete from a 1000-column table, are much improved. They will either run when they would cause an error before, or they compile much faster — in some cases, up to 100x faster.
Many-column DELETE statements now compile up to 100x faster
Materialized CTEs
Common Table Expressions (CTEs) can be expensive to compute, but return a small result set (say, if they include a group-by/aggregate on a lot of data). The same CTE can sometimes be referenced more than once in the same query. TPC-DS Q4 is an example:
WITH year_total AS (
… huge aggregate query…
)
SELECT
t_s_secyear.customer_id
, t_s_secyear.customer_first_name
, t_s_secyear.customer_last_name
, t_s_secyear.customer_email_address
FROM year_total t_s_firstyear
JOIN year_total t_s_secyear
ON t_s_secyear.customer_id = t_s_firstyear.customer_id
JOIN year_total t_c_firstyear
ON t_s_firstyear.customer_id = t_c_firstyear.customer_id
JOIN year_total t_c_secyear
ON t_s_firstyear.customer_id = t_c_secyear.customer_id
JOIN year_total t_w_firstyear
ON t_s_firstyear.customer_id = t_w_firstyear.customer_id
JOIN year_total t_w_secyear
ON t_s_firstyear.customer_id = t_w_secyear.customer_id
WHERE t_s_firstyear.sale_type = 's'
AND … lots more filters …;
It uses CTE year_total six times!
SingleStoreDB now automatically recognizes this and will compute the CTE once, save the result internally and reuse that result each time it appears in the query, rather than recomputing it for each reference. This is all within the scope of one query; the saved CTE is discarded when the query completes. This can speed up the query up to a factor of ‘N,’ if the CTE is used ‘N’ times.
Row-level decoding for string
Row-level decoding lets you seek faster into a Universal Storage (also known as an enhanced columnstore) table that has string-encoded columns. There's no need to decode a whole million-row chunk of a segment for the column to find the value for just one row. It shaves many milliseconds off seeks into string-encoded columns. With this, you get the first picture here, instead of the second:
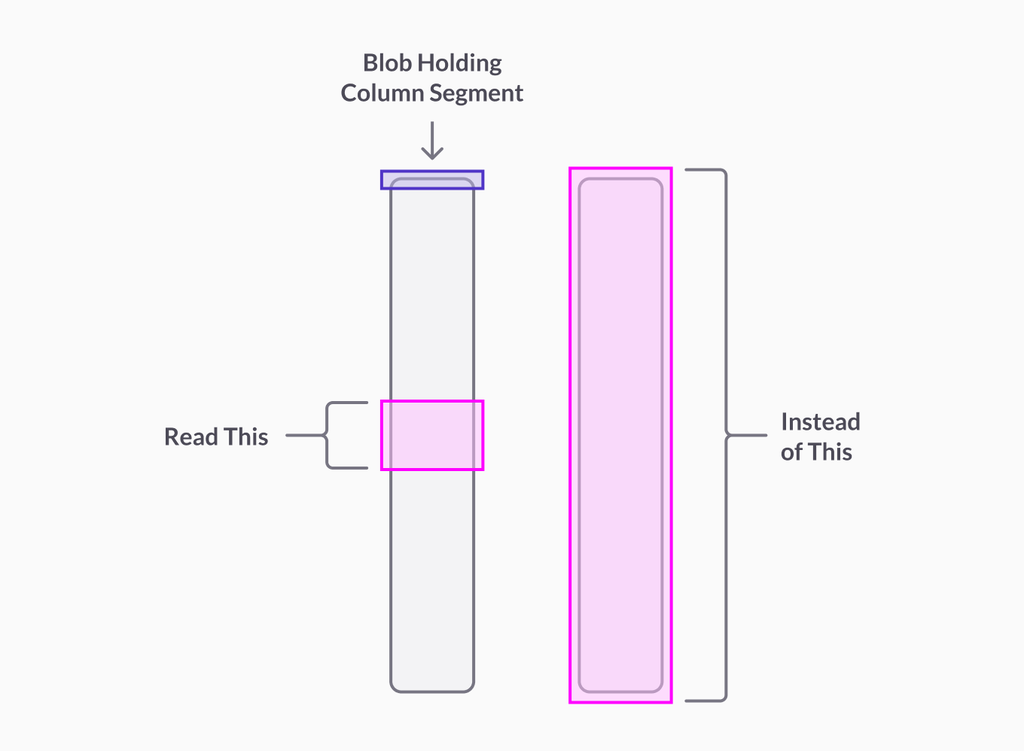
You only need to read a few bytes from the column segment, not the whole thing.
Faster upgrades via reduced effort for codegen
SingleStoreDB compiles queries to machine code, one of the sources of its speed. Compilation takes time, so we've worked to make compilation faster and ensure it happens less often.
Upgrades will no longer always trigger code generation (codegen) for all queries after the upgrade. We now only codegen if the engine generates different LLVM intermediate representation for the query due to some bug fix or improvement. That means you can now upgrade to SingleStoreDB patch releases without all queries having to have code generated again in most cases, since patch releases rarely have such fixes.
Features you can code with
That covers speed and scale. What can a builder really put their hands on in this release?
SET statement for user-defined session variables
Since the early days of SingleStoreDB, we supported the SET statement to assign values to a local variable so existing MySQL tools would not produce errors, but it was a no-op. We introduced SELECT INTO variable(s) recently, which gives the equivalent of the SET statement. Now, SET works just as you'd expect it. It's simpler and more intuitive than SELECT INTO variable(s), and developers use it often.
Local variables can be used for all kinds of things. A common use is to break work down into multiple steps to make queries easier to write and read. Here's a script that finds every employee in an organization with the maximum salary:
create table emp(id int, name varchar(30), salary float);
insert emp values (1,"Bob",10000),(2,"Sue","12000");
set @maxsal = (select max(salary) from emp);
select * from emp where salary = @maxsal;
+------+------+--------+
| id | name | salary |
+------+------+--------+
| 2 | Sue | 12000 |
+------+------+--------+
Session variables are typed, and the type is inferred from context. If you want a specific type, use a cast, like so:
set @d = 0 :> double;
Multi-assignment is supported:
set @x = 1, @y = 2;
The user-defined variables for your session can be seen in information_schema.user_variables. Here they are for the current session:
select * from information_schema.user_variables;
+---------------+-------------------------+---------------------+
| VARIABLE_NAME | VARIABLE_VALUE | VARIABLE_TYPE |
+---------------+-------------------------+---------------------+
| y | 2 | bigint(20) NOT NULL |
| x | 1 | bigint(20) NOT NULL |
| d | 0.00000000000000000e+00 | double NULL |
| maxsal | 1.20000000000000000e+04 | float NULL |
+---------------+-------------------------+---------------------+
Shipping SET for local variables rounds out our extensive programmability features that now include stored procedures (SPs), user-defined functions (UDFs), user-defined aggregate functions, table-value functions (TVFs), anonymous code blocks, temporary SPs, SELECT INTO variables, external UDFs and external TVFs. SET is pretty simple. But don't we all sometimes get a lot of enjoyment out of our most basic toys?
Matching expressions to computed columns
Matching expressions to computed columns lets you speed up query processing while coding your queries in a more natural way. It allows you to make some queries faster, without having to change the text of those queries.
For example, if myJsonField::%n is accessed a lot in WHERE clauses with equality filters, you may want to create a computed column whose value is myJsonField::%n and put an index on it. Then the query will speed up by seeking the index, with no change to the query text. If you have several queries that use the same filter, they'll all benefit. You won't have to hunt them down in your code and change them. This is data independence — a relational database virtue — in action.
Here's an example:
CREATE TABLE assets (
tag_id BIGINT PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
properties JSON NOT NULL,
weight AS properties::%weight PERSISTED DOUBLE,
license_plate AS properties::$license_plate PERSISTED LONGTEXT,
KEY(license_plate), KEY(weight));
explain select * from assets where properties::$license_plate = "XYZ123";
+------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------+
| Gather partitions:all alias:remote_0 parallelism_level:segment |
| Project [assets.tag_id, assets.name, assets.description, assets.properties, assets.weight, assets.license_plate] |
| ColumnStoreFilter [assets.license_plate = 'XYZ123' index] |
| ColumnStoreScan db1.assets, KEY __UNORDERED () USING CLUSTERED COLUMNSTORE table_type:sharded_columnstore |
+------------------------------------------------------------------------------------------------------------------+
Notice the ColumnStoreFilter uses a computed column license_plate, and the index on it, to solve the query even though the query references properties::$license_plate. This is a field that would normally have to be computed every time by reaching into the JSON field properties.
It's important to use a large data type like longtext or double for computed columns to avoid failure to match that can occur due to overflow issues. Warnings are available to help you identify the cause of match failures — for example, if you change the CREATE TABLE statement for assets to make license_plate be of type text instead of longtext, and do:
compile select * from assets where properties::$license_plate = "XYZ123";
show warnings;
You will see:
Warning 2626, Prospect computed column: assets.license_plate of type text
CHARACTER SET utf8 COLLATE utf8_general_ci NULL cannot suit expression of
type longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL.
You can add computed columns and index them using ALTER TABLE. e.g.:
create table t(id int, key(id));
alter table t add id2 as id*2 persisted bigint;
create index idx on t(id2);
Persisted computed column matching can help you change the database to speed up queries without touching your application.
VECTOR_SORT and other new vector functions
SingleStoreDB has a set of vector functions that operate on vectors of floating point numbers, or integers packed as binary data. These are useful for AI applications like face recognition and image matching. Where applicable, they use Intel AVX2 Single-Instruction, Multiple-Data (SIMD) instructions to perform four to 32 operations per instruction rather than just one, so they are amazingly fast.
We've filled out our vector toy collection in this release with these new functions:
| VECTOR_SORT | sort a vector |
|---|---|
| VECTOR_KTH_ELEMENT | find the k'th element of a vector, 0-based |
| VECTOR_SUBVECTOR | take a slice of a vector |
| VECTOR_ELEMENTS_SUM | total the elements of a vector |
| VECTOR_NUM_ELEMENTS | gets the length of the vector, in elements |
Versions of these functions are available for all common integer and floating point sizes.
Here's an example using the sort function:
select json_array_unpack(vector_sort(json_array_pack('[300,100,200]')));
+------------------------------------------------------------------+
| json_array_unpack(vector_sort(json_array_pack('[300,100,200]'))) |
+------------------------------------------------------------------+
| [100,200,300] |
+------------------------------------------------------------------+
One of our financial customers is using these functions to do Value-at-Risk calculations, which are done to help measure the total expected losses in a portfolio under various conditions, which helps to avoid overweighting one security or sector across the institution. These functions allow them to do the calculation in the database, rather than extracting the data into application software to do it — speeding up and simplifying the process.
ISNUMERIC
Need to know if a string contains a number, but also be able to handle commas, currency signs and the like? ISNUMERIC is popular in other DBMSs for doing this, and is now available in SingleStoreDB:
select "$5,000.00" as n, isnumeric(n);
+-----------+--------------+
| n | isnumeric(n) |
+-----------+--------------+
| $5,000.00 | 1 |
+-----------+--------------+
This'll make it easier to port applications from SQL Server and Azure SQL DB, for example.
SELECT FOR UPDATE – now for Universal Storage
SELECT FOR UPDATE now works on Universal Storage (enhanced columnstore) tables. You use it in multi-statement transactions. It allows you to enforce serializability by holding locks across statements. Financial users in particular may be interested in it for serializing complex updates. Allowing SELECT FOR UPDATE to work on Universal Storage improves TCO, and lets you run transactional applications that need serializability on datasets larger than RAM.
Security and permissions
Some of our large enterprise customers have strict security requirements and enforce policies whereby only the minimum necessary privileges will be granted to users in their organizations, including application owners and application administrators who may not need all the permissions of the root user. To help ensure that only the minimum privileges are needed to get the job done with respect to GRANT of permissions, we've added a new, more granular mode for GRANT option.
SECRET()
Want to keep a secret? The new SECRET function takes a literal and makes sure it doesn't show up in trace logs or query plans or profiles. You can use it to hide passwords, certificates and the like. For example, if you run:
profile select * from t where s = SECRET('super-secret-password');
then run
show profile json;
you'll see
"query_text":"profile select * from t where s = SECRET('<password>')",
whereas if you didn't use SECRET, then 'super-secret-password' would appear in the profile output.
Storage
We've added a couple of new storage features that have directly visible commands you can use.
Backup with split partitions for unlimited storage DBs
We now support offline partition split via backup for unlimited storage (bottomless) databases. We've supported this for standard databases for a while.
Suppose you have a database db1 with 64 partitions and you want 128 partitions, so you can add nodes and rebalance — and have the best number of partitions for your workload. FP makes this less likely to be necessary, but at some point you may need to add partitions, say if you get down to one partition per node and you still want to expand your hardware.
You can run
BACKUP DATABASE db1 WITH SPLIT PARTITIONS TO S3
"backup_bucket/backups/6_1_2022"
CONFIG '{"region":"us-east-1"} '
CREDENTIALS
'{"aws_access_key_id":"your_access_key_id",
"aws_secret_access_key":"your_secret_access_key"} ';
Then restore the backup to a new database name. Assuming the restore succeeded, you can then detach the old database, detach the new database and attach the new database using the old database name, then allow your applications to proceed.
Drop milestone
Milestones are convenient markers that allow you to point-in-time restore (PITR) to a well-known time point. For example, you may want to create a milestone before you deploy an application change. You can PITR to the milestone easily rather than have to recall the time you deployed the change and use the time directly.
Of course, when a milestone isn't needed any more, you may want to remove it. You can now do that with:
DROP MILESTONE milestone name [FOR database_name]
Milestones are automatically removed once they are no longer within the PITR retention period.
Conclusion
We hope you like the SingleStoreDB toys delivered in this release! Whether you like speed, scale, power, control or simplicity, there's something in it for you.





