

As a component of the IBM watsonx platform, watsonx.ai is designed to merge groundbreaking generative AI technologies with conventional machine learning.
This all-in-one studio simplifies the AI development process, providing a streamlined environment for training, validating, tuning and deploying generative AI, foundation models and machine learning capabilities. With watsonx.ai, you can create AI quickly across the entire enterprise — even when working with limited datasets.
Clients can also integrate the platform with SingleStoreDB for real-time context data. This enables organizations to customize their Large Language Models (LLMs) to meet specific business requirements. SingleStoreDB combines hybrid search and analytics capabilities to deliver high performance, serving as a knowledge base for generative AI applications. It feeds accurate contextual data to watsonx.ai's LLM models in just milliseconds.
Deploying watsonx.ai and SingleStoreDB can help address network costs and performance bottlenecks, and also offer added layers of security and ease of deployment. This unified platform is designed to deliver a holistic solution for the many AI needs of a business.
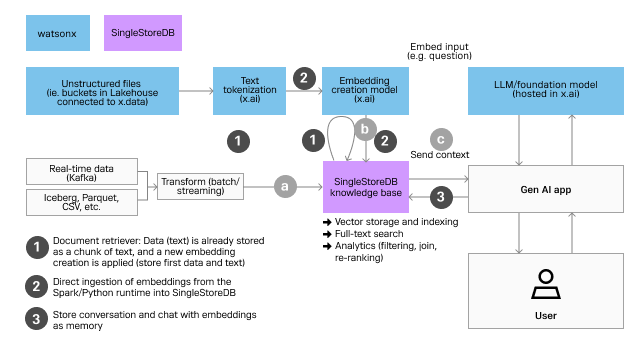
SingleStoreDB is known for its HTAP (Hybrid transaction/analytical processing) storage, which outputs strong performance for transactional and analytical queries and enables real-time analytics. Those capabilities also apply to vectors with fast ingestion and efficient storage serving ibm.com applications with low latency response times on semantic searches.
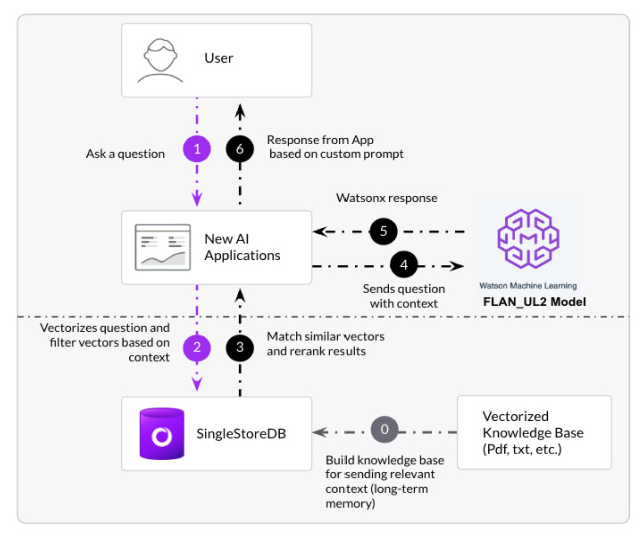
Let’s take a simple example that you can use on your own through IBM watsonx sample notebooks. It lets you use watsonx.ai and SingleStoreDB to respond to natural language questions using the Retrieval Augmented Generation (RAG) approach. We’ll use a LangChain integration to make the developer experience easy.
Outline + steps
- Setup and configuration. We ensure all the required packages are installed and configuration information (e.g. credentials) is provided.
- Define query. We establish the query to be used. This is established up front because we will use the same query in a basic completion with both an LLM and RAG pattern.
- Initialize language model. We select and configure the LLM.
- Perform basic completion. We perform a basic completion with our query and LLM.
- Get data for documents. We get and preprocess (e.g. split) the data we want to use in our knowledge base.
- Initialize embedding model. We select and configure the embedding model we would like to use to encode our data for our knowledge base.
- Initialize vector store. We initialize our vector store with our data and embedding model.
- Perform similarity search. We use our initialized vector store and perform a similarity search with our query.
- Perform RAG. We perform a completion with a RAG pipeline. In this version, we are explicitly passing the relevant docs (from our similarity search).
- Perform RAG with Q+A chain. We perform a completion with a RAG pipeline. In this version, there is no explicit passing of relevant docs.
Setup and configuration
Dev settings
1# Ignore warnings2import warnings3warnings.filterwarnings("ignore")
Packages
1!pip install langchain -q2!pip install ibm-watson-machine-learning -q3!pip install wget -q4!pip install sentence-transformers -q5!pip install singlestoredb -q6!pip install sqlalchemy-singlestoredb -q
langchain: Orchestration frameworkibm-watson-machine-learning: For IBM LLMswget: To download knowledge base datasentence-transformers: For embedding model
Import utility packages
1import os2import getpass
Environment variables and keys
watsonx URL
1try:2 wxa_url = os.environ["WXA_URL"]3except KeyError:4 wxa_url = getpass.getpass("Please enter your watsonx.ai URL domain (hit enter):5")
watsonx API key
1try:2 wxa_api_key = os.environ["WXA_API_KEY"]3except KeyError:4 wxa_api_key = getpass.getpass("Please enter your watsonx.ai API key5(hit enter): ")
watsonx project ID
1try:2 wxa_project_id = os.environ["WXA_PROJECT_ID"]3except KeyError:4 wxa_project_id = getpass.getpass("Please enter your watsonx.ai Project5ID (hit enter): ")
SingleStoreDB connection
If you do not have a SingleStoreDB instance, you can start today with a free trial here. To get the connection strings:
- Select a workspace
- If the workspace is suspended, click on resume it
- Click on Connect
- Click on Connect Directly
- Click SQL IDE which gives you SINGLESTORE_USER (admin for trials), SINGLESTORE_PASS (Password), SINGLESTORE_PORT (usually 3306
- Pick a name for your SINGLESTORE_DATABASE
1try:2 connection_user = os.environ["SINGLESTORE_USER"]3except KeyError:4 connection_user = getpass.getpass("Please enter your SingleStore username (hit5enter): ")
1try:2 connection_password = os.environ["SINGLESTORE_PASS"]3except KeyError:4 connection_password = getpass.getpass("Please enter your SingleStore5password (hit enter): ")
1try:2 connection_port = os.environ["SINGLESTORE_PORT"]3except KeyError:4 database_name = input("Please enter your SingleStore database name (hit5enter): ")
1try:2 connection_host = os.environ["SINGLESTORE_HOST"]3except KeyError:4 database_name = input("Please enter your SingleStore database name (hit enter):5")
1try:2 database_name = os.environ["SINGLESTORE_DATABASE"]3except KeyError:4 database_name = input("Please enter your SingleStore database name (hit enter):5")
1try:2 table_name = os.environ["SINGLESTORE_TABLE"]3except KeyError:4 table_name = input("Please enter your SingleStore table name (hit5enter): ")
Query
1query = "What did the president say about Ketanji Brown Jackson?"
Language model
For our language model we will use Granite, an IBM-developed LLM.
1from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes2from ibm_watson_machine_learning.foundation_models import Model3from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as4GenParams5from ibm_watson_machine_learning.foundation_models.utils.enums import6DecodingMethods
1parameters = {2 GenParams.DECODING_METHOD: DecodingMethods.GREEDY,3 GenParams.MIN_NEW_TOKENS: 1,4 GenParams.MAX_NEW_TOKENS: 1005}
1model = Model(2 model_id=ModelTypes.GRANITE_13B_CHAT,3 params=parameters,4 credentials={5 "url": wxa_url,6 "apikey": wxa_api_key7 },8 project_id=wxa_project_id9)
1from ibm_watson_machine_learning.foundation_models.extensions.langchain import2WatsonxLLM3granite_llm_ibm = WatsonxLLM(model=model)
Basic completion
1result = granite_llm_ibm(query)2print("Query: " + query)3print("Response: " + response)
roud” to have nominated her to the Supreme Court.<|endoftext|>
Data for documents
Let’s now load the knowledge base stored in AWS S3 into documents
1import wget2 3filename = './state_of_the_union.txt'4url =5'https://raw.github.com/IBM/watson-machine-learning-samples/master/cloud/data/foundation_models/state_of_the_union.txt'6 7if not os.path.isfile(filename):8 wget.download(url, out=filename)
Embeddings
By default, we will be using the LangChain Hugging Face embedding model — which at the time of this writing is sentence-transformers/all-mpnet-base-v2.
Let’s split the documents into chunks:
1from langchain.embeddings import HuggingFaceEmbeddings2embeddings = HuggingFaceEmbeddings()
Vector store
We are going to store the embeddings in SingleStoreDB.
Create a SingleStore SQLAlchemy engine
1from sqlalchemy import *2 3# Without database connection URL - we use that connection string to create a database4connection_url =5f"singlestoredb://{connection_user}:{connection_password}@{connection_host}:{connection_port}"6engine = create_engine(connection_url)
Create database for embeddings (if one doesn’t already exist)
1# Create database in SingleStoreDB2 3with engine.connect() as conn:4 result = conn.execute(text("CREATE DATABASE IF NOT EXISTS " + database_name))
Verify the database exists
1print("Available databases:")2with engine.connect() as conn:3 result = conn.execute(text("SHOW DATABASES"))4 for row in result:5 print(row)
Drop table for embeddings (if exists)
1with engine.connect() as conn:2 result = conn.execute(text("DROP TABLE IF EXISTS " + database_name +3"." + table_name))
Instantiate SingleStoreDB in LangChain
1# Connection string to use Langchain with SingleStoreDB2os.environ["SINGLESTOREDB_URL"] =3f"{connection_user}:{connection_password}@{connection_host}:{connection_por4t}/{database_name}"
1from langchain.vectorstores import SingleStoreDB2vectorstore = SingleStoreDB.from_documents(3 texts,4 embedding_model,5 table_name = table_name6)
Check table
1with engine.connect() as conn:2 result = conn.execute(text("DESCRIBE " + database_name + "." +3table_name))4 print(database_name + "." + table_name + " table schema:")5 for row in result:6 print(row)7 8 result = conn.execute(text("SELECT COUNT(vector) FROM " + database_name9+ "." + table_name))10 print("\nNumber of rows in " + database_name + "." + table_name + ": "11+ str(result.first()[0]))
Perform similarity search
Here, we’ll find the similar (i.e. relevant) texts to our query. You can modify the number of results returned with k parameter in the similarity_search method here.
1texts_sim = vectorstore.similarity_search(query, k=5)2print("Number of relevant texts: " + str(len(texts_sim)))
Response: Number of relevant texts: 5
1print("First 100 characters of relevant texts.")2for i in range(len(texts_sim)):3 print("Text " + str(i) + ": " + str(texts_sim[i].page_content[0:100]))
Response:
First 100 characters of relevant texts.
Text 1: Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Ac
Text 2: A former top litigator in private practice. A former federal public defender. And from a family of p
Text 3: As Frances Haugen, who is here with us tonight, has shown, we must hold social media platforms accou
Text 4: And I’m taking robust action to make sure the pain of our sanctions is targeted at Russia’s economy
Text 5: But cancer from prolonged exposure to burn pits ravaged Heath’s lungs and body.
Perform RAG with explicit context control
We’ll perform RAG using our model and explicit relevant knowledge (documents) from our similarity search.
1from langchain.chains.question_answering import load_qa_chain2chain = load_qa_chain(granite_llm_ibm, chain_type="stuff")3result = chain.run(input_documents=texts_sim, question=query)
1print("Query: " + query)2print("Result:" + result)
Response:
Query: What did the president say about Ketanji Brown Jackson?
Response: The president said that Ketanji Brown Jackson is a consensus builder who will continue Justice Breyer's legacy of excellence.<|endoftext|>
RAG Q+A chain
This includes RAG using a chain of our model and vector store. The chain handles getting the relevant knowledge (texts) under the hood.
1from langchain.chains import RetrievalQA2qa = RetrievalQA.from_chain_type(llm=granite_llm_ibm, chain_type="stuff",3retriever=vectorstore.as_retriever())4response = qa.run(query)
1print("Query: " + query)2print("Result:" + result)
Response:
Query: What did the president say about Ketanji Brown Jackson?
Response: The president said that Ketanji Brown Jackson is a consensus builder who will continue Justice Breyer's legacy of excellence.<|endoftext|>
Conclusion
We saw how easy it is to integrate SingleStoreDB with IBM watsonx.ai to help enhance your LLM model with a knowledge base collocated with your watsonx stack for fast retrieval on hybrid search and analytics. Start with watsonx.ai and SingleStoreDB today!









.jpg?width=24&disable=upscale&auto=webp)


