



SingleStore Universal Storage is a single table type that supports analytical and transactional workloads. Universal Storage is our columnstore format, enhanced for seekability.
JSON and String Seek and Update Performance Improvement
SingleStore has consistently demonstrated that you don’t need to have two different database systems to support transactions and analytics, respectively. We can do both — with a modern, distributed, scalable architecture. With our 8.0 release, we're delivering the fifth installment of Universal Storage, with support for fast seeking into JSON and string data.
Fast seeking also helps with update performance because before you update a row, you have to look it up.
To recap from part four, the main benefits of Universal Storage are:
- Improved Total Cost of Ownership (TCO), since not all data needs to fit in RAM
- Reduced complexity, because you can just use one kind of table instead of moving data from a rowstore to a columnstore yourself
- Improved analytics performance on large tables, since query processing benefits from columnar, vectorized execution.
What's New in 8.0 for Universal Storage
In the 7.0, 7.1, 7.3 and 7.5 releases, we evolved our columnstore table type to do things only OLTP-style storage structures were supposed to be able to do. That includes:
- Subsegment access (fast seeking into columnstores to retrieve one or a few records when their position is known)
- Single-column hash indexes
- Single-column unique indexes, constraints, and primary keys
- Upsert support
- Option to set columnstore as the default table type
- Multi-column hash indexes
- Multi-column uniqueness
- Upserts to tables with multi-column unique keys
- Columnstore as the default table type for new clusters by default
In 8.0, we now support:
- Fast seeks into string data
- A new, improved JSON data encoding
- Fast seeks into JSON data
We were a little overzealous in part four when we declared that Universal Storage was "done." Now, we're finished — with all but a few final touches. Keep reading to learn more about orders-of-magnitude performance gains that we've achieved for seeking into JSON and string data.
Example: Speeding Up Seeks into a Table of Documents
To show the improved performance of JSON seeking in 8.0, we created a table orders with this schema:
create table orders(
id int primary key not null, order_doc json, sort key(id));
The order_doc column has a document in it with some top-level properties and a collection of sub-documents, representing the lineitems for the order. This is a typical example of using semi-structured JSON data in SingleStoreDB. Here's an example row value:
insert orders values (1,
'{"id" : 1,
"time" : "2022-11-17 23:03:54",
"lineitems" : [{"line_num" : 1,
"SKU" : 688968,
"description" :
"Apple iPhone 14 Plus",
"qty" : 1} ,{"line_num" : 2,
"SKU" : 6514052,
"description" :
"Energizer - MAX AA Batteries (8 Pack)",
"qty" : 3} ,{"line_num" : 3,
"SKU" : 6457697,
"description" :
"Star Wars - Galactic Snackin Grogu",
"qty" : 1} ]} '
);
The orders table has 8*1024*1024 = 8,388,608 rows in it. We measured the runtime of this query:
select id, order_doc
into _id, _od
from orders
where id = _oid;
This query retrieves all the fields of one row, specified by a random constant _oid.
Running on an 8 core Macbook with an x86_64 Intel chip (for both the old and new JSON columnstore data formats) using SingleStoreDB 8.0.2, we observed these runtimes:
| JSON Format | Avg Runtime(s) |
|---|---|
| Old (8.0 with use_seekable_json = OFF) | 0.5410 |
| New (8.0 with use_seekable_= ON) | 0.001277 |
| Speedup | 423x |
Yes, that's right — a 423x speedup!
The speedup comes from not having to scan an entire million-row segment of data. Rather, once we know the row position within the segment, we simply seek into the column segments directly to get the bytes for the row. Since there's an index on id, we use that to identify the row position fast.
See Appendix 1 for how to generate random orders data and try these queries yourself!
You can also do this with a free SingleStoreDB trial run.
New JSON Data Organization
If you want to know how SingleStoreDB now stores JSON data in Universal Storage tables under the hood, then read on.
Columnstore table columns containing JSON data are organized differently in 8.0 to enable fast row lookups. Prior to 8.0, we kept the data in a Parquet format internally. Over successive releases, we've made it possible to seek into number, date and string data using our own columnstore encodings (compression formats). But data in Parquet is stored differently, in a way that makes it difficult to seek into it — and perform other kinds of fast query execution on it.
In 8.0, we use a new SingleStore-encoded Parquet (S2EP) data format. It stores data such that:
- Top-level JSON properties are stored similar to regular columns, with each property stored column wise. And, the data uses the same encodings that we use for other data types including numbers, strings and dates.
- Nested Properties (inside sub-documents) are also stored similar to regular columns. For example, if a property x.y.z exists, via navigation from a top-level document x to a sub-document y to a property z, it will be stored in a sequential columnar format using our standard encodings.
- Arrays are pivoted and stored in columnar format. An array of numbers that is a property of an enclosing document would be stored as a logical column, with multiple values in the column belonging to the same row. Array length information is kept to enable SingleStoreDB to identify what values below to what row.
- Very sparse columns are stored in a catch-all area, and not stored in encoded columnar format. By sparse, we mean they don't occur in very many documents, i.e. in << 1 of 10,000 documents.
Because we use the same encodings we use for regular data, we are now able to seek into that data using the same approach we used in earlier releases for standard columns. By using our standard encodings, we are also laying the groundwork for future performance improvements, like operations on encoded data applied directly to JSON property data.
Because of this new feature, there will be no need to even consider promoting JSON properties to persisted computed columns moving forward — as is sometimes done today to improve performance. It works well, but of course it comes with additional complexity.
Improved Transaction Processing Speed for String Data
Universal Storage tables are broken into million-row segments. Given a (segment_id, row_number) pair, we can seek to find the row within the segment, rather than scan the segment from beginning to end to find the data for the given row_number. This capability first arrived in SingleStore 7.0 in 2019. It's illustrated in Figure 1.
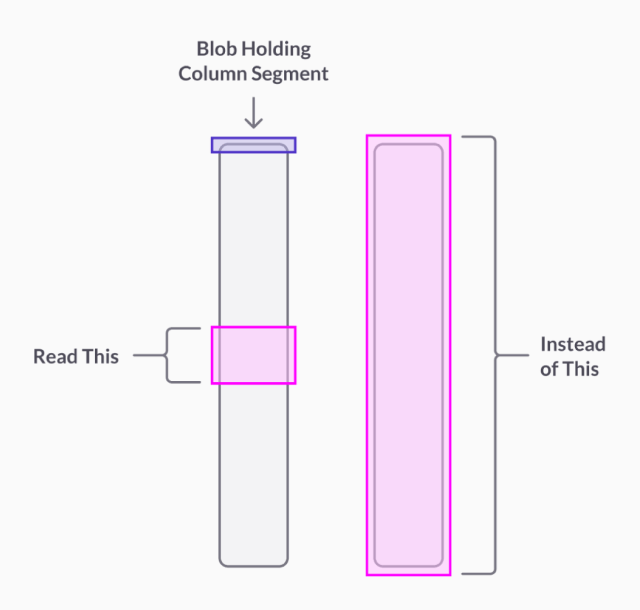
In 8.0, we've improved seekability for some of our string encodings including LZ4 and run-length encoding (RLE). Prior to 8.0, for those string encodings, a block of 4,096 rows was required to locate data for a row. This has led to dramatic speedups on internal, informal runs of TPC-C, an industry standard OLTP benchmark, as shown in Figure 2.
For the TPC-C 10k scale factor, our performance in transactions per minute (TPMC) improved by 170%.
The 10k scale factor contains about 700GB of data. Seek operations on LZ4 and RLE-encoded data can speed up even more than 170% compared to the prior release. The 170% figure is the end-to-end speedup of this benchmark on the 8.0 release.
SingleStoreDB can now seek into all encodings. The only caveat is that for dictionary encodings, the whole dictionary for a segment must be read. This isn’t costly for small dictionaries, and dictionaries are usually small. But, it is possible for us to improve this for large dictionaries – we expect to tackle this in the future.
Update and Delete Performance Improvement
Update and delete performance, for changes that affect a small percentage of rows, has also been improved dramatically for JSON and string data in 8.0. The TPC-C results illustrate this. The reason update performance is better is that updates must:
- Look up the row
- Move the new, updated version of the row to the in-memory rowstore segment
So a selective update has to seek first and read all columns. Similarly, a selective delete has to read all columns of the row before removing it, to promote it to the rowstore segment to enable row-level locking.
Here are some warm-start results we got for simple deletes (they don't include compile time overhead):
singlestore> delete from orders where id = 5000001; -- pre-8.0
Query OK, 1 row affected (0.62 sec)
singlestore> delete from orders2 where id = 5000002; -- 8.0
Query OK, 1 row affected (0.01 sec)
Orders-of-magnitude improvement for updates is possible depending on your schema and update statements. Try some selective updates on the data generated with the script in Appendix 1, and see for yourself.
Summary
The major issues our customers shared related to columnstore seekability were the need for improved speed when seeking and updating JSON and string data. Seekability for these is now complete. So seek and update performance is now good across the board with columnstore tables.
You can be confident that both the operational and analytical parts of your workload will run with excellent performance on SingleStoreDB universal storage tables. This will simplify your designs and allow you to use less hardware, reducing costs.
Appendix 1: Orders Dataset and Performance Measurements
This MPSQL code can be used to generate a data set containing JSON documents and measure performance when seeking into the data.
set global use_seekable_json = OFF;
create database orders;
use orders;
create table orders(id int primary key not null, order_doc json, sort key(id));
delimiter //
/*
Generate >= n documents (stop generating documents when the number of
documents is the nearest power of two >= n).
*/
create or replace procedure gen_orders(n int) as
declare
i int;
c int;
m int;
begin
delete from orders;
insert orders values (1,
'{"id" : 1,
"time" : "2022-11-17 23:03:54",
"lineitems" : [{"line_num" : 1,
"SKU" : 688968,
"description" : "Apple iPhone 14 Plus",
"qty" : 1} ,{"line_num" : 2,
"SKU" : 6514052,
"description" : "Energizer - MAX AA Batteries (8 Pack), Double A Alkaline Batteries",
"qty" : 3} ,{"line_num" : 3,
"SKU" : 6457697,
"description" : "Star Wars - Galactic Snackin Grogu",
"qty" : 1} ]} '
);
i = 1;
while i < n loop
select max(id) into m from orders;
insert into orders
select id + m, new_order_doc(order_doc, id + m)
from orders;
select count(*) into c from orders;
i += c;
end loop;
end
//
delimiter ;
delimiter //
/* change input order_doc into a new one with random data, and the new id */
create or replace function new_order_doc(order_doc json, new_id int) returns json
as
declare
j json;
lineitems json;
l1 json;
l2 json;
l3 json;
begin
j = json_set_double(order_doc, "id", new_id);
j = json_set_string(j, "time", now());
lineitems = json_extract_json(j, "lineitems");
l1 = json_extract_json(lineitems, 0);
l2 = json_extract_json(lineitems, 1);
l3 = json_extract_json(lineitems, 2);
lineitems = json_array_push_json('[]', mutate_lineitem(l1));
lineitems = json_array_push_json(lineitems, mutate_lineitem(l2));
lineitems = json_array_push_json(lineitems, mutate_lineitem(l3));
j = json_set_json(j, "lineitems", lineitems);
return j;
end
//
delimiter ;
delimiter //
create or replace function mutate_lineitem(item json) returns json
as
declare
j json;
begin
j = json_set_double(item, "SKU", floor(rand()*10*1000*1000));
j = json_set_string(j, "description", uuid());
j = json_set_double(j, "qty", ceil(3*rand()));
return j;
end
//
delimiter ;
/* generate 8M rows of data */
call gen_orders(8*1024*1024);
-- measure avg lookup time
delimiter //
create or replace procedure get_avg_time(n int) as
declare
_id int;
_od json;
_oid int;
m int;
st datetime(6);
et datetime(6);
begin
select max(id) into m from orders;
st = now(6);
for i in 1..n loop
_oid = ceiling(m*rand());
select id, order_doc
into _id, _od
from orders
where id = _oid;
end loop;
et = now(6);
echo select (timestampdiff(microsecond, st, et)/1000000.0)/n as avg_time;
end
//
delimiter ;
/* measure average query time */
optimize table orders full; /* make sure all data is
flushed to columnstore format */
call get_avg_time(100);
/* to measure new query time, after 8.0 improvements, do the following */
set global use_seekable_json = ON;
create table orders2 like orders;
insert into orders2 select * from orders;
optimize table orders2 full;
/* Change orders to orders2 in the get_avg_time SP and run the measurements again */
call get_avg_time(100);












