

In this webinar, SingleStore Product Marketing Manager Mike Boyarski describes the growth in popularity of time series data and talks about the best options for a time series database, including a live Q&A. You can view the webinar and download the slides here.
Here at SingleStore, we’ve had a lot of interest in our blog posts on time series data and choosing a time series database, as well as our O’Reilly time series ebook download. Additionally, we have a webinar on architecture for time series databases from DZone.
This webinar, by contrast, does a particularly good job of explaining what you would want in a time series database, and how that fits with SingleStore. We encourage you to read this blog post, then view the webinar.
Time series data is growing in use because it’s getting easier and cheaper to generate time series data (more and cheaper sensors), transmit it (faster online and wireless connections), store it (better databases), act on it (more responsive websites and other online systems), and report on it (better analytics tools).

Time series data is used for device monitoring, for energy systems such as oil wells, for manufacturing, for computer operations, in financial pricing and trading, and for marketing automation. You can use it for alerting, monitoring, and – a usage that’s getting more and more important – for real-time response to all sorts of signals.
Just for one example, an e-commerce site can monitor current sales of hot products. Combining sales trends with relevancy data, the site can offer each visitor the hottest product that they’re most likely to buy.
Time series data goes through a life cycle. It’s generated by software to reflect a real-world event, such as a pressure valve reading or a completed transaction. The data then often goes into a pipeline, to move it on from the issuer and provide functionality such as data recovery and the ability to move to multiple potential consumers.
From the pipeline, the data is then transformed by software – for instance, it can be normalized or reformatted. A series of readings that tend to be several seconds apart, for instance, can be consolidated into a single record per minute, using JSON to handle the resulting semi-structured data. (With SingleStore, this can happen during ingest, via the Pipelines capability, including the use of Pipelines to stored procedures.)
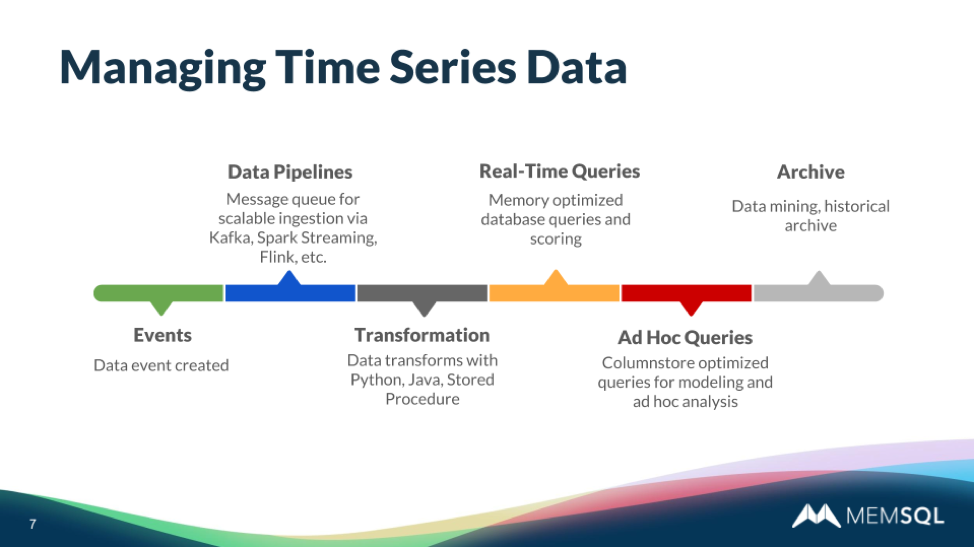
To effectively support time series, a database needs to meet specific requirements in terms of its ability to support transactions; its scalability; its effectiveness as an operational database; and its usefulness and responsiveness for analytics.
Mike delivers a summary assessment of different kinds of database on each of these axes – transaction support, scalability, operational capabilities, and analytics support. For instance, a NoSQL database is likely to be scalable – but unlikely to be all that useful for analytics, because of the very fact that it doesn’t support SQL.

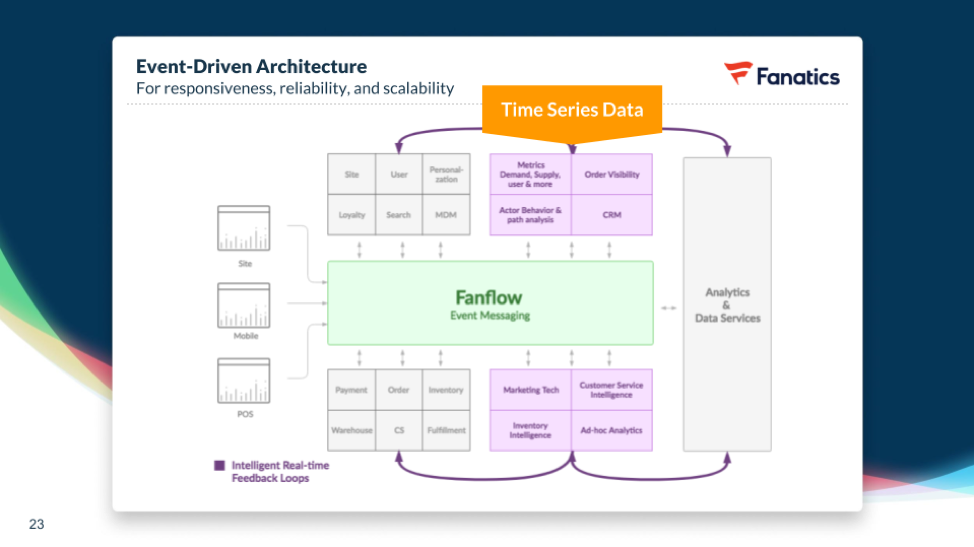
Fanatics, the leader in branded team merchandise from the NBA, NFL, Champions League football (soccer) teams, and many others, is a proud user of SingleStore. They are also a great example of time series data in use.
All the data that Fanatics takes in – from their website, from mobile users, and from point of sale (POS) systems – has time series aspects to it. In the NFL playoffs, for example, sales of team jerseys for the Super Bowl contenders and winners are going to spike.
Fanatics can use time series data in the run-up to the big game to predict jersey sales for the winning team and gear up production accordingly. Heck, maybe they even have advance insight into who’s going to win each Super Bowl – but if so, they haven’t shared it with us.
The webinar finished with a brief Q&A, including these questions and answers on time series, implementing SingleStore, and SingleStore vs. other databases.
Does SingleStore perform integrity constraints while streaming?
Yes, of course. It depends on how fast the data is coming in, whereas full checks.
What do you do if you get bursts of old data? For example, some of our devices don’t have an Internet connection, so the data comes in in bursts.
With SingleStore, you can use the transaction capability to integrate the out-of-sequence data. And you can use tools that come with SingleStore to help you write queries that give you good answers to data series that have gaps.
How does SingleStore perform against Redis?
Redis has somewhat limited analytics, it’s not really suited to exploratory analytics. To support that, you then have to copy the data into something else. SingleStore avoids that by
Can you say that, using SingleStore, we can skip using data lakes?
Yes, we have a customer that is doing this, using SingleStore instead. However, we also have an HDFS connector, so you can also use Hadoop as a data lake, then move appropriate data – or all the data – into SingleStore.
How is SingleStore compared to Snowflake?
Snowflake is a one-workload environment that’s very good at data warehousing, as is SingleStore. Where we differ is that SingleStore was additionally designed for fast data ingestion, and will give you much better performance. SingleStore also runs many more places – basically everywhere, vs. just two public clouds for Snowflake. Snowflake can also become quite expensive if you run it continually.
Intrigued? It’s easy to learn more. View the webinar, including Q&A, and download the slides here.








