Posts by
Gary Orenstein
Former Chief Marketing Officer, SingleStore
GO
Trending
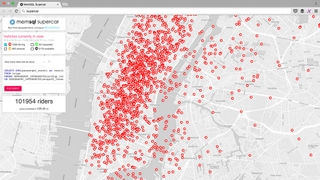
March 30, 2015Real-Time Geospatial Intelligence with Supercar

Trending
March 27, 2015In The End We Seek Structure

Trending
March 17, 2015SingleStore at Spark Summit East

Trending
March 6, 2015SingleStore at the AMP Lab

Trending
February 24, 2015Data Stores for the Internet of Things
Building a Gen AI App?
Build it on the database designed for AI applications.

Trending
February 18, 2015Big Data, Big Fun! Visit SingleStore at Strata Booth 1015

Product
February 11, 2015Operationalizing Spark with SingleStore

Trending
February 6, 2015Closing the Batch Gap

Trending
January 16, 2015The Rise of the Cloud Memory Price Drop

Data Intensity
January 6, 2015A Sensor In It, A Database Behind It

Product
December 18, 2014Full Speed Ahead
Showing 0 of 0 items