

This is the first part of a two-part blog post; part two is here. The recent release of SingleStoreDB Self-Managed 7.0 has fast replication as one of its major features. With this release, SingleStore offers high-throughput, synchronous replication that, in most cases, only slows SingleStore’s very fast performance by about 10%, compared with asynchronous replication. This is achieved in a very high-performing, distributed, relational database. In this talk, available on YouTube, Rodrigo Gomes describes the high points as to how SingleStore achieved these results.
Rodrigo Gomes is a senior engineer in SingleStore’s San Francisco office, specializing in distributed systems, transaction processing, and replication. In this first part of the talk (part two is here), Rodrigo describes SingleStore’s underlying architecture, then starts his discussion of replication in SingleStore.
Introduction to SingleStore Clusters
Okay. So before I start, I’m just going to give some context and a quick intro to SingleStore. This is a rough sketch of what a SingleStore cluster looks like.
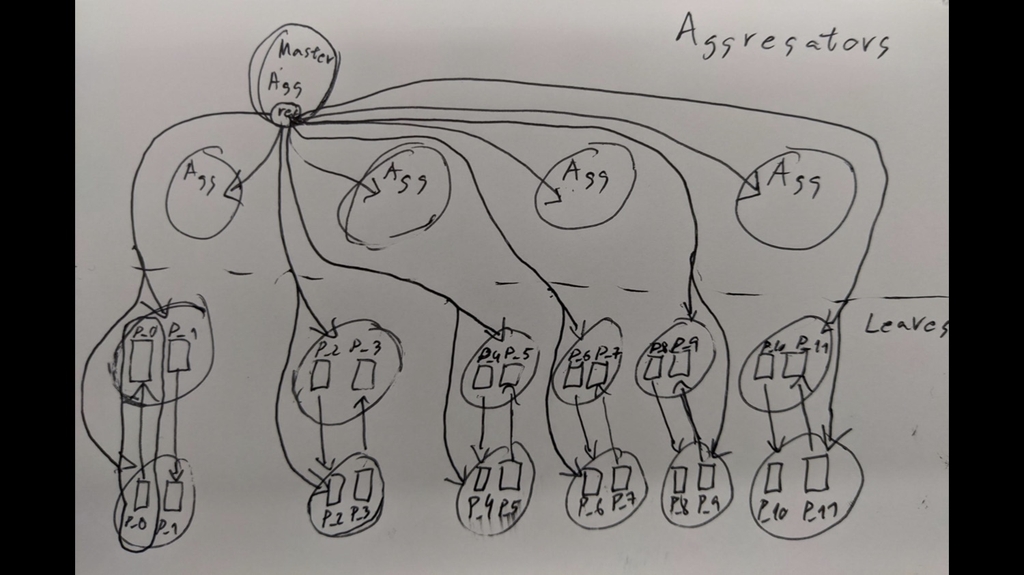
I’m not going to go into all of this. We’re going to explore a very small part of this; specifically, replication.
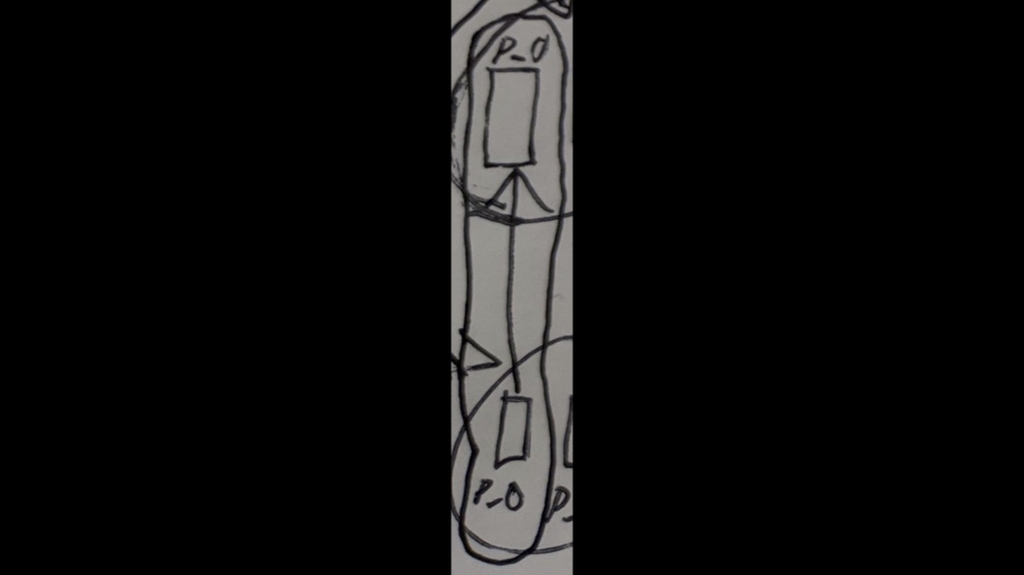
But to motivate why we need it, basically we have a database here, and that database is sharded into multiple partitions, and each partition has redundancy. And we do that so that we can provide durability and availability to our partitions. So if there are failures, you don’t lose your data; your transactions don’t go away. And today I’m going to talk about redundancy and replication within a single shard (of the database – Ed.).
Focusing on Transactions
So a quick intro, I’m going to talk about transactions. Transactions are what your application uses to talk with a database. So if you build an application, what it’s doing is it’s sending read transactions to the database to see what’s the status and also updates or writes or deletes to make modifications to that state.
And you want a bunch of very nice properties from transactions so that writing applications is easy. For today, the one we care about is that transactions are durable. What that means is that when the system tells you your transaction has committed, if you wrote something to the database – if you made a change to the state – and something fails, that change is not magically going to go away.

And the way you maintain durability, in most systems, is by doing two things:
- Maintaining a transaction log
- Replication
The first thing most systems do is they have a transaction log. What the transaction log allows you to do is persist to disk the binary format of your transactions. So you can imagine that you’re making changes to the database. You say, “Write the number 10 on my database.” And the way it goes about doing this is it first will persist that to disk before telling you that it’s committed or necessarily even making those changes visible.
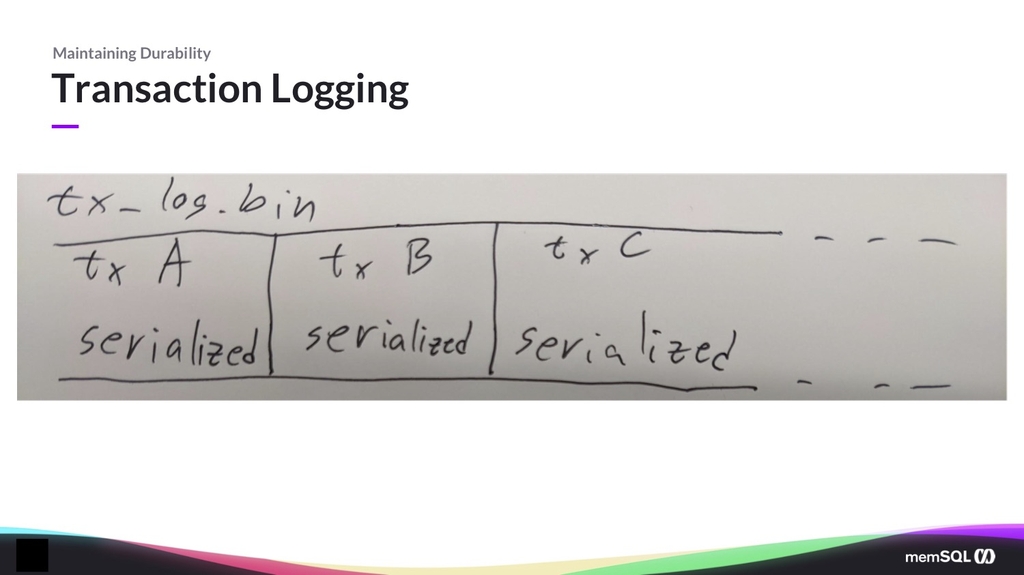
And when the disk tells you that the number 10 is going to be committed, you tell the user that it’s committed. This is an oversimplification, and a lot of this presentation is going to have oversimplifications, because replication, transactions, and durability is a fairly hard topic. I’ll try to note what oversimplifications I use, so that if you have any questions during the coffee break, I am very happy to talk about it.
But basically, transaction logging is what you use so that if you crash when you restart, you have a log of your transactions, and the user never hears that a transaction is committed before it’s persisted to the log. Some systems actually write the “how to undo the transaction” part first.
SingleStore has one simplifying factor, which is all the mutable state actually exists in memory, so you never need to undo anything. Systems that write to disk need to undo the changes because they might crash in the middle of doing them, but in memory we just lose everything and we just replay the redo log. So the problem is just how to apply them.
Replication and SingleStoreDB Self-Managed 7.0
The other way we maintain durability is with replication. This doesn’t give you just durability, this also gives you availability. The idea is that you never really want your data to live only on one machine. You want it to live on multiple machines, because you might lose one machine – and, even if it’s temporary, then your system is completely offline. So if it lives on some other machine, you can make it the new go-to machine for this piece of data.
Also, you might lose one machine forever. Imagine that – I don’t know – one of the racks in your data center suddenly went into a volcano, of its own will, and now it’s not coming back. But at least you always have another machine – hopefully, on another rack – that has all your data, and you just keep going.
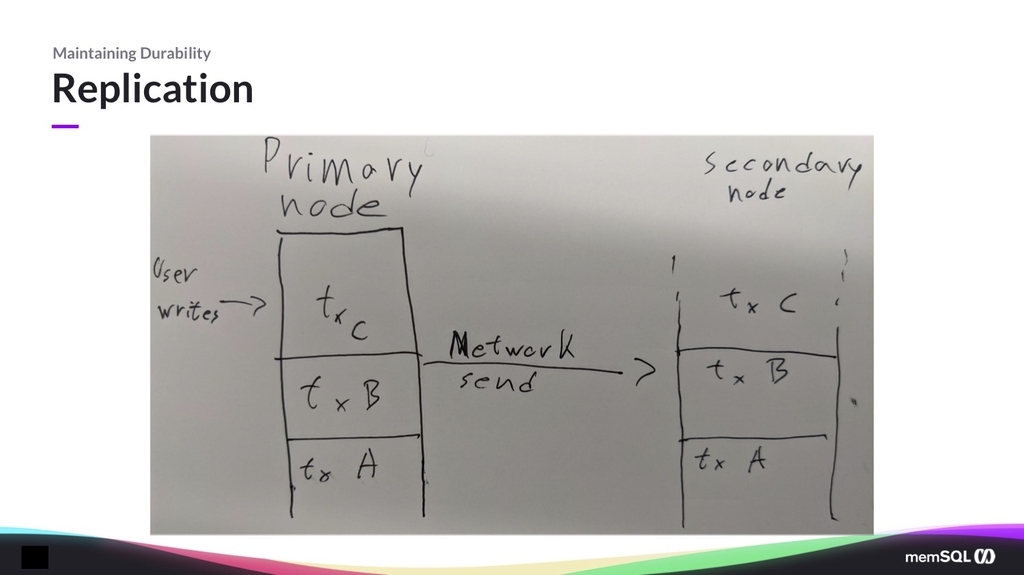
The type of replication I’m going to be talking about today is primary-secondary. (There are others, consensus being one of the other popular ones.) The idea with primary-secondary replication is that there’s one node that is the primary, and that’s what the user interacts with.
It doesn’t necessarily interact with the primary directly. An example is, in the SingleStore cluster we have an indirection layer, because the data is sharded. So we have one node that’s responsible to know where things go. But, for this presentation, you can assume that it’s the user interacting directly.
In SingleStore those would be the nodes we call aggregators, but they are kind of users of this copy. And then the primary node sends over the network, to the other nodes, the transaction log.
There are other kinds of replications. You can do statement replication, where you’re sending the statements the user sends you. Which is still kind of a transaction log, but we use physical replication and physical durability, which means that we actually persist all the effects of a transaction onto disk.
That allows us to actually do some more interesting things. Because with statements, the order of the statements matters a lot, whereas with transaction changes, the order doesn’t necessarily matter as much. So you just persist all the effects, and we just send over the network such that the secondary always has a logically equivalent copy.
So I’ve been working on this for longer than I care to admit – or than anyone else should know, outside of SingleStore – but we just shipped a revamped replication system in SingleStoreDB Self-Managed 7. I’m not going to describe everything we’ve done, there’s like 50,000 lines of code there. There’s not enough time in this day to describe everything that goes into it, but I will go through how you would build a replication system of your own. And I’m also going to go in some detail into one of the optimizations we made to make our new replication system very fast.

Again, be warned there’s going to be a lot of oversimplification. I’m going to gloss over things like failures. I’m pretty sure about two-thirds of those lines are failure handling, so that things don’t blow up, but let’s go into it.
Conclusion – Part 1
This is the end of Part 1 of this webinar recap. You can see Part 2; view the talk described in this blog post; read a detailed description of fast, synchronous replication in SingleStoreDB Self-Managed 7.0 in another technical blog post; and read this description of a technically oriented webinar on SingleStoreDB Self-Managed 7.0. If you want to experience SingleStore yourself, please try SingleStore for free or contact our sales team.

.png?width=24&disable=upscale&auto=webp)








