

This is the second part of a two-part blog post; part one is here. The recent release of SingleStore 7.0 has fast replication as one of its major features. With this release, SingleStore offers high-throughput, synchronous replication that, in most cases, only slows SingleStore’s very fast performance by about 10%, compared with asynchronous replication. This is achieved in a very high-performing, distributed, relational database. In this talk, available on YouTube, Rodrigo Gomes describes the high points as to how SingleStore achieved these results.
Rodrigo Gomes is a senior engineer in SingleStore’s San Francisco office, specializing in distributed systems, transaction processing, and replication. In this second part of the talk (part one is here), Rodrigo looks at alternatives for replication, then describes how SingleStore carries it out.
Considering Replication Alternatives
First, we should define what the goals are. What are the objectives? We have a primary and secondary, as before, two nodes – and we want the secondary to be a logically equivalent copy of the primary. That just means that if I point my workload at the secondary, I should get the same responses as I would on the primary.
What is highly desirable is performance. You don’t want replication to be taking a very long time out of your system, and you don’t really want to under-utilize any resources. So this goes hand in hand with performance.

At some point you’re going to be bottlenecked on the pipe of the network or the pipe to disk, whichever one is smaller, and if you are under-utilizing those pipes, that means you leave performance on the table, and you can get more.
So how would one go about doing this? Here’s what a naive solution would look like.
Now the idea is, when your transaction finishes before you make its effect visible – and this is somewhat based on what SingleStore does so it’s not necessarily the only way to do this – but it is kind of a useful abstraction of how one would go about doing it.
So you figure out how you’re going to serialize your transaction like the binary format, you write it to disk, you send it to secondaries, and you declare it committed. On the secondary, you’re just receiving from the primary, also persisting it to disk, because you should have your transaction log there and then applying it on the secondary as well. Does anyone know what is wrong with this?
Audience: You didn’t wait for the secondary to get back to you.
Exactly. So does anyone know why that is a problem? The answer was, you didn’t wait for the secondary to get back to you. So it might not be completely obvious, because you might think that the sends are blocking, but most systems would not do that. They would just say, I’m going to send and forget; right, it’s completely asynchronous. But there we’re not waiting for the secondary to tell us it’s received the transaction. What could go wrong with that?
Audience: Because then, if your first one dies, you’ll have corrupted data.
Yep. So here’s a helpful diagram I drew in my notebook earlier.
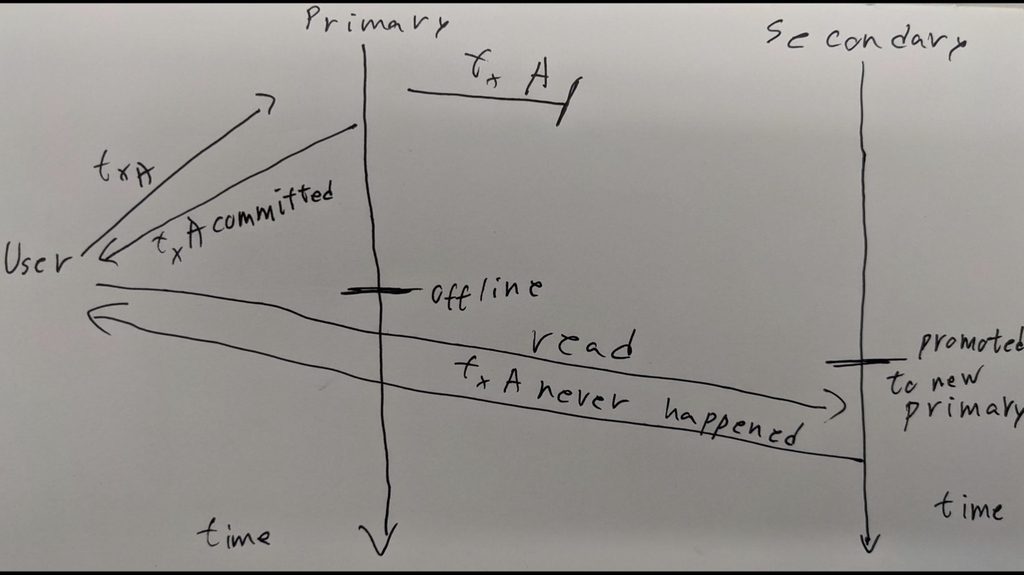
So the user sends a transaction, the primary sends it to the secondary, but it just kind of gets lost halfway. The primary says, okay, transaction has committed to the user – and then it goes offline. We promote the secondary to primary so that the workload can keep going. The user asks about its transaction and the secondary just says, “I don’t know, never happened.”
All right, so the way we fix it is we wait for acknowledgements. The secondary also has to send it back. Here’s a description of that.

Now what is wrong with this one? This one is a little subtler.
Audience: This is a typical two-phase commit approach.
Right. This is a typical two-phase commit, but there is still something incorrect here.
Audience: Now you have a problem with waiting for it – latency.
So that is a great point. We can wait forever here.
For this presentation, we’re not going to fix that. So we care that there’s a secondary that’s eligible for promotion, that has all the data. But if there is a failure in the secondary, you are never going to get an ACK because it’s gone.
Audience: Can’t you just get the ACK after the transaction is stored?
Well, but it’s stored in one place, you want it to be stored in two places, right?
Audience: Can’t you go from the transaction log and still load the disk, even if it fails?
Well, the log is on disk still, but we’re saying we want it on some different machine – because if your primary machine fails, you don’t want the workload to die, and you don’t want to lose data if your primary machine fails forever.
What you could do for this is you can have some other system that notices the failure in the secondary – and, in a way, demotes it from being a promotable secondary, and that way you don’t need to wait for ACKs from that secondary anymore. You would lose one copy of the data, but the same system can try to guarantee there is a new copy before it allows that to happen.
I’m always talking about a single secondary here, but you could also have multiple copies all ready. You don’t necessarily just have to have one other copy – and, in a way, that allows you to stay available. If you just have something detecting the failure saying, I don’t care about the secondary anymore, I have a copy somewhere else. Let’s keep going.
What else is wrong with this?
Audience: It looks slow. Can’t we send ACK right after sending to disk?
That’s a good observation.
Audience: Not before?
Before sending to disk, we can’t, because then if the secondary dies right there, your data is gone. We could do it right after sending to disk if all you care about is that the data is persisted, but not necessarily visible – and in this case, we kind of care.
But that means when you promote the secondary, you have to add an extra step waiting for the data to become visible so that you can use it. Otherwise you would get the same kind of problem. But at that point today it is persisted, so it will eventually become visible.
Audience: Can you send to the secondaries first? I know that’s strange.
There is nothing that stops you from doing that.
Audience: Then you can have a protection on the other side when the first one fails.
But it’s equivalent to having the transaction on the first one and then the other one failing. Right? You could do that. You could also just pretend the disk is one of your secondaries, and basically pretend it’s like a special machine, and now you just treat it the same way you would treat all other secondaries.
It’s actually a very useful, simplifying way for coding it, because then you don’t have to replicate a lot of logic. But disks are special; that’s one of the things I’m going to oversimplify here. We’re not going into how disks are special, because it’s awful. They tell you they’ve persisted their data; they haven’t. They tell you they’ve persisted their data – you write something to them, they overwrite your data. You have to be very careful when dealing with disks.
There’s something else wrong here, or there’s something… It’s wrong because it makes things very, very hard to code, but it’s weird. So imagine that you have many concurrent transactions running at the same time. How could that break things?
Audience: Are the transactions getting read from the secondary, or they all are always persisted by the primary?
Let’s assume they’re always processed by the primary.
So if you have multiple transactions going at the same time, they can reorder when they send to disk, and when they send to the secondaries.
Audience: Because if the first line takes too much, then the write …
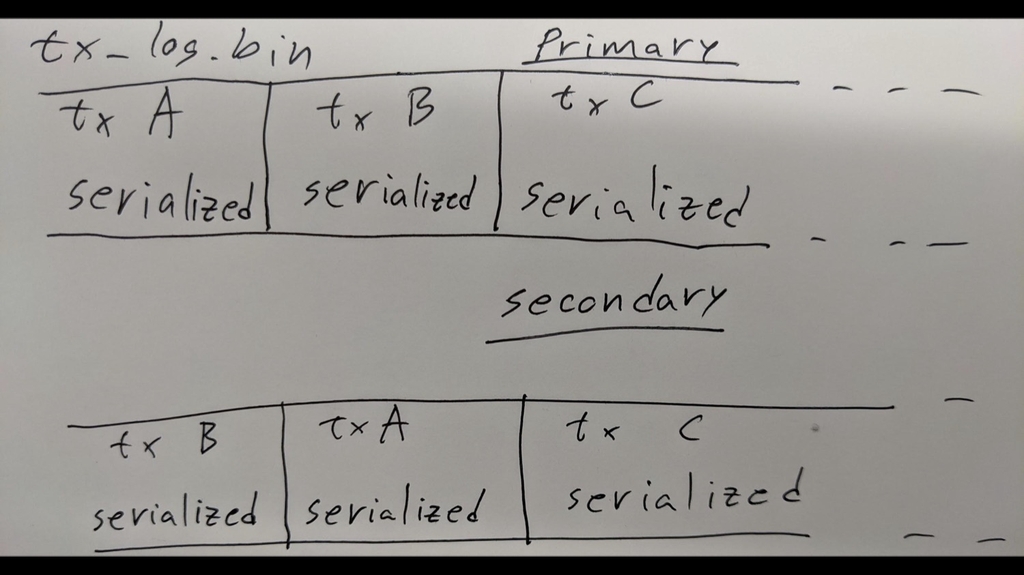
So you always have the guarantee that the secondary has all the data, but the transaction log is not necessarily the same. This is not necessarily incorrect, because the main goal we stated is that they are logically equivalent, and these two are logically equivalent. They have the same set of transactions in their transaction logs, but things become really tricky if you need to catch up a secondary.
So imagine that the primary fails, and you failover to a secondary, and maybe there’s another secondary, and now this secondary also fails, and now you have three different transaction logs. This secondary comes back up, and at this point, you don’t necessarily want to send everything to it from scratch, because that could take a long time.
The failures could be temporary, if your restarts are quick, or it could be a network issue that caused you to detect a failure – whereas the node was still online, and maybe the network issue just lasted a second.
And now, if you have a lot of data, it could take maybe an hour or more to provision this secondary from scratch. But you know that the secondary at some point was synchronized with you – it had the same transactions; you just want to send the missing transactions.
And now the transaction logs are different, though, so you don’t necessarily know what it’s missing compared to you. If the transaction logs were the same, then you know that there is an offset before which everything is the same.

That offset is actually not too complicated to compute when things are the same, because you know that if something is committed, if you’ve got an ack for that transaction, then everything before that transaction is the same on every node, if the transaction logs are the same.
And you can basically send that offset from the primary to the secondary saying, okay, everything before this has been committed – and you can either do it periodically, and in SingleStore we just do it kind of lazily. When we need to write something new, we just send that value if it’s changed, and so you can use that value as the offset, if everything is the same. If everything is not the same then you may have a different set of transactions before that offset on both. That offset just doesn’t make sense anymore. So how would we go about fixing this?
Audience: Okay. Can you just send the last version of the transaction log from the first one to the second one. The second one just grabs that and applies it?
Not sure I follow.
Audience: Imagine you said you have the transactions happening on one, and you send that transaction, together with data, to the second one. The second one grabs that data and persists both the transaction and the data itself.
Right, but-
Audience: What if you sent the transaction log already computed – the transaction log – and the second one just… So you always send a valid copy of the transaction log.
Oh, so I guess the idea is that, instead of sending when a transaction commits, you just send the log as you write to it. So you could do that. That becomes very slow, because you basically have to wait for the log to be written up to where you wrote to it. And that’s not necessarily going to be fast.
You can imagine you have a transaction that’s going to take an hour to write to the log, and then another transaction that’s going to write to the log next, and that’s going to be a bit slow. In a way, it’s a reasonable solution; it’s sort of what this is doing.
Basically, put a lock in there so that you send to disk and to secondaries at the same time, and you’re just going to send as you write to the log. The difference is the transactions can write to disk in that solution, all at the same time, and then only later does it send to the secondaries. But you still have to wait for that to happen.
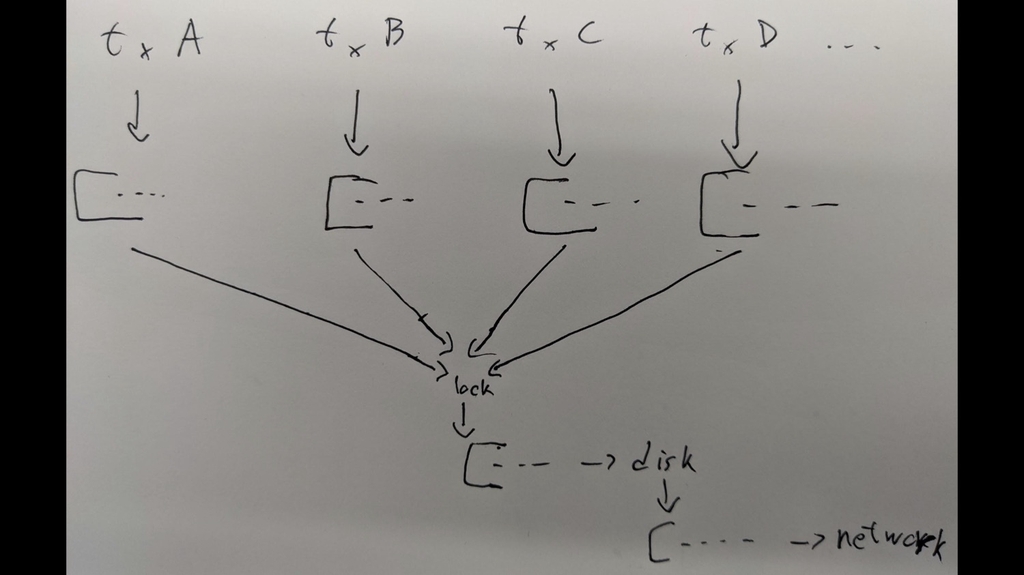
So I kind of spoiled it. One of the big issues here is that it’s going to be pretty slow. I drew a fun graphic here. So you can imagine you have a bunch of transactions all doing work, all doing progress at the same time, and then they’re all going to compete on the same lock. And this is not necessarily the exact way it’s going to happen, but you can imagine that if you read it just like here you’re going to send to disk first, and then send to the secondaries.
So while you’re waiting on the network, your disk is empty, or it’s not doing anything. While you’re waiting on disk the network is not doing anything. You could do these in parallel so you could like push this back, but there’s always going to be one that’s slower, either disk or network; and while one is executing, the other one is waiting for it.
That can be a pretty big performance bottleneck and that was actually something that could sort of happen on older SingleStore versions. So can anyone tell me what they would do to fix this? To avoid this bottleneck?
Audience: Generate, like, sequence numbers, since it’s the primary that processes all and the transactions and generates the sequence number for each one. Then send without logging to the secondaries, and the secondaries need to always know what was the last one that they wrote, and check if what they receive is the next one. Or if they should wait for… If they are receiving what was one, they receive three, so they know that two should arrive.
Audience: So basically moving the lock to the secondary. It’s the same performance?
Not quite the same performance.
Audience: The way it writes on the log.
So the suggested idea is, each transaction has a sequence number, and you write them in that order to the log, but you have to do it locally as well – which can also become a bottleneck, but you don’t need to lock around the sending over the network. And the secondary just has to make sure that it writes them in the same order.
That has the problem that it would still kind of lock on the disk, right? So you’d still be all waiting for this; each transaction has to wait on every other transaction to write to disk before it can send. So I think it’s still isn’t ideal, but it’s close, it’s very close.
Audience: What about the difference between that and also using a random generated number. So something like three options that just seem like the random generator and ID like in one, adjusting the one the three, and then two. You know already they are representing the same transaction but… just get the order correctly at the end on the second node.
I’m not sure I follow. So the idea is to add the random number generator-
Audience: To represent the transaction-
So each transaction has a unique ID basically.
Audience: Basically, but the transactions also could be represented by, let’s say, the three actions, like write, write, write. So you don’t have to wait on the disk; you persist with the the serial… but an order could be 3-1-2 for instance. But when you’re collecting information from the transaction log, we correct… The persistence on this should be…
So you persisted out of order but then you reorder them at the end?
Audience: Yeah.
That has the same issue as before, where you don’t necessarily have an offset to send things after. The problem from before was that computing where to start catching up, in a new secondary, is very hard, if things are ordered differently on different nodes. I think that would still have the same problem.
Audience: Is this solution like sacrificing the secondary start-up time?
No, you shouldn’t have to sacrifice the start up time. I’m going to count to five to see if anyone has any other ideas. One –
Audience: I think you can afford to have some rollback when you have conflicts, and if you have at least one piece that provides you the commits, to have some kind of eventual consistency. On top of that, you can have different groups of primary backups. And you can at least attenuate or diminish a little bit that lock. It won’t prevent it, but you’ll at least reduce it. So, different groups of primary backups, according to your workload? You could do some kind of sharding also.
You could do sharding, and it does help, because now you have some parallelism for different locks, but we still want it to be faster per shard.
How the Revamped Replication System in SingleStore 7.0 Works
So SingleStore does do sharding, and there were some debates we had over whether it’s a good idea to make replication much faster, because you still have parallelism across shards. We found that it was still a very good idea to do it, to make it really fast. All right, one, two, three, four, five. Okay.

It’s very similar to the sequence number ideas suggested initially. So this is one of the optimizations we implemented in Replog. There are a few others, but this is the one I’m going to go into more detail in here. Where you still allow sending to secondaries out of order, but you don’t just send the transaction content, you also send the offset, and the log where it’s written, and the way we do that…
So you have to be very careful when you do that, because you can’t just write to the disk – otherwise, if you have two concurrent writes, they might just write on the same offset. What we do is we have a counter for each shard that says where we’re at on the disk, and every time we want to write a new transaction to the log, we increment that counter by the size of the transaction, and the current value of the counter gives us the current offsets, and you can do the incrementing at an atomic manner without using locks.
The hardware is sort of using locks but it’s pretty fast and then you have your offset and then you just have to… You know that no other thread, no other transaction, is going to touch your reserved portion of the disk, and so when you write to disk, there are no locks there. The socket still sort of has a lock, it doesn’t even need to be an explicit lock. Like when you call send on the socket, it will go to the OS, and the OS will just send everything serially. But at that point you just send the offset, and the transaction log content, and you’re able to effectively max out the network pipe at least.
Audience: Don’t you have an empty disk space at this portion if you reserve the offset, but then it fails?
That is a great observation. Yes. So one of the great challenges of doing something like this is that, if something fails, you have portions of the disk that are empty, and now you have to be able to distinguish those from non-empty portions. And you also have to deal with those when trying to figure out where to do the catch-up.
For the catch-up part, it’s not actually very hard, we do basically the same thing as before. Because we have something in the background in our replication system that knows an underestimate of everything below this offset is already committed. And so you know that everything below that offset doesn’t have any gaps, and so it is safe to use that offset to start catching up.
Above that offset, the challenging part is: suppose that your primary fails, and you have a secondary that has a hole, you have to know how to identify that hole. And what we do is – actually, there’s a lot more that we do that’s not here – but we basically have a checksum for each transaction block that allows us to distinguish between something that was written. So we just read the entire log and check against the checksum and something that’s a hole – or we call them, torn pages – and that allows you to kind of skip it. And we can basically overwrite other secondaries’ logs with that hole, and they know to skip it as well, if they need to recover.
Audience: If you’re applying the log right after writing the log to disk – if you have a gap, you’re basically applying the transaction in the wrong order.
Not necessarily. That’s actually a great question.
Audience: Unless they are commutative.
Right. So the question is, if you have a gap, and actually if you’re just replicating out order, and you’re applying right when you received the data, you might be applying things out of order – and that is true. You’re not applying things in the same order as in your primary necessarily, but they are going to necessarily be commutative, because you can’t have dependencies on a transaction that is going to commit by another transaction.
If you have a hole, that means that everything in that hole or that gap is not committed yet necessarily, because you haven’t acknowledged it. So if you’re going to apply something after the gap that you’ve already received, that means that the two transactions are running concurrently, and are committing at the same time. And if that is true, then they will not conflict, because they both validated their commits at the same time.
Audience: Oh, when you reach this point, you already validated… so they are commutative.
So in SingleStore, we actually use pessimistic concurrency control, which means that they just have locks on everything they are going to write, which is how we can guarantee at that point they’re not going to conflict. You could have other mechanisms, with optimistic concurrency control, where you just scan your write set. If we did that at that point, we would already have validated.
Audience: You forgot to mention what is the isolation level provided by SingleStore.
So today it is pretty bad; it’s read committed. Read committed isolation level just guarantees that you’ll never read data that was never committed, but it’s pretty weak. Because you might read something in the middle of two transactions – for example, you might see half a transaction, and half another. That’s actually what I’m going to be working on at SingleStore for the next few months, increasing the isolation levels we support. So pretty exciting stuff.
The main reason we don’t have higher isolation levels right now is that, due to the distributed nature of the system, everything is sharded. We don’t have a way to tell between two shards of the data, that two rows were committed in the same transaction, right now. And so within one shard we actually do support higher isolation levels, that you can do snapshot reads, which guarantees you that you don’t ever see half a transaction. And it’s fairly easy to build on top of that for snapshot isolation or even read committed when performance.
But we are working, for the next major release of SingleStore in a few months, to have higher isolation levels, hopefully. We are all engineers here, we all know how planning can go. How am I doing on time?
Audience: Good. We are okay.
So does anyone have questions about this?
Audience: The only kind of weird question I have is it feels weird to not write to disk continuously. I’m not sure if that’s actually a problem.
When you say continuously, you mean like always appending, right?
Audience: Yes, always appending, because it’s weird to go back in offsets and writing to disk.
It may feel weird, but it’s actually not a problem, because you kind of still write continuously when you reserve here. So one way to think about it is when you’re writing to a file, if you’re appending at the end, you’re actually doing two operations. You are moving the size up so there’s a metadata change on the file system and you’re also writing all the pages to disk. And what we’re doing is moving the size change into the transaction. So these two operations together are sort of equivalent to writing at the end of the file in the file system because it’s still two operations.
That’s actually a tricky thing, because if you’re doing synchronous writes to a file, and your file is not a fixed size, and you’re moving the size up, your writes might go through and tell you they’re persisted, but the metadata change could be independent. And so you have to either pay a very high cost to make sure that the metadata change goes through, and it’s persisted, or you can pre-size files, which is what we do.
But that has the separate costs that now you have to keep track of the ends of your log separately, and manage that yourself. So you still need that metadata somewhere. We just thought we could do better. I think we do better.
Any other questions? Right. That is it for the presentation. We are hiring in Lisbon if anyone’s interested in working on interesting problems like this one. We also have other teams that work on different types of problems – like front-end, back-end systems management. And if you have any questions about this presentation, the work we do, or if you’re interested, we have a bunch of people from SingleStore here – right now, and later. Thank you.
Audience: Okay. Thank you Rodrigo.
Conclusion
This is the conclusion of the second, and final, part of this webinar recap. You can see part one of this talk; view the talk described in these two blog posts; detailed description of fast, synchronous replication in SingleStore 7.0 in another technical blog post; and read this description of a technically oriented webinar on SingleStore 7.0. If you want to experience SingleStore yourself, please try SingleStore for free or contact our sales team.



.png?width=24&disable=upscale&auto=webp)




