As a developer you spend a lot of time making choices. Do you use React or Vue for your web app? Will your algorithm run faster if you use a hash table? Developers are acutely aware that these kinds of decisions are often not obvious or intuitive. In the case of React vs Vue, you might spend some time reading docs or looking at open source examples to get a feeling for each project. When deciding between data structures you will probably start muttering about "Big O" to the confusion of non-programmers around you.
What do these choices all have in common? They depend on another set of tradeoffs made by the programmers at the next layer down the stack. The application developer depends on the framework engineer, the framework engineer on language designers, language designers on systems programmers, systems programmers on CPU architects... it's turtles all the way down. (unless you are an electrical engineer, although perhaps silicon miners might even argue that point)
One of the decisions that some developers have to make is which database to use. I don't envy someone in this position - you have hundreds of options and a lot of FUD (fear, uncertainty, and doubt) to dig through. It's no wonder that many of my friends simply pick what they have used before. What's that old idiom…? "Better the devil you know than the devil you don't".
This blog post is for those of you who have to choose a database. I'm not here to convince you that SingleStore is the best database, I am going to explain some of the key trade offs we had to make, and what we ultimately decided to do. Enjoy!
TLDR; Here is a quick and extremely concise summary for people who are already familiar with these problem spaces:
| Design Decision | SingleStore's choices |
|---|---|
| Horizontal vs vertical scalability |
|
| Column-oriented vs row-oriented storage |
|
| Physical storage choices |
|
| How to protect from data loss? |
|
| How to make queries go fast? |
|
Tradeoff #1 - Horizontal vs vertical scalability
As applications require more data, it's getting harder to fit everything into single-server databases. SingleStore's goal is to support data-intensive applications which combine a continuously growing data footprint with the need to support many different kinds of workloads. This ultimately requires the ability to scale the database out into a cluster of servers which drastically increases the available CPU, RAM, and Disk at the expense of coordination, network overhead, and classic distributed systems problems.
Historically, some large data-intensive companies have tried to solve this problem by manually splitting their data across many single-server databases such as MySQL or Postgres. For example, putting each user along with all of their content on a single MySQL server. Assuming that an individual user's content never grows too large, this strategy works well for a portion of their transactional workload. But what happens when you want to ask a question about all of the users, or look up the friends of a particular user? Eventually, companies with this architecture are forced to build custom "query proxies" which know how to split up and aggregate the result of these questions from multiple single-server databases. You can read more about the complexities of this architecture in this great post by Michael Rys.
SingleStore has been designed to handle data-intensive applications from the very beginning. At the surface level, we look a lot like the final result of the architecture outlined above: a bunch of individual servers each storing a portion of the data and an intelligent query proxy that knows how to split up and aggregate the results to answer questions. But with anything this complex, the devil is in the details. Since SingleStore clusters natively know how to work together as a whole, we are able to move data during query execution in a highly optimal manner. As an example, here is how a distributed join might be executed in SingleStore.
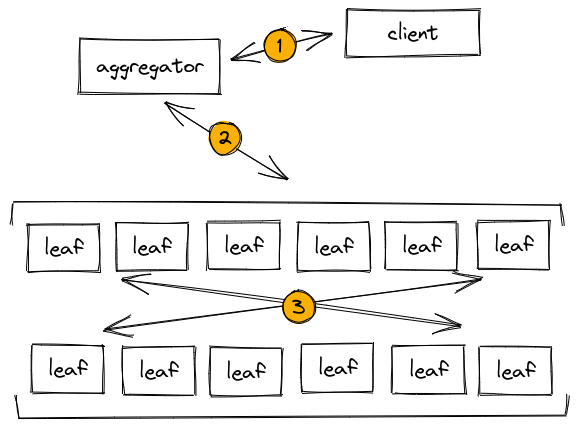
In this image we see a series of steps. First, the client sends a query to an aggregator node. Aggregators are query proxies which contain a copy of the cluster's metadata so they know how to intelligently access the data stored in the cluster. The aggregator inspects the query and then tells the worker nodes (which we call leaf nodes) what to do. This process is called query planning and is key to our ability to scale horizontally. Finally, the leaf nodes process the query, potentially exchanging partial results as they go.
But horizontal scaling isn't without its tradeoffs. Once you distribute the data between multiple nodes, common relational operators such as joins, group bys, and window functions become much more difficult. As an example, let's say we have the following schema:
create table orders (
id int,
userid int,
status enum ("open", "shipped", "cancelled", "fulfilled")
);
create table lineitems (
orderid int,
productid int,
quantity int
);Using this schema, we might want to retrieve the top ten largest orders (by quantity):
select orders.id, coalesce(sum(lineitems.quantity), 0) as total_quantity
from orders
left join lineitems on orders.id = lineitems.orderid
group by orders.id
order by total_quantity desc
limit 10;But how should the database execute this query? Let's assume that the rows within each of these two tables are distributed randomly among SingleStore leaf nodes. In this case, in order to execute this query we will need to somehow "repartition" either the orders or lineitems table to ensure that for each order row, the node has access to all of the corresponding lineitems. Unfortunately this leads to excessive network usage during query execution in order to dynamically repartition the data.
To help solve this problem, SingleStore supports the concept of defining a shard key on each table. A shard key tells the database that rows with the same value for a set of selected columns should be colocated within the same partition. Applying this knowledge to our schema we get:
create table orders (
id int,
userid int,
status enum ("open", "shipped", "cancelled", "fulfilled"),
shard (id)
);
create table lineitems (
orderid int,
productid int,
quantity int,
shard (orderid)
);The additional shard() declaration tells SingleStore to ensure that all of the lineitems associated with each order are on the same partition as the order. This means that if we run the top-10 query above, the database will be able to execute the join locally without first repartitioning any of the data.
As a final point on horizontal partitioning, it's important to understand the pros and cons of modulo hashing (what we do). In order to determine which partition to store a particular row, SingleStore hashes the columns in the shard key and then uses modulo arithmetic to determine which of a fixed set of partitions to use. Let's consider the advantages and disadvantages of such an approach.
Advantages:
- Performance: any node in a SingleStore cluster can instantly know where they can find a given row without coordination.
- Can push down 100% of the work for certain relational operations into individual partitions, minimizing cross-node traffic during query execution.
Disadvantages:
- Very expensive to change # of partitions and requires moving most of the data.
- Can result in some partitions being larger than others (ie. data skew).
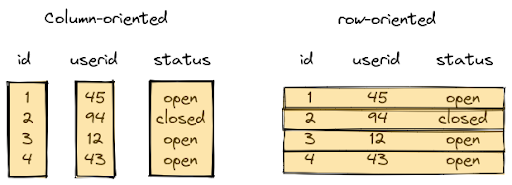
Column-oriented and row-oriented storage are at two ends of a performance spectrum. This makes deciding between them quite difficult. If you think about your table as a spreadsheet, column-oriented storage means that each column of the sheet is stored as a separate list. Row-oriented storage, on the other hand, means that each row of the sheet is stored as an object, and those objects are stored in a list. Before we talk about the features of SingleStore's storage solution, it's important to take a look at the pros and cons of traditional column-oriented and row-oriented storage.
Traditional column-oriented storage:
- Optimized for analytics.
- Rows are stored separated by column.
- Column scans can take advantage of advanced CPU operations.
- Can take advantage of sorting the data to skip large amounts of data in certain query shapes.
- Filters can operate on batches of rows at the same time, allowing for advanced optimizations such as vectorization and filtering on compressed data.
- Optimized for batch writes (i.e. 1000s+ rows per write operation).
- Accessing multiple columns requires multiple read operations.
- Coarse row locks.
Traditional row-oriented storage:
- Optimized for transactions.
- Rows are logically stored as objects in a set.
- Supports one or more sorted and hash indexes.
- Data mutations can happen in place, resulting in great transaction performance.
- Optimized for small write operations
- Granular row locks.
SingleStore started off as a row-oriented database, but in our desire to be the best database for data-intensive applications we needed to build both storage engines and figure out how to make them work well together. Our solution is now coined Universal Storage, designed to be the best of both worlds.
The approach we decided to take was to improve transaction performance of column-oriented storage rather than attempting to bring column-oriented benefits to row-oriented storage. We decided to do this because it's not possible to match or even approach the scan performance of column-oriented storage using row-oriented data structures. On the other hand, it's possible to improve the performance of small read/write operations on column-oriented storage such that it's within 30%-50% slower than the equivalent workload on row-oriented storage. To do this, we implemented four key features in Universal Storage that provide most of the benefits (for now): using a row-oriented write buffer, seekable encodings, row-level locking, and hash indexes.
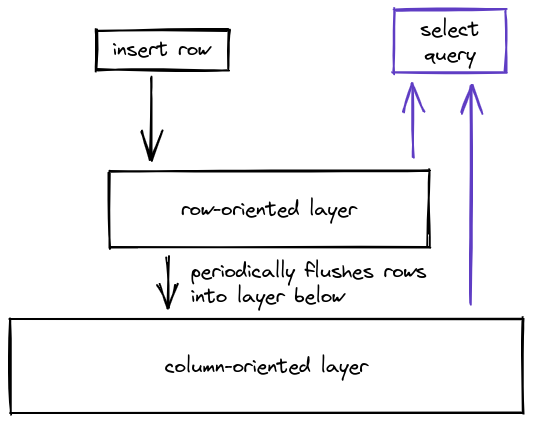
First, let’s talk about the row-oriented write buffer. Remember when I said that SingleStore built a row-oriented storage engine as well as a column-oriented storage engine? It turned out to be a great decision. In order to handle small writes as well as large batches, we place small write operations into a row-oriented storage layer which sits in front of our column-oriented layer. Since both storage engines support queries, we can serve results immediately without waiting for the small write operations to "flush" into the column-oriented layer. Our row-oriented write buffer helps data mutations as well. Update queries are executed by marking the row-offset as deleted in metadata, followed by an insert into the row-oriented buffer. This allows Universal Storage to satisfy many transactional workloads while keeping the columns stored in large immutable files for optimal scanning performance.
Seekable encodings allow Universal Storage to accelerate small read operations. In order to read a row from column-oriented storage the engine has to load one or more large compressed files from disk. This becomes painful when you try to read a small number of rows if each individual read involves opening a massive compressed file, decoding it, and seeking to the row in question. To solve this problem we rewrote all of our column encodings to support seeking before decoding. In effect this means that rather than reading an entire file to retrieve one row, we now only need to read a very small portion of that file.
The next feature, row-level locking, is simply hard to do. The idea is pretty simple: if a transaction is mutating a row we should not block transactions mutating other rows. To achieve this in column-oriented storage requires building an additional layer of metadata which tracks which row offsets are locked, along with their parent transactions. The difficulty comes from doing this in a performant way and not consuming too much memory while you do it. Let's just say that SingleStore has a lot of experience optimizing memory usage.
At this point we have accelerated small write operations, optimized small reads, and unblocked concurrent transactions. The only thing left to do is make sure we can locate individual rows quickly. To do this we built unique and non-unique hash indexes into Universal Storage. These indexes allow the engine to quickly lookup rows by value. This is important for everything from "key = value" style queries to nested loop joins. In addition, our unique hash indexes support upsert queries. Upsert queries allow you to insert a row if it doesn't exist or update the row if it does, which is a requirement for many data-intensive applications.
While Universal Storage tries to be the best combination of both extremes, one of our philosophies is to provide developers with the tools they need to optimize their workload. In some cases it may be necessary to pin an entire table to row-oriented storage. As an example, imagine you have a table representing an object cache. The application is constantly running inserts, updates, and deletes to manage the cache while serving low-latency reads on cache keys. Row-oriented storage will provide predictable and minimal latency for this particular workload.
Universal Storage allows you to take advantage of both row and column oriented storage in the same database with minimal compromises. This feature optimizes SingleStore for data-intensive applications, and ultimately puts the power to handle any data-intensive workload in your hands.
To learn more about Universal Storage, check out this series of blog posts by Eric Hanson:
- Shattering the Trillion-Rows-Per-Second Barrier With SingleStore
- Universal Storage
- Universal Storage Episode 2
- Universal Storage Episode 3
- Universal Storage Episode 4
Tradeoff #3: Physical storage choices
At the surface level, relational databases store rows in tables (or if you are academically inclined, they store tuples in relations). Without any additional information, we might believe that the underlying physical storage roughly looks the same as the surface level. Unfortunately it's not that simple.
As we discussed in the previous section, SingleStore has two primary storage engines: Universal Storage (column-oriented) and row-oriented storage. Within each of these engines there are numerous decisions to make about how to physically lay out data. Let's take a look at each.
Rows stored in Universal Storage are physically placed into a log-structured merge-tree (LSM tree). LSM trees organize data into a series of layers, each layer composed of one or more sorted runs.
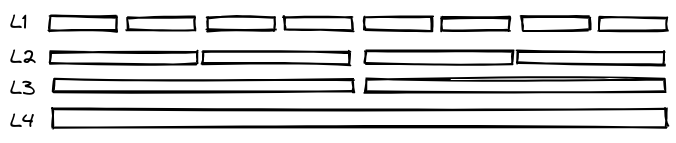
In Universal Storage, each row is contained by a segment along with roughly one million other rows. All of the segments are individually sorted by one or more columns as specified by the user. While building segments, we track the minimum and maximum value of each column. This metadata allows the engine to sort the segments into sets of non-overlapping sorted runs. It's these sorted runs which make up the layers in the LSM tree (and each of the boxes in the diagram above).
This is where it gets interesting. SingleStore periodically merges rows into the next layer lower. If you want to learn about the specific heuristics we use, please read this paper. The TLDR is that each layer is larger than the previous layer. The purpose of these layers is to improve the selectivity of segment elimination and reduce the number of segments in the system (smaller segments are merged together as part of this operation). Segment elimination is one of the ways that column-oriented storage can have interactive query performance over massive data volumes. When SingleStore processes a query which filters on a table's sort key, we are able to filter the sorted runs and individual segments before we start looking at individual rows. When each segment may contain a million rows, successful segment elimination can result in the engine scanning significantly less data.
Tying this back into the previous section on Universal Storage, the uppermost layer in our LSM tree uses a row-store table rather than sorted-runs of segments. This feature ensures that small writes are available immediately for querying and that we only write out segments with a sufficiently high number of rows.
Our second storage engine, row-oriented storage, stores each row in memory (with a durable copy on disk in the transaction log). In order to efficiently query the table, one or more skip-list or hash table data structures are allocated as well with pointers to the underlying row structures. I highly recommend reading The Story Behind SingleStore's Skiplist Indexes by our CTO Adam Prout to understand the details behind our row-store storage system. The TLDR is that it's highly optimized for ultra-low latency read and write operations making it suited for data-intensive transactional workloads.
For details about the specific indexes we support in SingleStore, be sure to check out our documentation: Understanding Keys and Indexes in SingleStore.
Tradeoff #4: How to protect from data loss?
Obviously data loss in a database is bad news, and is something that should be avoided at all costs. But with any engineering decision, there are tradeoffs that need to be made. SingleStore protects your data using three key features: high availability, unlimited storage, and incremental backup/restore.
The first feature, high availability, comes into play whenever you commit a transaction. As your application writes to the database, each change is transmitted to two partitions before the commit completes.
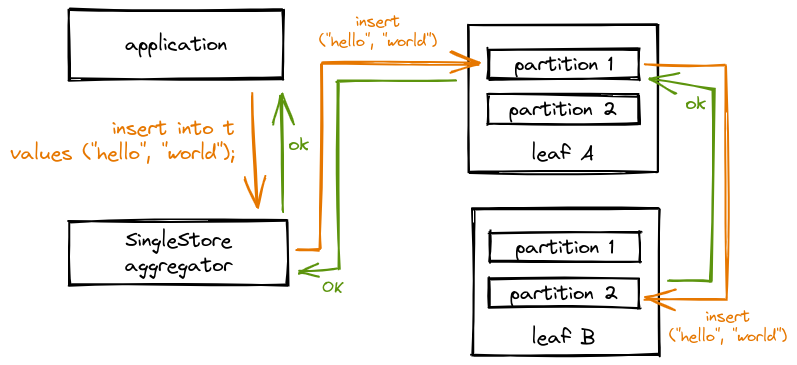
In this diagram, we can see the change first propagates through the cluster (the orange arrows) before returning “OK” back to the application (the green arrows). Note that part of the change propagation flows from one partition to another, in this post I will call the first partition the "leader" and the second partition the "follower". There are three critical features in our architecture that allow us to maximize write performance:
- Only the change log is sent from a partition to it's follower (add this row, update that row, etc). This minimizes the amount of network traffic required for synchronization.
- Log replay on the follower partition happens asynchronously which means that in the event the leader partition fails, the cluster will pause queries until the follower partition has finished replaying the log. In most production scenarios followers are rarely more than a couple seconds behind their leader. The increase in write performance is well worth a delay during failover.
- The log messages are asynchronously flushed to disk. This means that the simultaneous failure of two nodes could incur data loss. Since our disk writes are rarely far behind and simultaneous failure is extremely unlikely, once again the write performance tradeoff is worth it.
- For certain workloads this performance-durability tradeoff may not be acceptable, so in SingleStore you can optionally force transactions to wait until the data has been flushed to disk. In most cases, our customers have found that our default durability is sufficient.
As SingleStore continues to grow, we will make more investments to reduce the already low probability of failure. One of the key initiatives here is to support synchronous writes to more than just two partitions.
The second durability feature, unlimited storage, has many more benefits than just durability. Unlimited storage allows SingleStore to flush data off of the cluster and store it safely in your favorite blob storage solution. In addition to providing long term data durability, unlimited storage also enables an entire suite of separation of compute and storage functionality. If you are interested in the power of unlimited storage, please check out the following resources:
- Blog Post: Separating Storage and Compute for Transaction and Analytics
- YouTube: Separating Storage and Compute for Transaction and Analytics
The Singlestore Helios leverages unlimited storage to enable cluster suspend/resume. Stay tuned for more exciting features soon. :)
The third durability feature, backup, is something that every database has to have. Not a lot of tradeoffs here to be honest - but I am happy that we have an incremental option which prevents you from needing to make a full copy of your data. Incremental backup combined with sending backups directly to blob storage gives you peace of mind that you are protected against data loss or an unfortunate migration.
Tradeoff #5: How to make queries go fast?
High-performance is never the result of a single silver bullet - it requires the entire system to be built with speed in mind. SingleStore emphasizes that throughout all of our design decisions. But there are always some decisions which are almost entirely driven by the need for speed - and that's what I want to talk about here.
Since the beginning, SingleStore has included a full compiler toolchain to turn SQL queries into optimized machine code. At first, we literally included GCC and transpiled queries to C++ before compilation. While this implementation was effective at accelerating query performance, it was slow to compile and difficult to maintain. Luckily for you, things have improved substantially. Nowadays, we compile queries into a custom intermediate-representation called MBC which then gets compiled to machine code by LLVM to execute. Our initial version made it much easier to run and maintain SingleStore, but still caused queries to wait for compilation to complete on their first execution. This downside of query compilation hurt our ability to be used for ad hoc workloads. To fix this issue, the latest iteration of our execution engine interprets queries during compilation and then hot swaps in the optimized result when it is ready.
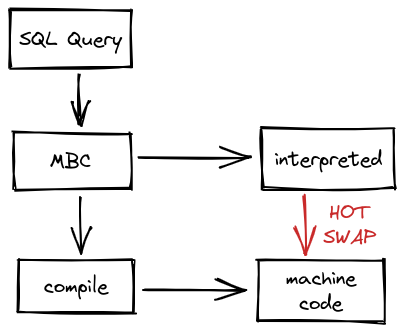
This is just... so cool. It allows us to provide the best of both worlds: we can start executing the query immediately (potentially returning results right away) while compilation happens in parallel. If the interpreted execution finishes, then yay: customer gets the results fast. But if the compilation finishes first, then we HOT SWAP the optimized result into the running query which speeds it up even more. Overall, this results in a minimal impact to first run query performance especially for small queries where this issue tends to crop up the most.
I'll call out two other performance oriented features: automated statistics collection and vectorized SIMD execution.
Automated statistics collection is something we have added relatively recently in the history of SingleStore, and allows the optimizer to have up-to-date statistics for every column in every table. Column-level statistics include simple aggregations like "min", "max" as well as more complex concepts such as the distribution of values. Our cost-based optimizer takes advantage of this metadata to pick more performant query plans than it would otherwise select.
Vectorized Single-Instruction, Multiple-Data (SIMD) execution allows us to take full advantage of column-oriented storage. Basically, modern CPUs include specialized instructions which can operate on multiple pieces of data simultaneously. Let's say you want to multiply four numbers by two. Using normal CPU instructions this would require serially loading and multiplying each number. SIMD turns this operation into a single instruction which doubles the four numbers in parallel. So, you might be wondering how this applies to column-oriented storage. Since we store the values of a column together sequentially, we can efficiently load batches of values into the CPU and use SIMD instructions to do math in parallel. Instant performance boost? Yes please!
In conclusion
The goal of this blog post is to convey the particular set of choices we made while building SingleStore. Every database has to make tradeoffs, and we believe that for data-intensive applications SingleStore is a very compelling option for a database.
When selecting between horizontal and vertical scalability, SingleStore provides a high performance solution to scale out the database onto one or more servers. Universal Storage provides transactional performance usually reserved for row-oriented storage on top of our column-oriented storage engine. To do this we needed to build two entire storage and query execution engines with a particular set of physical design decisions. Backing all of this up is our durability story which ensures that you have peace of mind that your data is safe with SingleStore. Finally, to better support data-intensive applications, we implemented a number of advanced features which directly increase our query performance. In summary: if your application is data-intensive you should seriously consider using SingleStore as your database.
Try SingleStore!
Ok, time for my attempt at a marketing pitch. If you got this far (or skimmed this far) chances are you found something in this post interesting. So, the next time you are starting a new project or have a couple of minutes to play with a new piece of tech - I hope you'll consider SingleStore. I use it for new projects all the time, and I highly recommend using either our "cluster in a box" docker image or the managed service to get going. I'll include links to all of this (and other useful resources) at the end of this post.
If you have any questions about any of the decisions we made when building SingleStore or if you have any questions whether SingleStore is a good choice for you, make sure to connect with the SingleStore community. It’s the best way to get all of your questions answered. I would also recommend checking out the SingleStore Developer page to find additional developer oriented content.
Thanks for reading!
- Carl
PS: Feel free to engage with me on Twitter! I appreciate all the feedback I can get! 😊
Resources
SingleStore Labs Github Organization
- Full of example projects and code samples.
- Start with this workshop to get building right now.
Get started with SingleStore with Joe Karlsson





