


In our Spring 2022 blog, we shared how the mechanics one of us used to work with anticipated the arrival of the Snap-On tool truck.
The mechanics were like kids waiting for toys from Santa! It's our pleasure to bring you — our application makers and fixers — the latest delivery of the SingleStoreDB tool truck, right in time for the holiday season!
In our latest release (Winter 2022, version 8.0 available on both Cloud and Self-Managed deployments), we're delivering over a dozen new features and tools that developers can use to build powerful real-time applications and analytics.
The features span transaction processing, analytics, JSON/semi-structured data, spatial, time series, full text, security, observability, etc. This release also enables administrators to deploy and manage SingleStoreDB with more flexibility, security and control than ever before.
Read on to learn about our new support for graph and tree data processing in distributed SQL with recursive common table expressions, fast transaction processing on string and JSON data with Universal Storage, enhanced security, improved incremental backup performance, Wasm programmability everywhere and so much more.
Developer Experience
Programmability for analytics on hierarchical data with Recursive CTEs
Common Table Expressions, or CTEs, enable users (devs/ DBAs) to simplify and improve the readability and maintainability of complex queries. When it comes to querying hierarchical data, database users often need to perform some SQL ‘acrobatics’ to get the right results (hierarchical data includes things like org charts or production bill of materials, where products are made of components, components are made up of subcomponents and so on).
While SingleStoreDB has always supported regular (non-recursive) CTEs, the 8.0 release will include support for Recursive CTEs as well. With recursion, a CTE can reference itself. The CTE is executed repeatedly, returning subsets of data until the complete result is returned. This makes it easier to write queries for hierarchical data. Users can now run graph and tree expansions in one SQL statement, instead of writing complex application code.
Recursive CTEs were one of the most frequently requested features in SingleStoreDB, and we can’t wait to see how customers make use of it in conjunction with SingleStoreDB’s multi-model capabilities.
Read more: SingleStoreDB Documentation — WITH Recursive CTEs
Laravel Driver
Some of the largest websites in the world are built using the scripting language PHP. PHP has always been great for creating apps with dynamic content that require interaction with databases, and Laravel is a popular framework that simplifies PHP development. However, one hurdle for developers was connecting Laravel with SingleStoreDB. A native driver for this connection did not exist, which means developers have had to use workarounds.
One workaround was to use the MySQL connector for Laravel. However, since this was built for MySQL specifically, it does not support all of SingleStoreDB’s functionality. Some developers tried to work around this limitation as well by doing additional work — like building tables that were specified as rowstore or columnstore, specifying things like shard and sort keys and making other adjustments for SingleStoreDB-specific functionality.
To remove these hurdles, SingleStore has released a native driver for Laravel. Developers can now work on Laravel and create SingleStoreDB objects (such as tables or indexes) without needing tedious workarounds.
The SingleStore Laravel driver is open-sourced and is available on Github where it has seen community contributions, including from Franco Gilio, CTO of Publica.la. Additionally, Fathom Analytics Co-Founder Jack Ellis is deeply involved with the Laravel community and has recently launched the online course SingleStore for Laravel.
SingleStore’s native driver for Laravel is available for both Cloud and Self-Managed deployments.
Read more: New Integrations for Laravel and Python
Additional Resources
- GitHub — SingleStore Laravel Driver
- Online course — SingleStore for Laravel (by Jack Ellis, CTO and Co-Founder of Fathom Analytics)
Cognos Connector (Cloud and Self-Managed)
IBM Cognos is an analytics software that has thousands of customers worldwide. However, to connect Cognos to SingleStoreDB, customers had to rely on MariaDB or MySQL connectors which were often unreliable, unsecure and resulted in connection errors. The problem was significant enough that some customers were willing to pay for third-party drivers (such as the one from Cdata).
SingleStore has partnered with IBM to build a native SingleStoreDB integration, or connector, for IBM Cognos Analytics. The connector is built on the SingleStoreDB JDBC driver.
The Cognos connector eliminates these issues and provides a fast, reliable and secure connection between SingleStoreDB and Cognos Analytics to power analytical applications.
Read more: SingleStoreDB Documentation — Connect with IBM Cognos Analytics
Playground
The new SingleStoreDB Playground provides a free, open (no login needed) and easy-to-use “Hello World” experience to users unfamiliar with SingleStoreDB. Users can explore SingleStoreDB without the usual hurdles of learning a new database, finding and loading datasets, or writing SQL.
The Playground provides hands-on experience with armchair comfort. Users can run prewritten queries, or can choose to write and run their own queries on familiar datasets.
The Playground includes data sets chosen to highlight our product’s strengths including transactions, analytics and multi-model capabilities. These data sets include:
- TPC-DS (analytics benchmark)
- TPC-H (transactions benchmark)
- Real-time digital marketing (application interaction)
- JSON data (multi-model)
Already, hundreds of users have run thousands of queries in the Playground, gaining first-hand experience with the performance and speed of SingleStoreDB.
‘Guided tour’ onboarding experience
Previously, users signing into the portal for the first time would need to get started and figure things out by themselves. They couldn’t easily experience or appreciate all of the powerful functionality of SingleStoreDB like streaming data ingestion, unified transaction and analytics, multi-model capabilities and more.
Now, when users first create a workspace on the portal, they’re led to a guided tour of SingleStoreDB by simply checking a box. The tour takes them through a digital marketing use case complete with data sets, a user workflow, assistance on feature use and a look at the analytics in action. Pit stops of the tour include Pipelines, Rowstore and Universal Storage tables, Query Profiling, analytical queries and finally, a web application that runs on the same data users just created.

Wasm now available everywhere
SingleStore Code Engine for Wasm lets you extend SQL with functions written in C, C++ Rust and soon, other languages.

In the summer of 2022, we announced Code Engine, Powered by Wasm. This allowed porting code (as Wasm Modules) into a sandbox in the database. Since the application logic resides right where the data is, loading huge data into the application is no longer needed. What’s more, developers are able to put more energy into their app logic, and less on writing query logic in the app tier.
“The code engine for Wasm in SingleStore is a catalyst for extracting value from our data faster and cheaper by leveraging our enterprise code base in real-time SQL.” — Abel Mascarenhas, IT Unit Manager, Millennium BCP
Previously, this feature was made available in 7.9, a release only available in Singlestore Helios. With 8.0, we’re making this available for Self-Managed deployments as well.
Read more: Bring Application Logic to Your Data With SingleStoreDB Code Engine for Wasm
Documentation: Code Engine — Powered by Wasm
Faster Transactions and Analytics
Seeking speeds up queries by avoiding reading or uncompressing (columnar) data that’s not required for their execution. Using our columnstore (Universal Storage) tables, this is achieved by directly accessing the required data within a segment (containing the rows needed) rather than decoding the entire segment/column.
We’re extending the ability to seek on columnstore to two new areas:
- JSON columns
- String data
Up to 400x faster seeks on JSON columns
With fast seeking for JSON Columns, customers can expect to see significant performance improvements (up to 100x faster) for transactional applications that work with JSON and our Universal Storage table format.
This feature makes SingleStoreDB a more compelling alternative to NoSQL databases such as MongoDB that struggle with real-time analytics and complex queries.
2-3x better throughput on transactions with string data
Previously, our row-level decoding didn’t support certain compressed data (LZ4 or RLE encodings). With this expanded support, we expect customers to get 2-3x performance gains for transactional workloads on such compressed data.
Read more: Universal Storage, Part 5
Disk spilling, now supported for all major query execution operations
Disk spilling is the way SingleStoreDB handles queries requiring more RAM than available (not to be confused with spilling from disk to object storage).
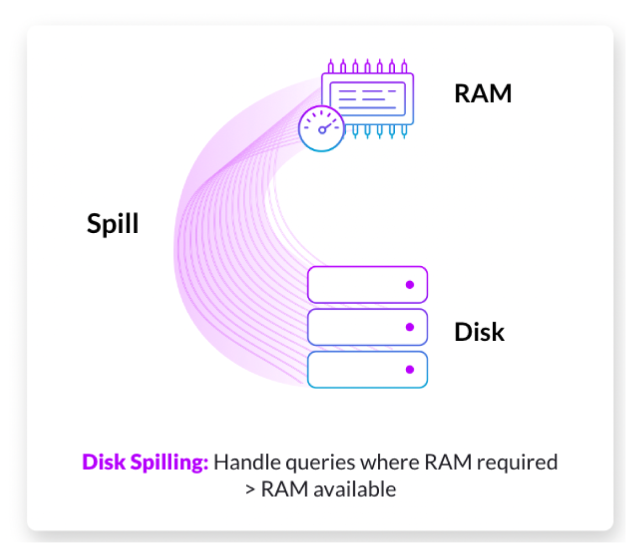
Previously (7.5, 7.8), disk spilling was available for hash group by operations alone. Now, disk spilling support is available for hash join, window and sort functions. All queries now run as expected — even if the resources required are more than available RAM.
A few of our customers, including LiveRamp, were able to fix out-of-memory query issues with certain concurrent analytics scenarios with queries that were previously out-of-memory. With 8.0, the failures completely disappeared.
Cloud Security, Observability and Scaling
Security: Federated authentication with OAuth
Singlestore Helios already supports Single-Sign-On (SSO) via Ping, Okta and Azure Active Directory. Even with these SSO mechanisms, if customers used multiple applications with SingleStoreDB (such as Tableau for analytics and a custom web-based portal) they would still need to authenticate separately in several places. This made for a cumbersome customer experience.
Therefore, most customers today demand some form of federated authentication to provide secure, designated access to multiple applications. The two most popular protocols for federated authentication are SAML (which we already support) and OAuth.
OAuth is very popular for modern application development (web/ mobile/ gaming/ IoT). With 8.0, we are extending support for federated authentication using OAuth on our Cloud service. With OAuth support, users have a simpler authentication mechanism. Additionally, this enables customers to use the new and more secure OpenID Connect (OIDC) protocol.
Scaling: Suspend & resume compute for Workspaces
With support for Suspending & Resuming Compute for Workspaces, customers can instantly suspend workspaces when they are not needed, and resume them when workloads commence. Customers can centrally manage this functionality at scale (e.g. thousands of instances) using our Management API and Portal.
This feature gives customers better control of their costs by avoiding consuming resources they don’t actually need, resulting in lower TCO overall.
This also allows SingleStoreDB to be cost-competitive for intermittent workloads such as batch analytics and cloud-native app development.
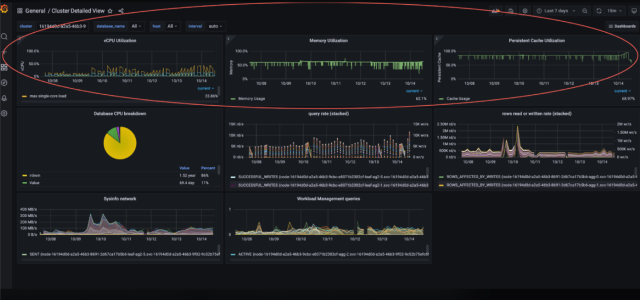
Real-time and historical monitoring
CPU, Memory and Persistent Cache are the fuel that a database engine runs on. Running low on this fuel could slow down the application or analytical workload. Therefore, these three are the first metrics users need to inspect if there’s a problem.
True to our product’s strengths with real-time analytics, we implemented real-time monitoring for these key metrics, which is now available in our portal (see image).

While real-time metrics are fun, historical context is required to diagnose important issues. For instance, customers might want to see how their system behaved during demand surges, and accordingly plan for scaling.
These metrics can be viewed via the Cluster Detailed View Grafana dashboard that is already available out-of-the-box to all our Cloud customers:
Read more: Announcing Real-Time and Historical Monitoring in Singlestore Helios
One more thing… (Actually three. Hat tip, Steve Jobs)
We hope you will take full advantage of all these new features.
- If you’re curious to know what’s coming in the next tool truck, Yatharth Gupta and Shireesh Thota share a sneak peak here in our 8.0 launch event (check out around 33:00).
- If there are more features you’d like to see, please share your ideas on our Forum.
- If you’ve still not tried SingleStoreDB, try it free today.





.png?width=24&disable=upscale&auto=webp)








