

The exploration and utilization of embeddings is a fascinating field within machine learning and data science, and is now an accessible one.
Whether you are an experienced data scientist or just starting your journey in the world of embeddings, this blog post offers a comprehensive guide to creating them at scale using SingleStoreDB.
In this detailed walkthrough, we will be focusing on the integration of OpenAI's text-embedding-ada-002 model, striving to keep our solution as model agnostic and data source independent (still SingleStoreDB 😉) as possible.
I recommend using Visual Studio Code (VS Code) as your development environment for this tutorial. It offers excellent support for Docker, making it easy to manage and organize your files.
We've created a template for this architecture making it super easy for you to replicate these steps and get real-time embeddings on your data. You can access the files in this tutorial through our Github repo.
What you will learn
You’ll start by understanding how to generate embeddings for a specific textual column, diving into the methodologies that allow for optimal representation. You'll explore the most effective ways to insert these embeddings into SingleStoreDB, leveraging the capabilities of the SingleStore Python Client.
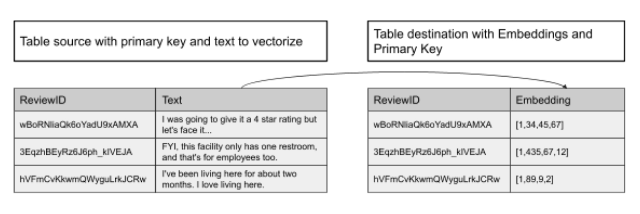
Second, you will learn how to scale up your embedding creation process through a serverless architecture. This section will guide you on how to automatically create embeddings for newly ingested data that lacks existing embeddings in the table. This is a practice that many of our clients are embracing, enabling them to perform semantic searches on their most recent data.
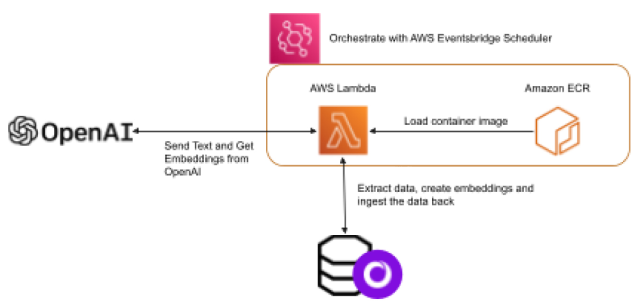
Third, you will learn to make your code both secure and adaptable by applying environment variables to your Lambda functions. You will be guided on how to ensure your code is free of sensitive information like keys and secrets, and how to introduce flexibility by easily changing table sources, destinations or even the model itself.
Finally, you will use a scheduler to automate when and how often your Lambda function will run.
Create your Lambda function
Step 1: Import the required libraries
We'll start by importing essential libraries for accessing OpenAI URLs, reading tables, ingesting embeddings into SingleStoreDB and managing environment variables. Requests libraries will be used to access OpenAI URL, singlestoredb and struct libraries will be used to read tables and ingest efficiently embeddings back into SingleStoreDB; os library will be used to get environment variables within your python script.
#Import libraries
import os
from struct import pack
import requests
import singlestoredb as s2Step 2: List all the variables
These variables will help us set various configurations like limits, tables, connection details and OpenAI model parameters.
limit = int(os.getenv('LIMIT', '10')) # Set a limit on how many rows you want to
read and write back
source_table = os.environ.get('SOURCE_TABLE', 'reviews_yelp') # Set which source
table you want to read data from
source_table_PK= os.environ.get('SOURCE_TABLE_PK', 'review_id') # Set which column
in the source table is the primary key
source_table_text_column = os.environ.get('SOURCE_TABLE_TEXT_COLUMN', 'text') # Set
which column in the source table contains the text that you want to embed
destination_table = os.environ.get('DESTINATION_TABLE', 'reviews_yelp_embedding') #
Set which destination table you will write data into - if that table doesn;t exist,
we create it in the script
db_endpoint = os.environ.get('ENDPOINT', '') # Set the host string to
SingleStoreDB. It should look like svc-XXXX.svc.singlestore.com
connection_port = os.environ.get('CONNECTION_PORT', '3306') # Set the port to
access that endpoint. By default it is 3306
username = os.environ.get('USERNAME', '') # Set the username to access that
endpoint
password = os.environ.get('PASSWORD', '') # Set the password for the username to
access that endpoint
database_name = os.environ.get('DATABASE_NAME', '') # Set the database name you
want to access
API_KEY = os.environ.get('OPENAPI_API_KEY', '') # Set the API Key from OpenAI
EMBEDDING_MODEL = os.environ.get('EMBEDDING_MODEL', '') # Define which OpenAI model
to use
URL_EMBEDDING = os.environ.get('URL', 'https://api.openai.com/v1/embeddings') # URL
to access OpenAI
BATCH_SIZE = os.environ.get('BATCH_SIZE', '2000') # Set how many rows you want to
process per batchStep 3: Configure connections to SingleStoreDB and OpenAI
We will set up two connections to SingleStoreDB for reading and writing, and configure the connection to OpenAI.
fetch_conn = s2.connect(host=db_endpoint, user=username, password = password,
database=database_name)
insert_conn = s2.connect(host=db_endpoint, user=username, password = password,
database=database_name)
#Configure Header and connections
HEADERS = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json',
}Step 4: Writing the core functionality
Extract the data to vectorize
We'll define a handler function to create the destination table if it doesn't exist, and read the source data.
def handler(event, context):
fetch_cur = fetch_conn.cursor()
query_create_table = '''
CREATE TABLE IF NOT EXISTS {} (
{} text, embedding blob, batch_index int, usage_tokens_batch int, timestamp
datetime, model text)'''.format(destination_table,source_table_PK)
fetch_cur.execute(query_create_table)
query_read = 'select {}, {} from {} where {} NOT IN (select {} from {}) limit
%s'.format(source_table_PK,source_table_text_column,
source_table,source_table_PK,source_table_PK, destination_table)
fetch_cur.execute(query_read, (limit,))Create the embeddings
This step involves processing the text column and making calls to the OpenAI endpoint to create embeddings.
fmt = None
while True:
rows = fetch_cur.fetchmany(BATCH_SIZE)
if not rows: break
res = requests.post(URL_EMBEDDING,
headers=HEADERS,
json={'input': [row[1].replace('\n', ' ')
for row in rows],
'model': EMBEDDING_MODEL}).json()
if fmt is None:
fmt = '<{}f'.format(len(res['data'][0]['embedding']))Ingest the embedding
Finally, we'll ingest the embeddings back into the destination table.
insert_embedding = 'INSERT INTO {} ({},
embedding,batch_index,usage_tokens_batch,timestamp,model) VALUES (%s, %s,
%s,%s,now(),%s)'.format(destination_table,source_table_PK)
data = [(row[0], pack(fmt, *ai['embedding']), ai['index'],
res['usage']['total_tokens'], EMBEDDING_MODEL) for row, ai in zip(rows,
res['data'])]
insert_conn.cursor().executemany(insert_embedding, data)Function
This Lambda function sets up a streamlined process for extracting text, creating embeddings and ingesting them back into SingleStoreDB, all orchestrated through a serverless architecture. It demonstrates a practical approach to working with textual data at scale. Here is all the preceding code stitched together. Call that file lambda_function.py.
#Import libraries
import os
from struct import pack
import requests
import singlestoredb as s2
# List the variables
limit = int(os.getenv('LIMIT', '10')) # Set a limit on how many rows you want to
read and write back
source_table = os.environ.get('SOURCE_TABLE', 'reviews_yelp') # Set which source
table you want to read data from
source_table_PK= os.environ.get('SOURCE_TABLE_PK', 'review_id') # Set which column
in the source table is the primary key
source_table_text_column = os.environ.get('SOURCE_TABLE_TEXT_COLUMN', 'text') # Set
which column in the source table contains the text that you want to embed
destination_table = os.environ.get('DESTINATION_TABLE', 'reviews_yelp_embedding') #
Set which destination table you will write data into - if that table doesn;t exist,
we create it in the script
db_endpoint = os.environ.get('ENDPOINT', '') # Set the host string to
SingleStoreDB. It should look like svc-XXXX.svc.singlestore.com
connection_port = os.environ.get('CONNECTION_PORT', '3306') # Set the port to
access that endpoint. By default it is 3306
username = os.environ.get('USERNAME', '') # Set the username to access that
endpoint
password = os.environ.get('PASSWORD', '') # Set the password for the username to
access that endpoint
database_name = os.environ.get('DATABASE_NAME', '') # Set the database name you
want to access
API_KEY = os.environ.get('OPENAPI_API_KEY', '') # Set the API Key from OpenAI
EMBEDDING_MODEL = os.environ.get('EMBEDDING_MODEL', '') # Define which OpenAI model
to use
URL_EMBEDDING = os.environ.get('URL', 'https://api.openai.com/v1/embeddings') # URL
to access OpenAI
BATCH_SIZE = os.environ.get('BATCH_SIZE', '2000') # Set how many rows you want to
process per batch
#Configure Header and connections
HEADERS = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json',
}
fetch_conn = s2.connect(host=db_endpoint, user=username, password = password,
database=database_name)
insert_conn = s2.connect(host=db_endpoint, user=username, password = password,
database=database_name)
# Lambda function
def handler(event, context):
fetch_cur = fetch_conn.cursor()
query_create_table = '''
CREATE TABLE IF NOT EXISTS {} (
{} text, embedding blob, batch_index int, usage_tokens_batch int, timestamp
datetime, model text)'''.format(destination_table,source_table_PK)
fetch_cur.execute(query_create_table)
query_insert = 'INSERT INTO {} SELECT * FROM yelp.reviews_all_v2 ra where ra.{}
NOT IN (select {} from {}) LIMIT
%s'.format(source_table,source_table_PK,source_table_PK, source_table)
fetch_cur.execute(query_insert, (limit,))
query_read = 'select {}, {} from {} where {} NOT IN (select {} from {}) limit
%s'.format(source_table_PK,source_table_text_column,
source_table,source_table_PK,source_table_PK, destination_table)
fetch_cur.execute(query_read, (limit,))
fmt = None
while True:
rows = fetch_cur.fetchmany(BATCH_SIZE)
if not rows: break
res = requests.post(URL_EMBEDDING,
headers=HEADERS,
json={'input': [row[1].replace('\n', ' ')
for row in rows],
'model': EMBEDDING_MODEL}).json()
if fmt is None:
fmt = '<{}f'.format(len(res['data'][0]['embedding']))
insert_embedding = 'INSERT INTO {} ({},
embedding,batch_index,usage_tokens_batch,timestamp,model) VALUES (%s, %s,
%s,%s,now(),%s)'.format(destination_table,source_table_PK)
data = [(row[0], pack(fmt, *ai['embedding']), ai['index'],
res['usage']['total_tokens'], EMBEDDING_MODEL) for row, ai in zip(rows,
res['data'])]
insert_conn.cursor().executemany(insert_embedding, data)Package your files for AWS Lambda and Amazon Elastic Container Registry
When working with AWS Lambda, especially if you need to include larger images containing heavy libraries, it might be beneficial to create a Docker container. This approach enables greater flexibility in managing dependencies, and allows you to work with more extensive packages that may not be suitable for a typical Lambda deployment package.
Follow the official AWS documentation for creating a Python Docker image specifically for AWS Lambda. The guide provides a detailed walkthrough, which you can find here.
In the same folder where your lambda_function.py is located, create a file named requirements.txt. This file will list all the necessary libraries your function depends on — be sure to include any library that your code uses, as this guarantees they are installed within the Docker container.
Here's what the requirements.txt file should contain:
singlestoredb
sqlalchemy_singlestoredbIf you followed the documentation link above, you should also have a Docker file with the following attributes:
FROM public.ecr.aws/lambda/python:3.11
# Copy requirements.txt
COPY requirements.txt ${LAMBDA_TASK_ROOT}
# Copy function code
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
# Install the specified packages
RUN pip install -r requirements.txt
# Set the CMD to your handler (could also be done as a parameter override outside
of the Dockerfile)
CMD [ "lambda_function.handler" ]If you followed the previous documentation link, you should have your image deployed in Amazon Elastic Container Registry (ECR).
Create and configure the Lambda Function
Now you need to create your AWS Lambda function through the AWS console in the AWS Lambda service.
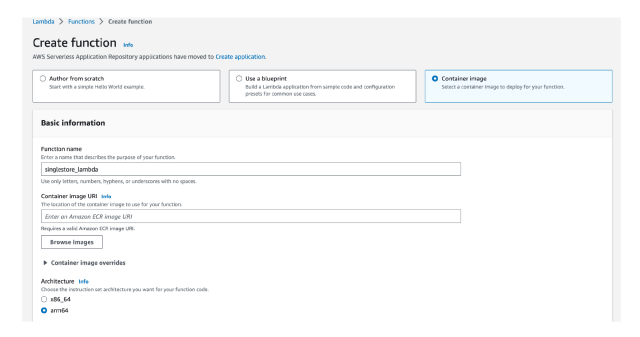
- Select Container image
- Enter the name of your function. I use singlestore_lambda
- Select Browse images
- Select the repository for your image in the dropdown
- Select the image you want. The image you just published should have the image tag latest
- Click on Select image
- If you have developed on ARM (like me on a Mac M1), you should select arm64 over x86_64
- Click on Create function
Now go to the Configuration and do the following:
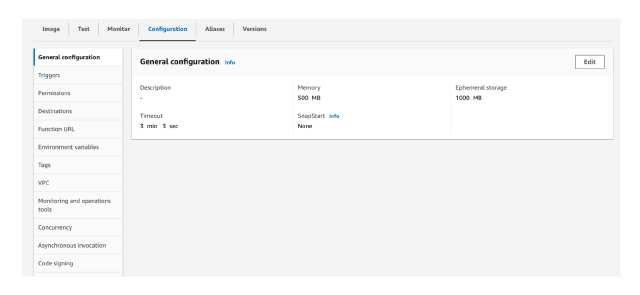
- In the General configuration tab ( if you want to create several embeddings at once), you can tweak the following to increase speed of ingestion:
- Increase Timeout to 1 minute
- Increase Memory to 500 MB
- Go to the Environment variables tab and enter the following — this is where you pass on all the environment variables from lambda_function.py:
| Key | Value |
| USERNAME | Your own entry (oftentime we use admin for trials) |
| PASSWORD | Your username password |
| ENDPOINT | Your SingleStore endpoint svc-XXX-dml.aws-virginia-5.svc.singlestore.com |
| CONNECTION_PORT | 3306 |
| DATABASE_NAME | Your own entry |
| SOURCE_TABLE | Your own entry |
| SOURCE_TABLE_TEXT_COLUMN | Your own entry |
| SOURCE_TABLE_PK | Your own entry |
| DESTINATION_TABLE | Your own entry |
| LIMIT | 1000 (but you can change it if you want to process more text at once) |
| BATCH_SIZE | 2000 (but you can change the size depending on the speed required) |
| URL | https://api.openai.com/v1/embeddings |
| OPENAPI_API_KEY | Your OpenAI API Key |
| EMBEDDING_MODEL | text-embedding-ada-002 |
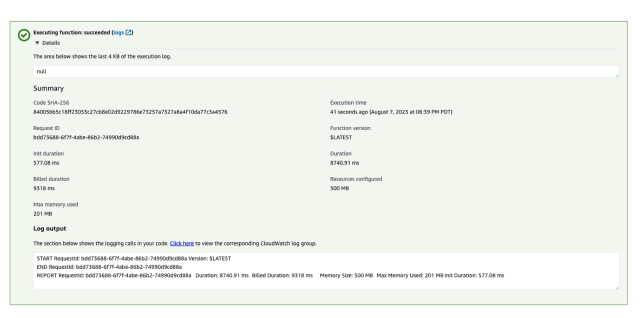
Now go to the Test Tab and click on Test. You should get the following results:
Schedule your function with Amazon EventBridge
On Amazon EventBridge, go to Schedules under Scheduler, create a schedule and do the following:
- Enter a Schedule name
- Under Schedule pattern, enter the following:
- Occurrence: Select Recurring schedule
- Schedule type: Select Rate-based schedule
- Under Rate expression:
- Enter 1 as Value
- Select minutes as Units
- From the Templated targets, select AWS Lambda
- In Invoke, select the lambda function you have created above
- Select Next
- Select Next (no need to change the options)
Your Lambda function will now run every 1 minute.
Wrap-up
So what have we demonstrated here? We have shown how you can operationalize the creation of embeddings against any table in SingleStoreDB using a third- party service likeOpenAI. Behind the scenes, our Python Client makes the ingestion of embeddings simple and super fast.
Try SingleStoreDB for free now!
Additional resources





.png?width=24&disable=upscale&auto=webp)







